







按照吴恩达老师的话讲,反向传播的数学推导过程实际上是他看过的最复杂的数学之一,涉及线性代数 矩阵 导数 链式法则等等,如果你微积分专家,你可以尝试从头进行数学推导,这是机器学习领域最难的推导之一。不管怎样,如果能实现这些方程,相信能让你有足够的直觉来调整神经网络并使其工作。
一、前向传播公式的回顾
Z [ 1 ] = W [ 1 ] X + b [ 1 ] A [ 1 ] = σ ( Z [ 1 ] ) Z [ 2 ] = W [ 2 ] A [ 1 ] + b [ 2 ] A [ 2 ] = σ ( Z [ 2 ] ) Z^{[1]}=W^{[1]}X+b^{[1]}\\A^{[1]}=\sigma(Z^{[1]})\\Z^{[2]}=W^{[2]}A^{[1]}+b^{[2]}\\A^{[2]}=\sigma(Z^{[2]}) Z[1]=W[1]X+b[1]A[1]=σ(Z[1])Z[2]=W[2]A[1]+b[2]A[2]=σ(Z[2])
二、反向传播的梯度下降算法
d z [ 2 ] = A [ 2 ] − y dz^{[2]}=A^{[2]}-y dz[2]=A[2]−y
d w [ 2 ] = 1 m d z [ 2 ] A [ 1 ] T dw^{[2]}=\frac{1}{m} dz^{[2]} {A^{[1]}}^T dw[2]=m1dz[2]A[1]T
d b [ 2 ] = 1 m n p . s u m ( d z [ 2 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{[2]}=\frac{1}{m} np.sum(dz^{[2]}, axis=1, keepdims=True) db[2]=m1np.sum(dz[2],axis=1,keepdims=True)
d z [ 1 ] = w [ 2 ] T d z [ 2 ] ∗ g [ 1 ] ′ ( z [ 1 ] ) dz^{[1]}={w^{[2]}}^Tdz^{[2]}*g^{[1]'}(z^{[1]}) dz[1]=w[2]Tdz[2]∗g[1]′(z[1])
d w [ 1 ] = 1 m d z [ 1 ] X T dw^{[1]}=\frac{1}{m} dz^{[1]}X^T dw[1]=m1dz[1]XT
d b [ 1 ] = 1 m n p . s u m ( d z [ 1 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{[1]}=\frac{1}{m} np.sum(dz^{[1]}, axis=1, keepdims=True) db[1]=m1np.sum(dz[1],axis=1,keepdims=True)
直观理解反向传播
在逻辑回归中,求导的核心是链式法则,很容易得到每一个参数的导数值。
d
a
=
−
y
a
+
1
−
y
1
−
a
da=-\frac{y}{a}+\frac{1-y}{1-a}
da=−ay+1−a1−y
d z = a − y dz=a-y dz=a−y
d w = x d z dw=xdz dw=xdz
d b = d z db=dz db=dz

在一个隐藏层的神经网络中,其实是重复了两次逻辑回归,那么应该如何求得梯度?
下图中紫色框为6个核心公式,红色框为
d
z
[
1
]
dz^{[1]}
dz[1]的维度检查。
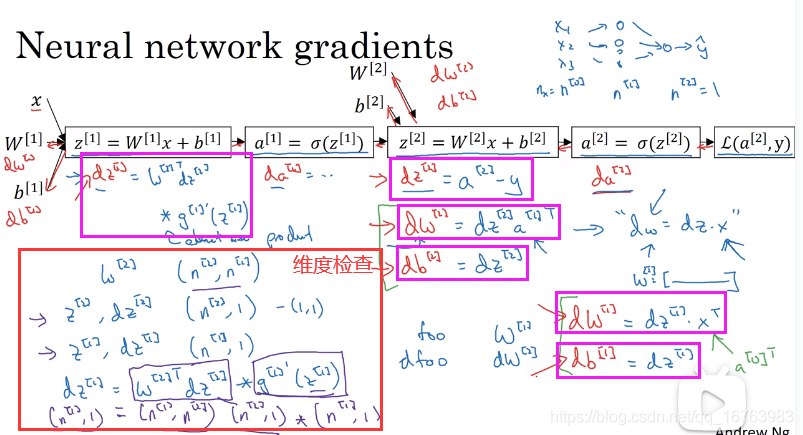
事实上,训练的数据同样是多个样本(将向量以列堆积,在公式中的体现是小写变量名改大写),所以总结一下反向传播的计算公式。

















 3701
3701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











