







一、为什么不能初始化权重为0?
来看一个简单的网络结构
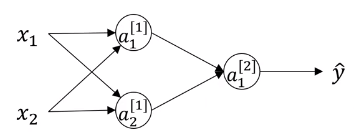
试想如果权重初始化为0,即
W [ 1 ] = [ 0 0 0 0 ] . W^{[1]}=\left[ \begin{matrix} 0&0\\0&0\end{matrix} \right]. W[1]=[0000].
a
1
[
1
]
=
a
2
[
2
]
,
d
z
1
[
1
]
=
d
z
2
[
2
]
a_1^{[1]}=a_2^{[2]},dz_1^{[1]}=dz_2^{[2]}
a1[1]=a2[2],dz1[1]=dz2[2]
因此特征值通过每一个神经元时输出值先相同,不管有多少个神经元,有多少次迭代,多个神经元仍然在计算完全相同的函数,这种情况下多个隐藏单元实在没有必要。
问题的解决方案就是随机初始化所有参数。
二、随机初始化
W
[
1
]
=
n
p
.
r
a
n
d
o
m
.
r
a
n
d
n
(
(
2
,
2
)
)
×
0.01
W^{[1]}=np.random.randn((2,2))\times 0.01
W[1]=np.random.randn((2,2))×0.01
b [ 1 ] = n p . z e r o ( ( 2 , 1 ) ) b^{[1]}=np.zero((2,1)) b[1]=np.zero((2,1))
W [ 2 ] = n p . r a n d o m . r a n d n ( ( 1 , 2 ) ) × 0.01 W^{[2]}=np.random.randn((1,2))\times 0.01 W[2]=np.random.randn((1,2))×0.01
b [ 2 ] = 0 b^{[2]}=0 b[2]=0
注意:在初始化第一层权重值时,乘上0.01是希望得到一个较小的数,以防训练开始时
z
,
a
z,a
z,a值过大导致
t
a
n
h
tanh
tanh梯度过小。乘上0.01这个数在我们这个浅层神经网络适用,但是不代表在深层神经网络都适用,所以在更深的网络中,我们会考虑其他值。
不管怎样,我们总是期望较小的初始化参数。
三、参数VS超参数
首先说明一下,参数和超参数是在深层神经网络的最后一课,但是这个知识点并不适合单独写成一篇笔记,并且我认为该概念放在前面讲解有利于大家区分之后的一些概念,所以我把参数和超参数的说明放在这一篇笔记(参数随机初始化)的末尾。
在之前的学习中,没有区分参数与超参数这两个概念,我将
w
,
b
,
α
w,b,\alpha
w,b,α这样的变量或常量统一称作参数。但事实上是有区别的,
w
,
b
w,b
w,b称作参数是因为它们收到其他量的影响。而
α
\alpha
α,迭代次数,momentum,正则化参数,mini_batch这样一些量称作超参数,是因为这些量可以由我们预设值,可以根据经验去调整。
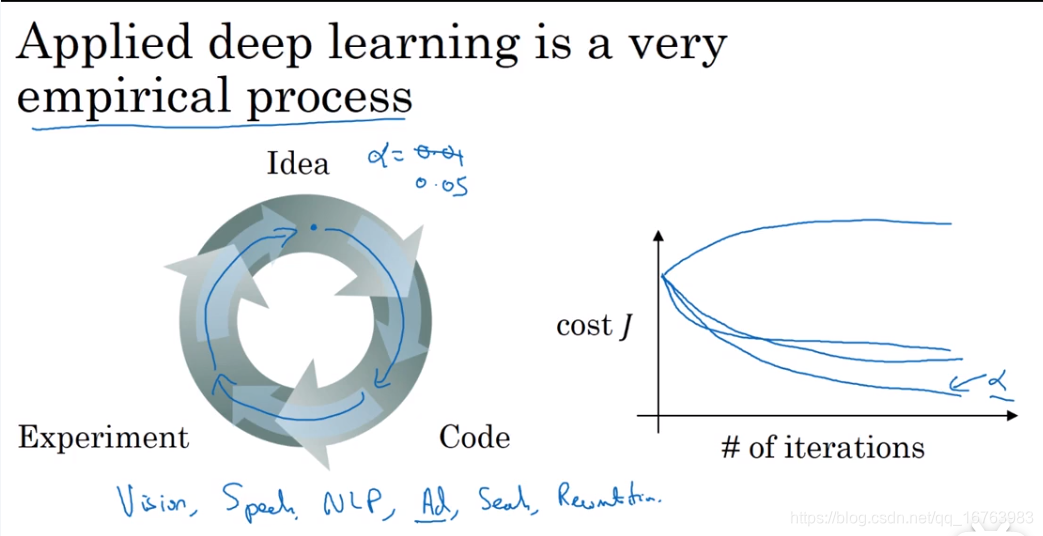
其实超参数的选择就是一项非常经验性的工作,通常根据已有经验,我们在一定的范围内对不同的超参数进行尝试,选择相对最好的超参数。在不同应用领域,在不同应用时代,这些超参数的选取常常会改变。对超参数的选取就是不断尝试,迭代优化这样一个过程。
写到这篇笔记时,算是到达一个里程碑了——正式结束浅层神经网络这一章。在之前的笔记中我总结了吴恩达老师课程的深度学习概论、逻辑回归算法、浅层神经网络。
学习了设立单隐层神经网络—初始化参数—正向传播计算预测值—>计算导数—>梯度下降算法—>反向传播修正参数
接下来的学习,将进入深层神经网络以及更复杂的参数调整算法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











