







一、前言
eBPF目前被广泛应用于Linux系统中的各个领域,包括网络、安全、性能、调测等。其中,内核trace算是eBPF比较早所支持的特性。最早的用于内核trace的eBPF类型当属BPF_PROG_TYPE_KPROBE,即kprobe机制提供的对eBPF的支持,使得eBPF程序可以以内核函数动态插桩的方式来进行内核trace。随着时代的发展,目前可用于trace的eBPF类型和能够实现的功能也越来越丰富,包括tracepoint、raw_tracepint、tracing等eBPF类型。那么内核提供的这些eBPF类型的实现和用途有什么区别,适用于哪些场景呢?我们来一探究竟。
二、kprobe
2.1 eBPF的加载
kprobe是Linux内核中的动态插桩功能,可以在内核函数开始、结束和中间位置进行动态插桩,从而实现调测、跟踪的目的。kprobe对于eBPF的支持是通过perf来实现的,其加载和挂载的流程如下图所示:
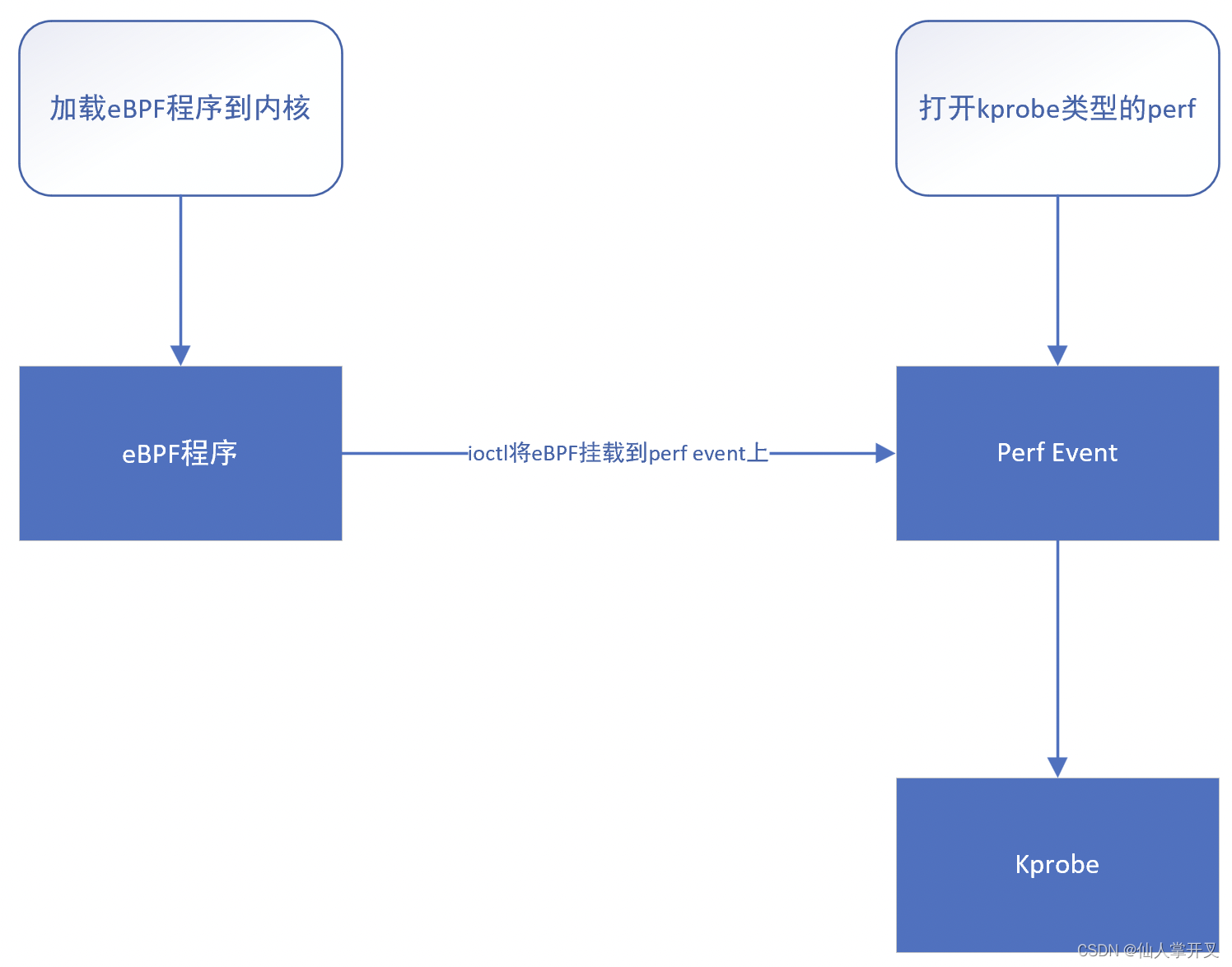
从流程图中可以看出来,实质上是perf模块对eBPF的支持使得eBPF可以使用kprobe的功能。perf模块本身是可以使用kprobe的功能的,其可以基于kprobe来进行事件采样。通过ioctl系统调用,使用PERF_EVENT_IOC_SET_BPF命令,可以将eBPF程序挂载到打开的perf实例上。该挂载过程的函数调用链为:perf_event_set_bpf_prog → perf_event_attach_bpf_prog,其过程还是比较简单的:
- 通过传递过来的eBPF的fd句柄和perf_event的fd句柄,分别找到对应的eBPF实例prog和perf_event实例event
- 检查eBPF程序的合法性,包括当前的perf_event与eBPF程序是否兼容
- 将prog设置到event->prog上即可。
从这里可以看出,一个perf实例上只能挂载一个eBPF程序(但是同一个内核函数可以被多个perf实例插桩)。
2.2 eBPF的执行
在perf模块,kprobe实例的创建过程的调用链为:perf_kprobe_event_init → perf_kprobe_init → create_local_trace_kprobe → alloc_trace_kprobe。在alloc_trace_kprobe函数中,可以看到kprobe的处理函数为kprobe_dispatcher:
if (is_return)
tk->rp.handler = kretprobe_dispatcher;
else
tk->rp.kp.pre_handler = kprobe_dispatcher;
而kprobe_dispatcher的处理流程也很简单,它会取出当前event上加载的bpf_prog_array,并执行数组中所有的eBPF程序。执行的时候,它把pt_regs的指针作为参数传递给了eBPF程序,因此对于kprobe类型的eBPF程序,我们拿到的参数是指向寄存器结构体的指针。
kprobe类型的eBPF程序的检查器钩子函数定义如下:
const struct bpf_verifier_ops kprobe_verifier_ops = {
.get_func_proto = kprobe_prog_func_proto,
.is_valid_access = kprobe_prog_is_valid_access,
};
在eBPF程序加载期间会调用kprobe_prog_is_valid_access来对eBPF指令中的对于ctx(传递给eBPF程序的参数,这里是指向寄存器结构体的指针)的内存访问进行合法性检查:
static bool kprobe_prog_is_valid_access(int off, int size, enum bpf_access_type type,
const struct bpf_prog *prog,
struct bpf_insn_access_aux *info)
{
/*
* off为访问偏移。这里限制只能读取 pt_regs 结构体范围内的数据
*/
if (off < 0 || off >= sizeof(struct pt_regs))
return false;
/* 访问类型为只读(不能写寄存器) */
if (type != BPF_READ)
return false;
/* 访问的数据要是对齐的。 */
if (off % size != 0)
return false;
/*
* Assertion for 32 bit to make sure last 8 byte access
* (BPF_DW) to the last 4 byte member is disallowed.
*/
if (off + size > sizeof(struct pt_regs))
return false;
return true;
}
2.3 eBPF的使用
kprobe类型的eBPF程序是基于perf来实现的,perf在采集到注册的kprobe事件后会调用挂载在自己身上的eBPF程序,并将regs指针传过去。eBPF程序里可以访问regs里的数据,通过PT_REGS_PARMx()宏定义可以从regs中取出被插桩的函数的参数,简单是示例如下所示:
SEC("kprobe/kfree_skb")
int bpf_prog(struct pt_regs *ctx)
{
/* 取出kfree_skb函数的第一个参数 */
struct sk_buff *skb = (void *)PT_REGS_PARM1(ctx);
int len;
bpf_probe_read_kernel(&len, sizeof(len), skb->len);
return 0;
}
虽然我们能够直接读取ctx里的数据,但是在kprobe类型的eBPF程序里我们并不能直接读取skb里的内容。这是因为内核要保证eBPF程序运行的安全性,避免非法(无效)内存访问的发生,而内核并不知道skb指向的内存是否有效。因此在eBPF里,访问内存需要使用特定的helper函数,即bpf_probe_read_kernel来进行内存的读取。该helper函数会默认源指针的内容不安全,并关闭当前进程的pagefault,即使用copy_from_kernel_nofault来进行内存的拷贝。
static __always_inline int
bpf_probe_read_kernel_common(void *dst, u32 size, const void *unsafe_ptr)
{
int ret = security_locked_down(LOCKDOWN_BPF_READ);
if (unlikely(ret < 0))
goto fail;
ret = copy_from_kernel_nofault(dst, unsafe_ptr, size);
if (unlikely(ret < 0))
goto fail;
return ret;
fail:
memset(dst, 0, size);
return ret;
}
由此可见,这种eBPF的缺点就在于:
- 使用繁琐,需要从寄存器中来取出被trace函数的参数
- 基于perf来实现,效率低
- 无法直接内存读取,需要先用helper拷贝到栈里
优点在于其能够在函数中间插桩跟踪。
三、tracepoint
3.1 加载与执行
tracepoint类型的eBPF程序与kprobe类似,都是基于perf来实现的。perf在注册tracepoint的时候的调用链为:perf_tp_event_init → perf_trace_init → perf_trace_event_init → perf_trace_event_reg → trace_event_reg → tracepoint_probe_register,从tracepoint_probe_register中可以看出perf用来处理ftrace的回调函数是直接取的trace_event_class上定义的的perf_probe函数,而这个函数是使用下面的宏定义来定义的:
#define DECLARE_EVENT_CLASS(call, proto, args, tstruct, assign, print) \
static notrace void \
perf_trace_##call(void *__data, proto) \
{ \
struct trace_event_call *event_call = __data; \
struct trace_event_data_offsets_##call __maybe_unused __data_offsets;\
/* 这里的entry用来存放ftrace的参数,也就是tracepoint里定义的field */
struct trace_event_raw_##call *entry; \
struct pt_regs *__regs; \
u64 __count = 1; \
struct task_struct *__task = NULL; \
struct hlist_head *head; \
int __entry_size; \
int __data_size; \
int rctx; \
\
/* 这里获取到的是当前的tracepoint的动态字段的长度。比如定义为string的
* 字段都是动态字段,这个函数可以计算出所有动态字段长度的总和。
*/
__data_size = trace_event_get_offsets_##call(&__data_offsets, args); \
\
head = this_cpu_ptr(event_call->perf_events); \
if (!bpf_prog_array_valid(event_call) && \
__builtin_constant_p(!__task) && !__task && \
hlist_empty(head)) \
return; \
\
__entry_size = ALIGN(__data_size + sizeof(*entry) + sizeof(u32),\
sizeof(u64)); \
__entry_size -= sizeof(u32); \
\
/* 根据计算出来的尺寸来分配entry的内存 */
entry = perf_trace_buf_alloc(__entry_size, &__regs, &rctx); \
if (!entry) \
return; \
\
/* 获取寄存器数据 */
perf_fetch_caller_regs(__regs); \
\
tstruct \
\
/* 用来将传递给tracepoint的值设置到entry上(entry的初始化) */
{ assign; } \
\
perf_trace_run_bpf_submit(entry, __entry_size, rctx, \
event_call, __count, __regs, \
head, __task); \
}
从上面的代码可以看出,ftrace会将tracepoint的参数封装到struct trace_event_raw_##call这个结构体上,而这个结构体就是我们在定义tracepoint时使用TP_STRUCT__entry定义的用于数据传递的结构体。以kfree_skb为例,其定义如下所示:
TRACE_EVENT(kfree_skb,
TP_PROTO(struct sk_buff *skb, void *location),
TP_ARGS(skb, location),
/* 这里定义了trace_event_raw_kfree_skb,其可以等价于:
* struct trace_event_raw_kfree_skb {
* void *regs;
* void *skbaddr;
* void *location;
* unsigned short protocol;
* };
*/
TP_STRUCT__entry(
__field( void *, skbaddr )
__field( void *, location )
__field( unsigned short, protocol )
),
TP_fast_assign(
__entry->skbaddr = skb;
__entry->location = location;
__entry->protocol = ntohs(skb->protocol);
),
TP_printk("skbaddr=%p protocol=%u location=%p",
__entry->skbaddr, __entry->protocol, __entry->location)
);
最终,内核会调用perf_trace_run_bpf_submit来执行当前perf实例上的eBPF程序,并将这里构造的entry作为ctx传递给eBPF程序。
3.2 eBPF程序的使用
从这里可以看出来,在eBP程序里我们需要获取tracepoint的参数的话,需要按照同样的结构体格式来访问entry里的数据。而entry的数据结构,我们是可以通过tracepoint的format来查看到的,这里还是以kfree_skb为例:
# cat /sys/kernel/debug/tracing/events/skb/kfree_skb/format
name: kfree_skb
ID: 1407
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1;signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:void * skbaddr; offset:8; size:8; signed:0;
field:void * location; offset:16; size:8; signed:0;
field:unsigned short protocol; offset:24; size:2; signed:0;
field:enum skb_drop_reason reason; offset:28; size:4; signed:0;
print fmt: "skbaddr=%p protocol=%u location=%p reason: %s", REC->skbaddr, REC->protocol, REC->location, drop_reasons[REC->reason]
在tracepoint的format输出里,format中描述的就是entry结构体。前8个字节都是统一的进程相关的信息,跳过8个字节后才是我们的tracepoint的参数。所以对于kfree_skb,我们的eBPF程序要这么写:
struct args_kfree_skb {
void *regs;
void *skbaddr;
void *location;
unsigned short protocol;
};
SEC("tracepoint/skb/kfree_skb")
int trace_kfree_skb(struct args_kfree_skb *args)
{
bpf_printk("skbaddr:%llx\n", args->skbaddr);
return 0;
}
在进行内存访问的时候,tracepoint类型的eBPF程序和kprobe类型是一样的,都是要通过bpf_probe_read_kernel等helper函数来将内存拷贝到栈里才能读取。在挂载eBPF程序的时候,内核也会对eBPF程序对于入参(上文中的args)的内存访问进行合法性检查,即访问的内存偏移不能超过当前tracepoint的entry的长度。这个是在perf_event_set_bpf_prog → trace_event_get_offsets来实现的:
if (is_tracepoint || is_syscall_tp) {
/* 获取当前event的entry的最大长度,判断eBPF程序对于entry的访问
* 是否超过了最大偏移量。
*/
int off = trace_event_get_offsets(event->tp_event);
if (prog->aux->max_ctx_offset > off) {
bpf_prog_put(prog);
return -EACCES;
}
}
四、raw_tracepoint
BPF_PROG_TYPE_RAW_TRACEPOINT类型的eBPF程序是基于perf来实现的,在使用过程中其存在一定的缺陷,主要表现在以下几方面:
- 使用不方便。eBPF程序为了获取到tracepoint的参数,需要按照format文件里的格式定义一个匹配的结构体来访问,过程比较繁琐,很不友好
- 依赖于perf模块,在perf处理过程中存在一定的性能损耗
为了解决以上问题,raw_tracepoint(原始tracepoint)特性由Alexei引入到了内核中。下面我们来分析一下其实现原理和基本的使用方法。
4.1 raw_tp加载与执行
基于perf的tracepoint是先创建perf实例,再将eBPF程序挂载到perf实例上,perf会将采集到的tracepoint数据传递给eBPF程序。而raw_tracepoint(下面简称raw_tp)不一样,它不需要依赖其他模块,而是直接注册eBPF模块的处理函数到ftrace中。首先我们来理解一下raw_tp的内核实现过程,内核会调用下面的宏定义为每个tracepoint在固定的section创建一个struct bpf_raw_event_map实例,这个实例存储了挂载eBPF程序所需要的一些tracepoint上的元数据,包括当前tracepoint的参数的数量(num_args)、指向tracepoint实例的指针(tp)、用来处理tracepoint事件的函数bpf_func等。其中,内核还会为每个tracepoint创建一个对应的eBPF程序入口函数____bpf_trace_xx,后面注册到ftrace子系统中的正是这个入口函数,因此这里我们需要重点了解一下这个函数干了什么。
#define __DEFINE_EVENT(template, call, proto, args, size) \
static inline void bpf_test_probe_##call(void) \
{ \
check_trace_callback_type_##call(__bpf_trace_##template); \
} \
typedef void (*btf_trace_##call)(void *__data, proto); \
static union { \
struct bpf_raw_event_map event; \
btf_trace_##call handler; \
} __bpf_trace_tp_map_##call __used \
__section("__bpf_raw_tp_map") = { \
.event = { \
.tp = &__tracepoint_##call, \
.bpf_func = __bpf_trace_##template, \
.num_args = COUNT_ARGS(args), \
.writable_size = size, \
}, \
};
入口函数的定义过程如下所示,其定义过程很简单:
#define DECLARE_EVENT_CLASS(call, proto, args, tstruct, assign, print) \
static notrace void \
__bpf_trace_##call(void *__data, proto) \
{ \
struct bpf_prog *prog = __data; \
/* 经过一些列的处理后下面的宏定义会被展开为:
* bpf_trace_runx(prog, (u64)args[0], ..., (u64)args[x - 1]),其中x为当前tracepoint的参数的个数
*/
CONCATENATE(bpf_trace_run, COUNT_ARGS(args))(prog, CAST_TO_U64(args)); \
}
/* bpf_trace_runx的定义过程 */
#define BPF_TRACE_DEFN_x(x) \
void bpf_trace_run##x(struct bpf_prog *prog, \
REPEAT(x, SARG, __DL_COM, __SEQ_0_11)) \
{ \
/* 创建一个长度为x的数组,并将所有的参数拷贝到数组中,然后将数组指针
* 作为context传递给eBPF程序。
*/
u64 args[x]; \
REPEAT(x, COPY, __DL_SEM, __SEQ_0_11); \
__bpf_trace_run(prog, args); \
} \
EXPORT_SYMBOL_GPL(bpf_trace_run##x)
为了将eBPF程序挂载到ftrace上,bpf系统调用引入了新的命令BPF_RAW_TRACEPOINT_OPEN,即将eBPF程序按照常规的方式加载到内核后,使用该命令即可将eBPF程序挂载到指定的tracepoint上。内核会调用bpf_raw_tracepoint_open函数来完成eBPF程序的挂载,如下所示:
static int bpf_raw_tracepoint_open(const union bpf_attr *attr)
{
struct bpf_link_primer link_primer;
struct bpf_raw_tp_link *link;
struct bpf_raw_event_map *btp;
struct bpf_prog *prog;
const char *tp_name;
char buf[128];
int err;
if (CHECK_ATTR(BPF_RAW_TRACEPOINT_OPEN))
return -EINVAL;
prog = bpf_prog_get(attr->raw_tracepoint.prog_fd);
if (IS_ERR(prog))
return PTR_ERR(prog);
[......]
if (strncpy_from_user(buf,
u64_to_user_ptr(attr->raw_tracepoint.name),
sizeof(buf) - 1) < 0) {
err = -EFAULT;
goto out_put_prog;
}
[......]
/* 根据名称进行raw_tracepoint的查找。找到对应的btp后,将该btp注册到
* 对应event的钩子函数中,并把prog的地址作为私有参数,以备后续使用。
*
* 查找过程是遍历btp所在的section,从中找到name与tp_name相同的btp实例。
*/
btp = bpf_get_raw_tracepoint(tp_name);
if (!btp) {
err = -ENOENT;
goto out_put_prog;
}
[......]
/* 将prog注册当当前btp对应的tracepoint上。注册的时候,会检查当前eBPF程序
* 对于context的访问有没有超过当前tracepoint的上限,即不大于
* btp->num_args * sizeof(u64)
*/
err = bpf_probe_register(link->btp, prog);
if (err) {
bpf_link_cleanup(&link_primer);
goto out_put_btp;
}
return bpf_link_settle(&link_primer);
out_put_btp:
bpf_put_raw_tracepoint(btp);
out_put_prog:
bpf_prog_put(prog);
return err;
}
至此,raw_tp的内核实现基本上就完成了。由此可见,raw_tp的实现过程并不复杂。
4.2 raw_tp的使用
raw_tp和普通的tracepoint在使用上唯一的不同在于对context的访问。tracepoint传递给eBPF程序的是一个有个固定数据结构的entry,而raw_tp传过去的是一个u64的数组。下面依然以kfree_skb为例来看一下raw_tp是如何使用的:
SEC("raw_tp/kfree_skb")
int trace_kfree_skb(u64 *args)
{
struct sk_buff *skb = (void *) args[0];
void *location = (void *) args[1];
return 0;
}
可以看出来,我们可以直接将context作为一个u64的数组来进行访问,从中取出tracepoint的参数,而不用关心参数的类型、长度等。借助libbpf提供的一些帮助函数,我们可以进一步简化eBPF程序的编写:
SEC("raw_tp/kfree_skb")
int BPF_PROG(kfree_skb, struct sk_buff *skb, void *location)
{
return 0;
}
BPF_PROG这个宏定义会将这段代码展开成上面的形式。
五、tracing
BPF_PROG_TYPE_TRACING是一种较新的eBPF程序类型。之所以叫TRACING,是因为这个eBPF特性以一种统一的模式对kprobe、tracepoint等用于内核trace的功能进行了重新实现。从上面的分析中可以看出,现有的trace类型的eBPF程序存在以下问题:
- 在进行内存访问时,必须通过helper函数进行拷贝后才能访问(tracepoint和kprobe都有这个问题)
- 各个trace类型的eBPF程序获取参数的方式都不一样,不利于统一的用户编码
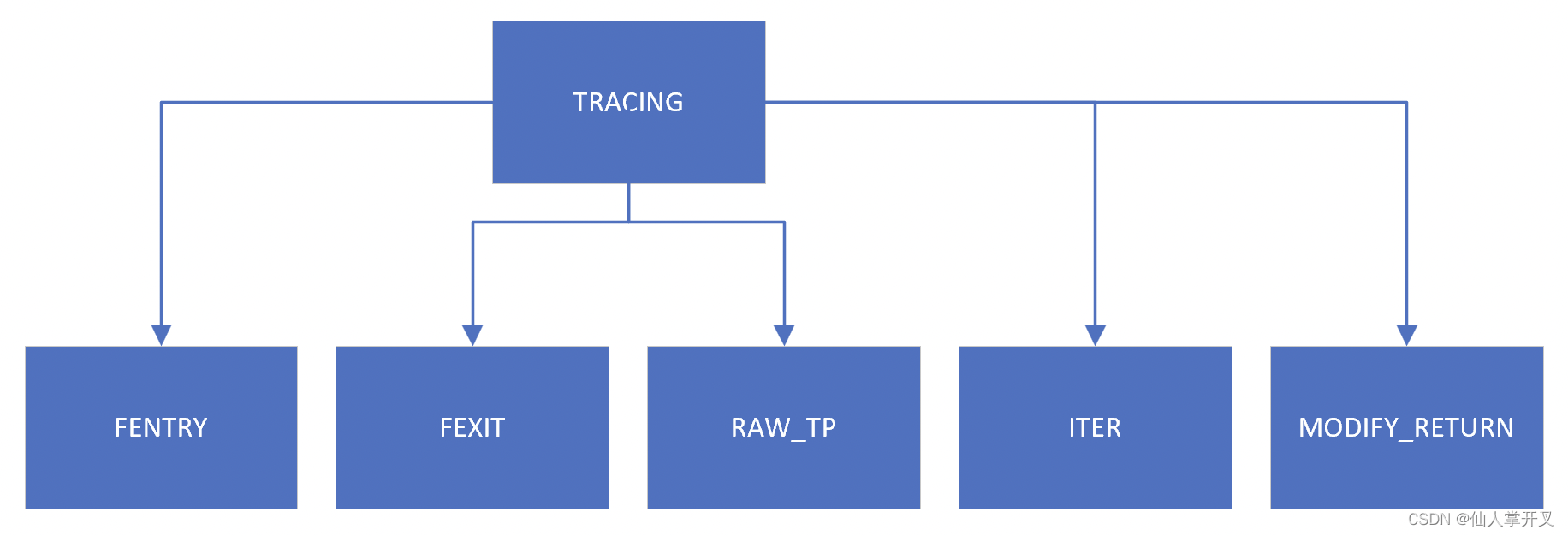
TRACING类型的eBPF程序解决了以上的问题。同样的eBPF程序,通过在挂载的时候指定不同的挂载类型,就可以实现不同的功能。目前TRACING支持以下四种挂载类型,分别是:
RAW_TP:与上文的raw_tracepoint类似,用于跟踪tracepoint的FENTRY:跟踪进入内核函数(类似于kprobe)FEXIT: 跟踪内核函数退出(类似kreprobe)。需要注意的是,这个比kreprobe更强大,因为这里可以获取到函数的入参ITER: eBPF迭代器MODIFY_RETURN:用于修改被插桩(跟踪)函数的返回值,同时跳过被跟踪内核函数的执行
5.1 tracing的使用
首先我们来通过一个简单的使用案例来看一下tracing类型的eBPF程序在使用的时候和kprobe或者tracepoint到底有哪些区别。下面是一个用来跟踪kfree_skb这个tracepoint事件的eBPF代码:
SEC("tp_btf/kfree_skb")
int BPF_PROG(trace_kfree_skb, struct sk_buff *skb, void *location)
{
u16 proto;
/* 没有使用probe函数来进行内存的拷贝,而是直接进行内存的读取 */
proto = skb->protocol;
bpf_printk("protocol of skb is: %d\n", (int)bpf_ntohs(proto));
return 0;
}
可以看出来tracing类型的eBPF程序在写法上简单了很多,对于内核函数/tracepoint的指针类型的参数可以直接读取对应的内存。除了在内存访问方面的区别,tracing类型的eBPF也支持更多的特性,比如通过FEXIT挂载类型可以实现与kreprobe相同的功能,且能够获取到被跟踪函数的入参(这一点是kreprobe所做不到的):
SEC("fexit/netif_receive_skb_core")
int BPF_PROG(netif_receive_skb_core, struct sk_buff *skb, int ret)
{
u16 proto;
/* ret为内核函数netif_receive_skb_core的返回值。fexit类型的eBPF程序,
* 会将函数返回值放到所有函数入参的后面。netif_receive_skb_core的入参
* 只有skb一个,因此后面就是函数返回值。
*/
/* 没有使用probe函数来进行内存的拷贝,而是直接进行内存的读取 */
proto = skb->protocol;
bpf_printk("protocol of skb is: %d, ret is: %d\n",
(int)bpf_ntohs(proto), ret);
return 0;
}
5.2 eBPF的加载
下面我们来分析一下内核在实现TRACING功能的代码实现。由于各种挂载类型在加载过程中的内核检查流程类似,因此这里以RAW_TP为例来分析内核实现eBPF程序的“直接”内存访问的。从上面的raw_tracepoint的内核加载过程,我们可以看出来内核是根据tracepoint的名称来查找到对应的tracepoint,并挂载上去的。TRACING类型的eBPF程序相比于其他trace类型的eBPF程序主要有以下两方面区别:
- TRACING类型的eBPF程序是基于BTF的,在加载eBPF程序到内核的时候需要指定目标所对应的的BTF的ID(关于BTF的内容这里不再赘述)
- eBPF程序里,可以通过指针直接访问内存,不再需要bpf_probe_read_kernel等helper函数
那么问题来了:运行eBPF程序直接访问内存,内核如何避免非法内存访问的发生?下面我们来揭秘一下内核是如何通过内存检查来实现这一过程的。
5.2.1 目标BTF
首先我们来看一下BTF对于tracepoint的支持。BTF是一种用来保存内核中所使用的类型(结构体、枚举、函数等)的一种数据结构,其以一定的格式存储在内核中,并通过/sys/kernel/btf/vmlinux暴露给用户使用,且每个BTF都有一个与之对应的唯一的ID。内核为每个tracepoint都通过typedef创建了一个函数指针类型btf_trace_xx,这里称其为原型函数:
#define __DEFINE_EVENT(template, call, proto, args, size) \
static inline void bpf_test_probe_##call(void) \
{ \
check_trace_callback_type_##call(__bpf_trace_##template); \
} \
typedef void (*btf_trace_##call)(void *__data, proto); \
static union { \
struct bpf_raw_event_map event; \
btf_trace_##call handler; \
} __bpf_trace_tp_map_##call __used \
__section("__bpf_raw_tp_map") = { \
.event = { \
.tp = &__tracepoint_##call, \
.bpf_func = __bpf_trace_##template, \
.num_args = COUNT_ARGS(args), \
.writable_size = size, \
}, \
};
以kfree_skb为例,上面的宏定义会创建以下原型函数:
typedef void (*btf_trace_kfree_skb)(void *__data, struct sk_buff *skb, void *location, unsigned short protocol);
在加载eBPF程序到内核的时候,libbpf会解析/sys/kernel/btf/vmlinux文件来找到btf_trace_kfree_skb对应的BTF的ID,并将其作为attach_btf_id参数传递给内核。
5.2.2 内存检查
在了解内核对于TRACING类型的eBPF进行的内存检查之前,我们需要熟悉一下内核中BTF的表示方式。内核使用struct btf_type来存储、表示内核中的struct、enum、typedef、function等结构,其定义如下所示:
struct btf_type {
/* 当前类型的名称在符号表中的偏移量,通过btf_name_by_offset可以将这个偏移
* 转为字符串。
*/
__u32 name_off;
/*
* 有多重用途:
* - 0-15位:用于记录当前类型的成员数量。对于结构体,其保存了结构体中字段的个数;
* 对于函数,其记录了函数的参数的个数等。
* - 24-27位:记录了当前BTF的类型,代表的是结构体,还是枚举,还是函数等。
* - 31位:标志位,不同的类型有不同的用途。
*/
__u32 info;
/*
* 如果当前类型是INT, ENUM, STRUCT, UNION 或者 DATASEC,那么size会被
* 使用,代表的是当前类型的长度(以字节为单位)。
*
* 如果当前类型是PTR, TYPEDEF, VOLATILE, CONST, RESTRICT,
* FUNC, FUNC_PROTO 或者 VAR,那么type会被使用。这时,type代表的是当前
* 类型所关联的类型的id。比如当前类型是个“int *”(指针),那么type存储的
* 就是类型int的BTF的id。
*/
union {
__u32 size;
__u32 type;
};
};
下面我们以上文5.1章节中的tp_btf为例来分析一下内核的检查流程。在加载eBPF程序的时候,libbpf会从/sys/kernel/btf/vmlinux文件中解析出来typedef void (*btf_trace_kfree_skb)(void *__data, struct sk_buff *skb, void *location, unsigned short protocol)这个类型的BTF的ID,并作为attach_btf_id参数传递给内核。在以下代码路径,内核会进行BTF类型的检查和初始化:
bpf_prog_load → bpf_check → check_attach_btf_id → bpf_check_attach_target
int bpf_check_attach_target(struct bpf_verifier_log *log,
const struct bpf_prog *prog,
const struct bpf_prog *tgt_prog,
u32 btf_id,
struct bpf_attach_target_info *tgt_info)
{
bool prog_extension = prog->type == BPF_PROG_TYPE_EXT;
const char prefix[] = "btf_trace_";
int ret = 0, subprog = -1, i;
const struct btf_type *t;
bool conservative = true;
const char *tname;
struct btf *btf;
long addr = 0;
/* 该函数用于TRACING类型的eBPF的target检查。它会检查当前eBPF程序要加载
* 到的目标(tracepoint、内核函数等)的类型是否合法。
*/
if (!btf_id) {
bpf_log(log, "Tracing programs must provide btf_id\n");
return -EINVAL;
}
btf = tgt_prog ? tgt_prog->aux->btf : btf_vmlinux;
if (!btf) {
bpf_log(log,
"FENTRY/FEXIT program can only be attached to another program annotated with BTF\n");
return -EINVAL;
}
/* 根据attach_btf_id找到对应的btf_type */
t = btf_type_by_id(btf, btf_id);
if (!t) {
bpf_log(log, "attach_btf_id %u is invalid\n", btf_id);
return -EINVAL;
}
/* 获取目标的名称(对于raw_tp,这里会是btf_trace_xxx) */
tname = btf_name_by_offset(btf, t->name_off);
if (!tname) {
bpf_log(log, "attach_btf_id %u doesn't have a name\n", btf_id);
return -EINVAL;
}
[......]
switch (prog->expected_attach_type) {
case BPF_TRACE_RAW_TP:
if (tgt_prog) {
bpf_log(log,
"Only FENTRY/FEXIT progs are attachable to another BPF prog\n");
return -EINVAL;
}
/* RAW_TP的目标必须是typedef类型,且以btf_trace_开头的 */
if (!btf_type_is_typedef(t)) {
bpf_log(log, "attach_btf_id %u is not a typedef\n",
btf_id);
return -EINVAL;
}
if (strncmp(prefix, tname, sizeof(prefix) - 1)) {
bpf_log(log, "attach_btf_id %u points to wrong type name %s\n",
btf_id, tname);
return -EINVAL;
}
/* 跳过前缀btf_trace_,获取到真正的tracepoint的名称 */
tname += sizeof(prefix) - 1;
/* 进行BTF上级查找,即typedef原始的类型,这里应该是函数指针 */
t = btf_type_by_id(btf, t->type);
if (!btf_type_is_ptr(t))
/* should never happen in valid vmlinux build */
return -EINVAL;
/* 从函数指针类型再次进行上级查找,获取到函数的btf_type */
t = btf_type_by_id(btf, t->type);
if (!btf_type_is_func_proto(t))
/* should never happen in valid vmlinux build */
return -EINVAL;
break;
[......]
}
tgt_info->tgt_addr = addr;
tgt_info->tgt_name = tname;
tgt_info->tgt_type = t;
return 0;
}
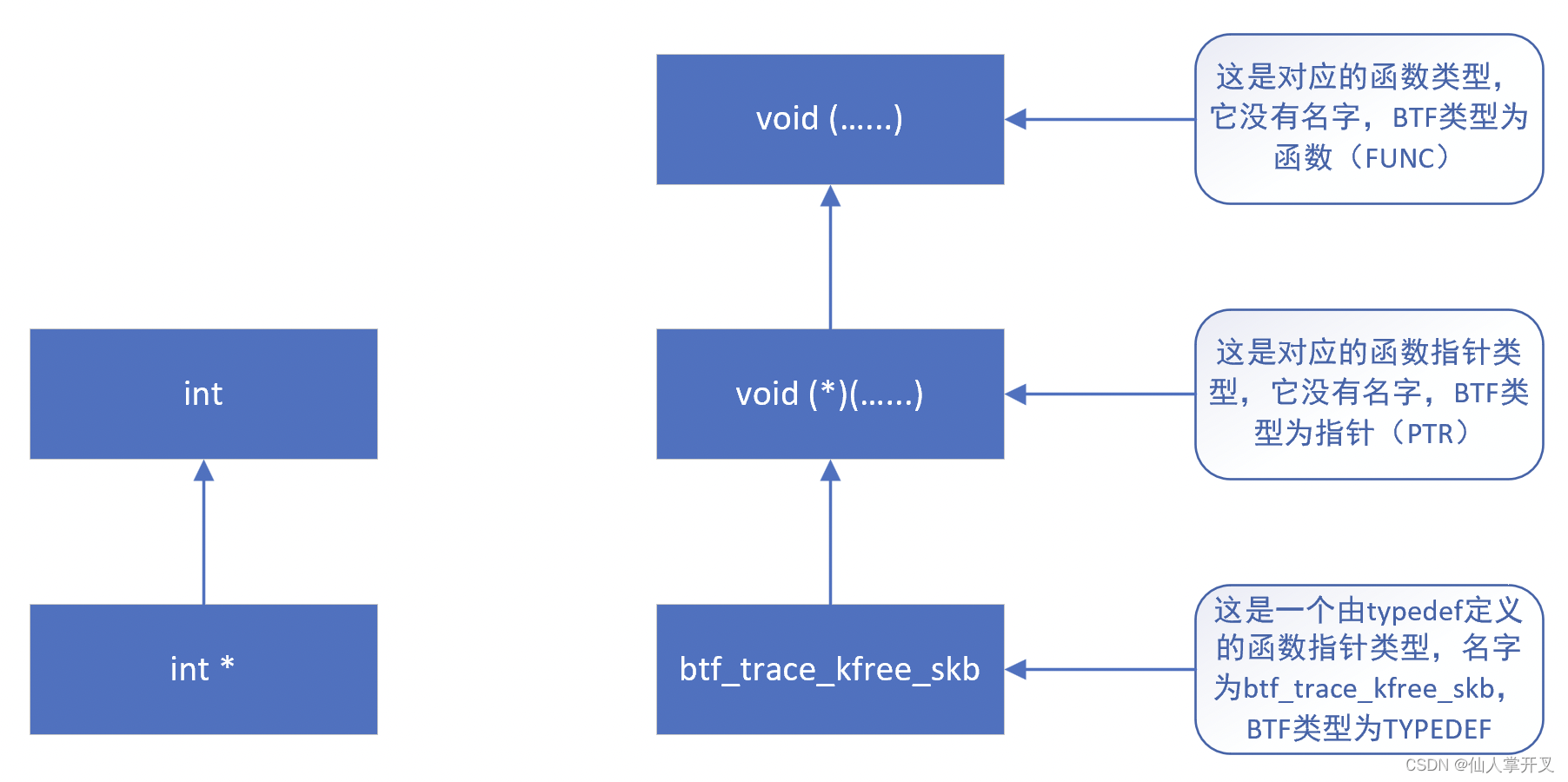
上面的代码,首先根据用户传递的btf_id找到对应的btf_type实例,并判断实例是否合法。比如对于raw_tp类型的tracing程序,其btf_type的类型必须是typedef,并且名称要以btf_trace_开头。其次,它通过找到的btf_type,找到对应的函数的btf_type。这里需要对BTF的格式做一些说明,像指针、typedef等这种类型,是存在“上级”类型的。上文通过typedef定义了一个函数指针btf_trace_kfree_skb,那么这个类型的上级就是函数指针,而函数指针的上级则是其指向的函数。因此上面的代码第一次通过t = btf_type_by_id(btf, t->type)找到的是函数指针,类型是指针;第二次才找到真正的目标函数对应的btf_type实例,逻辑如下图所示:
找到了目标的btf_type实例,内核接下来就可以对整个eBPF程序的内存访问进行合法性检查了。从上面raw_tracepoint的内核分析我们可以知道,内核传递给tracing类型的eBPF程序的context指针指向的是一个u64的数组,数组中存放着内核函数/tracepoint的入参。而内核是在下面的代码路径中来检查和初始化eBPF指令对于context的访问的:
bpf_prog_load → bpf_check → do_check_main → do_check_common → do_check → check_mem_access → check_ctx_access → tracing_prog_is_valid_access → btf_ctx_access
可以说btf_ctx_access是内存检查的关键,这里需要再讲解一下BTF的一些结构细节。struct btf_type用于表示内核中所有的类型,那么以结构体为例,它是怎么表示结构体中有哪些字段的呢?请看下图:
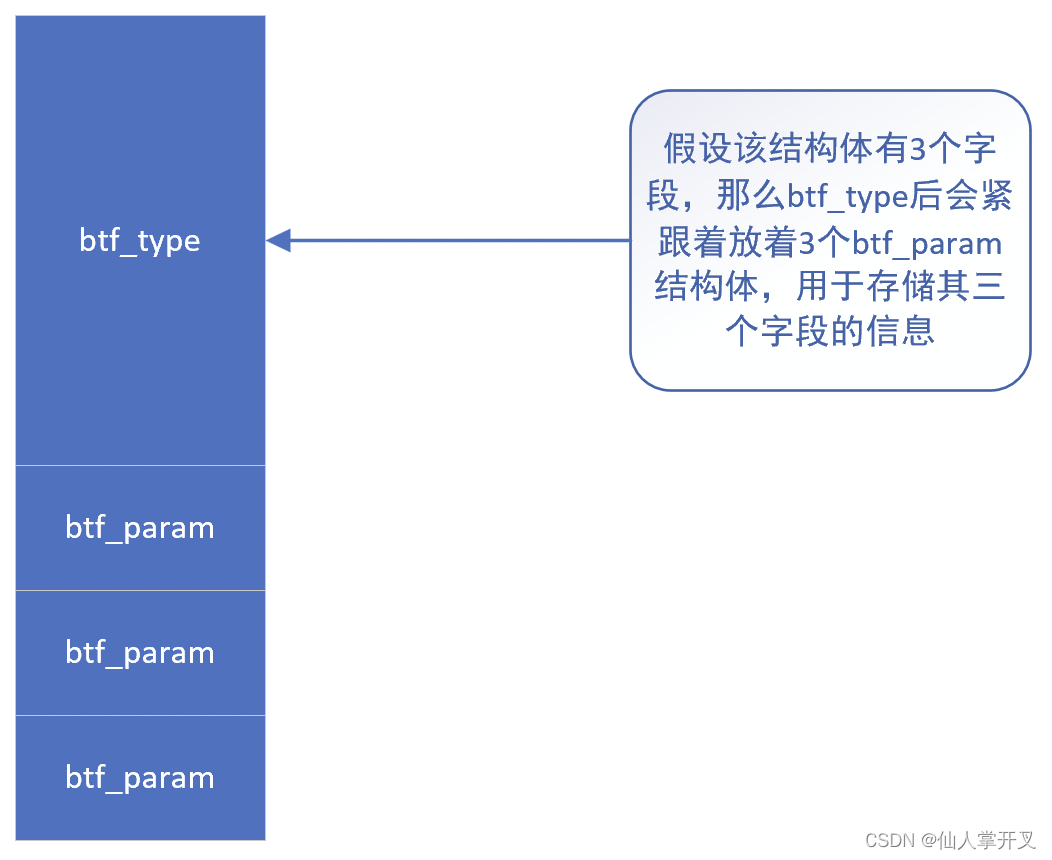
内核函数也类似,通过内核函数对应的btf_type,可以获取到函数所有的参数信息。这么来看,btf_ctx_access所做的事情就比较简单了,无非就是通过对context指针访问的偏移量来找到对应的参数的数据类型,并检查其是否合法:
bool btf_ctx_access(int off, int size, enum bpf_access_type type,
const struct bpf_prog *prog,
struct bpf_insn_access_aux *info)
{
const struct btf_type *t = prog->aux->attach_func_proto;
struct bpf_prog *tgt_prog = prog->aux->dst_prog;
struct btf *btf = bpf_prog_get_target_btf(prog);
const char *tname = prog->aux->attach_func_name;
struct bpf_verifier_log *log = info->log;
const struct btf_param *args;
u32 nr_args, arg;
int i, ret;
/* tracing类型的eBPF程序用来检查和转换context内存访问的函数。 */
/* 由于context的类型的u64[],因此访问的偏移量必须是8的整数倍(以u64为单位进行访问) */
if (off % 8) {
bpf_log(log, "func '%s' offset %d is not multiple of 8\n",
tname, off);
return false;
}
/* 计算出当前访问的是第几个参数 */
arg = off / 8;
/* args指向函数/tracepoint参数数组 */
args = (const struct btf_param *)(t + 1);
/* 获取目标函数的参数个数 */
nr_args = t ? btf_type_vlen(t) : 5;
/* 如果当前的类型是raw_tp,那么跳过目标函数的第一个参数,因为目标函数(比如
* btf_trace_kfree_skb)的第一个参数并不是tracepoint的参数,而是
* void *__data,从第二个参数开始才是。
*/
if (prog->aux->attach_btf_trace) {
/* skip first 'void *__data' argument in btf_trace_##name typedef */
args++;
nr_args--;
}
/* eBPF程序访问context的偏移量超过了当前函数的参数长度,非法访问 */
if (arg > nr_args) {
bpf_log(log, "func '%s' doesn't have %d-th argument\n",
tname, arg + 1);
return false;
}
/* 尝试访问第n+1个参数。这对于某些加载类型是有意义的,比如FEXIT会把函数返回值
* 放到第n+1个参数中。
*/
if (arg == nr_args) {
switch (prog->expected_attach_type) {
case BPF_LSM_MAC:
case BPF_TRACE_FEXIT:
if (!t)
return true;
t = btf_type_by_id(btf, t->type);
break;
case BPF_MODIFY_RETURN:
if (!t)
return false;
t = btf_type_skip_modifiers(btf, t->type, NULL);
if (!btf_type_is_small_int(t)) {
bpf_log(log,
"ret type %s not allowed for fmod_ret\n",
btf_kind_str[BTF_INFO_KIND(t->info)]);
return false;
}
break;
default:
bpf_log(log, "func '%s' doesn't have %d-th argument\n",
tname, arg + 1);
return false;
}
} else {
if (!t)
/* Default prog with 5 args */
return true;
/* 找到当前要访问的参数的btf_type类型 */
t = btf_type_by_id(btf, args[arg].type);
}
/* 跳过修饰器,找到背后真正的类型。像TYPEDEF、CONST这种属于是修饰器,
* 要跳过TYPEDEF,找到真正的(结构体)类型。
*/
while (btf_type_is_modifier(t))
t = btf_type_by_id(btf, t->type);
/* 如果当前参数的类型是整形或者是枚举类型,那么必定是可以访问的,而且不需要
* 做什么特殊的处理。
*/
if (btf_type_is_small_int(t) || btf_type_is_enum(t))
/* accessing a scalar */
return true;
/* 除去整形和枚举,剩下的也就是指针类型了。如果当前参数类型不是指针,那么
* 就是非法访问(内核中应该还没有哪个函数直接把结构体作为参数来传参)。
*/
if (!btf_type_is_ptr(t)) {
bpf_log(log,
"func '%s' arg%d '%s' has type %s. Only pointer access is allowed\n",
tname, arg,
__btf_name_by_offset(btf, t->name_off),
btf_kind_str[BTF_INFO_KIND(t->info)]);
return false;
}
[......]
/* 下面的代码会把btf信息(包括btf_id)设置到info,从而传递给这个函数的调用者 */
info->reg_type = PTR_TO_BTF_ID;
[......]
info->btf_id = t->type;
t = btf_type_by_id(btf, t->type);
/* 跳过修饰器 */
while (btf_type_is_modifier(t)) {
info->btf_id = t->type;
t = btf_type_by_id(btf, t->type);
}
if (!btf_type_is_struct(t)) {
bpf_log(log,
"func '%s' arg%d type %s is not a struct\n",
tname, arg, btf_kind_str[BTF_INFO_KIND(t->info)]);
return false;
}
bpf_log(log, "func '%s' arg%d has btf_id %d type %s '%s'\n",
tname, arg, info->btf_id, btf_kind_str[BTF_INFO_KIND(t->info)],
__btf_name_by_offset(btf, t->name_off));
return true;
}
5.2.3 传播性
上面的内存检查解释了eBPF程序是如何实现直接从context来访问context里存放的函数参数的,但是依然无法解释为何能够直接访问指针里的数据,甚至是从内存中读取出来的指针指向的数据?比如下面的代码是可以正常工作的:
SEC("tp_btf/kfree_skb")
int BPF_PROG(trace_kfree_skb, struct sk_buff *skb, void *location)
{
struct sock *sk;
u16 proto;
int buf;
/* 没有使用probe函数来进行内存的拷贝,而是直接进行内存的读取 */
proto = skb->protocol;
sk = skb->sk;
buf = sk->sk_rcvbuf;
bpf_printk("protocol of skb is: %d, sk receive buf is: %d\n",
(int)bpf_ntohs(proto),
buf);
return 0;
}
可以看出来,eBPF程序不光可以直接读取skb里的数据,还能够直接读取sk里的数据。想要知道内核的实现过程,首先要简单了解内核检查器的一些基本原理,比如寄存器类型。eBPF检查器在检查期间,会记录每个寄存器的状态,包括寄存器中存储的数据”类型“。enum bpf_reg_type用于表示寄存器存储数据的类型,比如:
SCALAR_VALUE:任意类型PTR_TO_CTX:指向context的指针PTR_TO_STACK:指向栈里的数据的指针PTR_TO_PACKET:指向报文数据的指针PTR_TO_BTF_ID:指向BTF(结构体)的指针
下面我们从寄存器的角度来分析一下内存访问的时候的状态变化。上面的代码首先会通过struct sk_buff *skb = (struct sk_buff *)(u64)ctx[0]来从context中读取指针skb,这个代码说生成的指令的示意图如下所示:
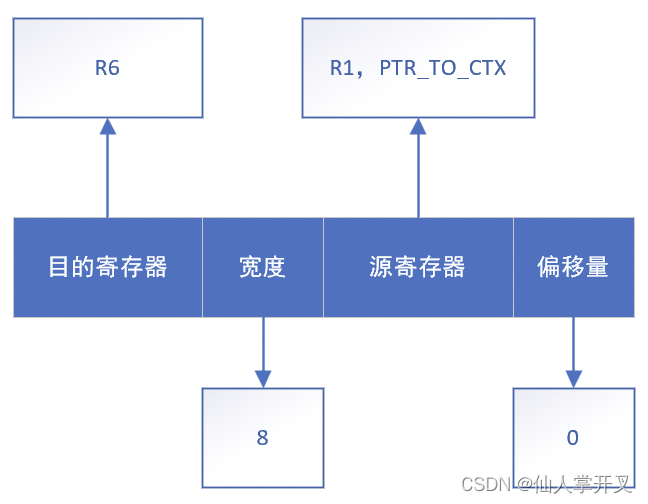
这条指令会通过5.2.2中的代码路径调用btf_ctx_access来进行合法性检查,在检查通过后会将查询到的BTF信息返回,并在check_mem_access被设置到目的寄存器中:
err = check_ctx_access(env, insn_idx, off, size, t, ®_type, &btf_id);
if (err)
verbose_linfo(env, insn_idx, "; ");
if (!err && t == BPF_READ && value_regno >= 0) {
/* 将check_ctx_access返回的reg_type设置到目的寄存器中。
* 如果reg_type是PTR_TO_BTF_ID,那么将获取到的btf_id
* 也设置到目的寄存器中。
*/
if (reg_type == SCALAR_VALUE) {
mark_reg_unknown(env, regs, value_regno);
} else {
mark_reg_known_zero(env, regs,
value_regno);
if (reg_type_may_be_null(reg_type))
regs[value_regno].id = ++env->id_gen;
/* A load of ctx field could have different
* actual load size with the one encoded in the
* insn. When the dst is PTR, it is for sure not
* a sub-register.
*/
regs[value_regno].subreg_def = DEF_NOT_SUBREG;
if (reg_type == PTR_TO_BTF_ID ||
reg_type == PTR_TO_BTF_ID_OR_NULL)
regs[value_regno].btf_id = btf_id;
}
regs[value_regno].type = reg_type;
}
因此,上面的指令执行过后,寄存器的状态会变成下图所示:
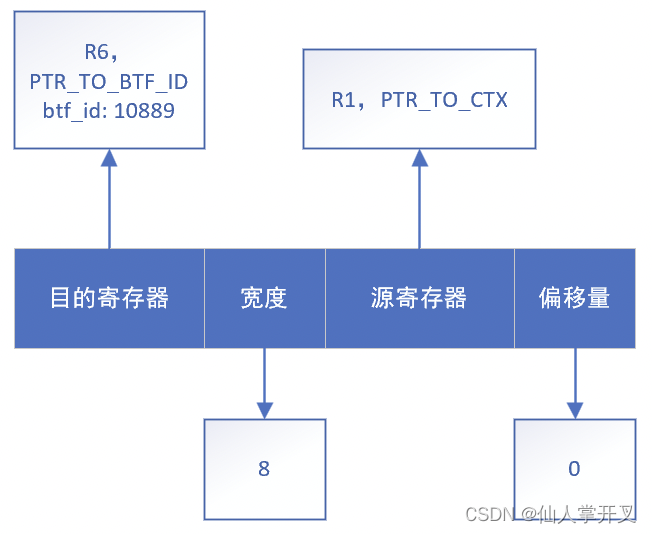
而代码sk = skb->sk;所生成的指令如下图所示:
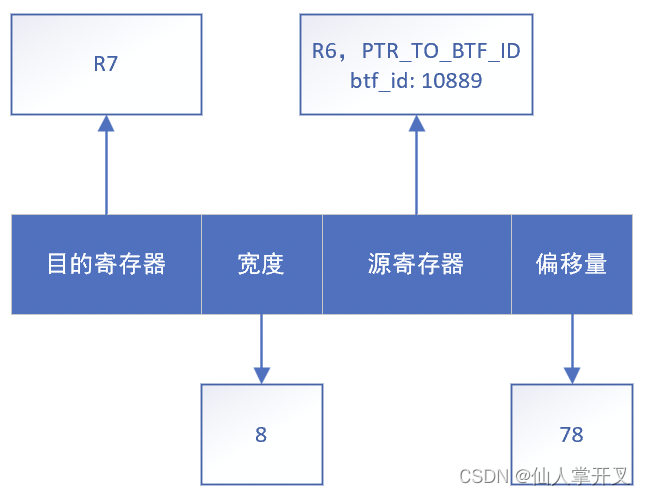
这条指令在进行内存检查的时候,会进入到下面的代码路径中:
bpf_prog_load → bpf_check → do_check_main → do_check_common → do_check → check_mem_access → check_ptr_to_btf_access
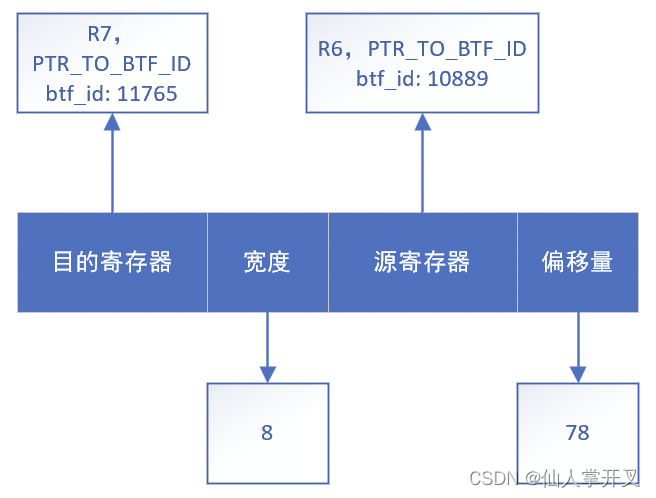
其中check_ptr_to_btf_access会检查对skb->sk的访问是否合法,主要的检查逻辑是:先通过源寄存器中的btf_id找到对应的结构体,然后检查偏移量是否在struct sk_buff内,保证内存访问没有越界。同时,根据偏移量找到对应的字段,获取该字段的类型的BTF信息,并设置到R7寄存器中。指令执行完后,寄存器的状态就会变成:
通过这种检查方式,会以递归的方式检查所有指令对内存的访问。这里需要说明一点,就是内核中是通过BTF信息来确认寄存器(变量)类型的,因此在eBPF程序里使用类型转换是行不通的,比如struct tcp_sock *tcp = (struct tcp_sock *)skb->sk,然后尝试tcp的一些属性。这里,内核依然会把tcp当做指向struct sock的指针来进行检查。
5.2.4 probe指令
内核虽然通过BTF信息来对eBPF程序的内存访问进行了检查,但是依然无法避免非法内存访问的出现。以上面的代码为例,如果skb->sk为空,或者由于skb->sk没有被初始化而指向了一块随机的内存,那么对其进行的访问就会出现pagefault异常。因此对PTR_TO_BTF_ID的访问,内核还是需要保证其不会发生pagefault。所有对BTF进行的内存读取的指令,内核都会在以下代码路径对其进行替换:
bpf_prog_load → bpf_check → do_check_main → do_check_common → do_check → convert_ctx_accesses
convert_ctx_accesses是用来转换内存访问的函数,例如这个函数会把TC类型的eBPF程序里对struct __sk_buff *类型的context的访问转为对skb报文的直接访问。对于tracing程序,这里会遍历所有的指令,并把所有的读取BTF的指令由原来的BPF_LDX | BPF_MEM | SIZE替换成BPF_LDX | BPF_PROBE_MEM | SIZE,即将普通的内存读取指令替换成PROBE版本的指令:
case PTR_TO_BTF_ID:
if (type == BPF_READ) {
insn->code = BPF_LDX | BPF_PROBE_MEM |
BPF_SIZE((insn)->code);
env->prog->aux->num_exentries++;
} else if (resolve_prog_type(env->prog) != BPF_PROG_TYPE_STRUCT_OPS) {
verbose(env, "Writes through BTF pointers are not allowed\n");
return -EINVAL;
}
continue;
对于PROBE指令,eBPF解释器和JIT会做不同的处理。对于没有启用JIT的系统,内核会调用___bpf_prog_run函数解释运行eBPF程序的指令。对于PROBE指令,解释器会调用helper函数bpf_probe_read_kernel()来进行内存的读取。从这里看,解释器模式下除了方便用户编码,内存读取的方式并没有发生本质的变化。
#define LDX_PROBE(SIZEOP, SIZE) \
LDX_PROBE_MEM_##SIZEOP: \
bpf_probe_read_kernel(&DST, SIZE, (const void *)(long) (SRC + insn->off)); \
CONT;
LDX_PROBE(B, 1)
LDX_PROBE(H, 2)
LDX_PROBE(W, 4)
LDX_PROBE(DW, 8)
以x86为例,在JIT模式下,JIT模块会将PROBE指令转换成普通的x86内存加载指令,同时为当前指令在bpf_prog->aux->extable异常表中创建一个实例:
case BPF_LDX | BPF_MEM | BPF_B:
case BPF_LDX | BPF_PROBE_MEM | BPF_B:
case BPF_LDX | BPF_MEM | BPF_H:
case BPF_LDX | BPF_PROBE_MEM | BPF_H:
case BPF_LDX | BPF_MEM | BPF_W:
case BPF_LDX | BPF_PROBE_MEM | BPF_W:
case BPF_LDX | BPF_MEM | BPF_DW:
case BPF_LDX | BPF_PROBE_MEM | BPF_DW:
emit_ldx(&prog, BPF_SIZE(insn->code), dst_reg, src_reg, insn->off);
if (BPF_MODE(insn->code) == BPF_PROBE_MEM) {
struct exception_table_entry *ex;
u8 *_insn = image + proglen;
s64 delta;
if (!bpf_prog->aux->extable)
break;
if (excnt >= bpf_prog->aux->num_exentries) {
pr_err("ex gen bug\n");
return -EFAULT;
}
ex = &bpf_prog->aux->extable[excnt++];
delta = _insn - (u8 *)&ex->insn;
if (!is_simm32(delta)) {
pr_err("extable->insn doesn't fit into 32-bit\n");
return -EFAULT;
}
ex->insn = delta;
delta = (u8 *)ex_handler_bpf - (u8 *)&ex->handler;
if (!is_simm32(delta)) {
pr_err("extable->handler doesn't fit into 32-bit\n");
return -EFAULT;
}
ex->handler = delta;
if (dst_reg > BPF_REG_9) {
pr_err("verifier error\n");
return -EFAULT;
}
ex->fixup = (prog - temp) | (reg2pt_regs[dst_reg] << 8);
}
break;
这里需要说明一下extable的用途。当内存访问发送pagefault的时候,内核会尝试进行异常修复,代码路径为:
exc_page_fault → handle_page_fault → do_kern_addr_fault → bad_area_nosemaphore → __bad_area_nosemaphore → no_context → fixup_exception
这里重点看一下fixup_exception这个函数。这个函数会尝试根据当前产生pagefault的指令地址进行exception_table_entry(就是我们上面往异常表中加的实例)的查找,当查找到后调用上面的handler方法,对于eBPF程序就是ex_handler_bpf函数。这个函数的实现很简单,就是把目的寄存器的值设置为0,也就是说在TRACING类型的eBPF程序里如果发生了非法内存访问,那么读取的内容就是0:
static bool ex_handler_bpf(const struct exception_table_entry *x,
struct pt_regs *regs, int trapnr,
unsigned long error_code, unsigned long fault_addr)
{
u32 reg = x->fixup >> 8;
/* jump over faulting load and clear dest register */
*(unsigned long *)((void *)regs + reg) = 0;
regs->ip += x->fixup & 0xff;
return true;
}
从这里可以看出,经过JIT后TRACING类型的eBPF在内存访问的便捷性和效率上已经达到了内核的水平。虽然频繁的pagefault会影响性能,但是经过检查器使用BTF进行验证后,发生pagefault的可能性已经变得很低了。
六、总结
本文以5.10版本的内核为例,介绍了当前内核中常用的用于内核trace的eBPF程序的使用方法和内核实现,包括kprobe/tracepoint/tracing。除此之外,内核中还有很多基于trace实现的eBPF功能,比如LSM、ITER、STRUCT_OPS等,介于篇幅限制这里不再一一介绍。

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









