






 本文深入解析了机器学习中model.fit函数的validation_split参数作用。它用于从训练集中划分出一部分作为验证集,此集不在训练过程中使用,而是在每个epoch结束后评估模型性能,确保模型泛化能力。特别提醒,划分前应先对数据进行shuffle,避免因数据顺序导致验证集样本不均衡。
本文深入解析了机器学习中model.fit函数的validation_split参数作用。它用于从训练集中划分出一部分作为验证集,此集不在训练过程中使用,而是在每个epoch结束后评估模型性能,确保模型泛化能力。特别提醒,划分前应先对数据进行shuffle,避免因数据顺序导致验证集样本不均衡。
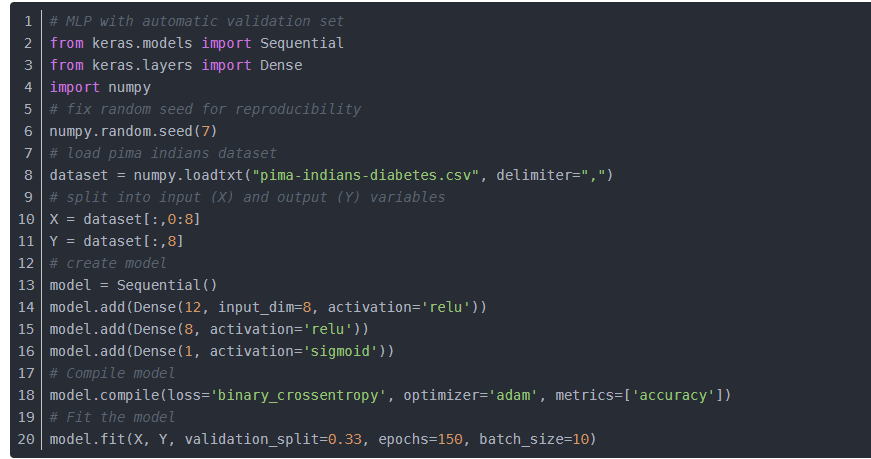
model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10)
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。
注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10)
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。
注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
 1060
2493
6080
386
1060
2493
6080
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























