






文章目录
结构


一、MPI基本函数
1、完成MPI程序初始化,通过获取main函数的参数,让每一个MPI进程都获取到main的函数
MPI_Init(NULL,NULL)
或
MPI_Init(int *argc,char ***argv)
2、获取调用进程在给定的通信域中的进程标识号
MPI_Comm_rank(MPI_Comm comm, int *rank)
3、获取当前通信域中的进程个数
MPI_Comm_size(MPI_Comm comm,int *size)
4、MPI程序的最后一个调用,清除全部MPI环境
MPI_Finalize()
5、MPI组的管理
MPI_Group
MPI_COMM_WORLD
二、MPI数据结构

三、点对点通信

MPI_Send(void *buff,int count,MPI_Datatype datatype,int dest,int tag, MPI_Comm comm)
MPI_Recv( void *buff, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
| void *buff | 发送的消息变量指针**/**接收变量保存位置 |
|---|---|
| int count | 发送/接收消息的个数(不是长度) |
| MPI_Datatype datatype | 发送/接收消息的MPI数据类型 |
| int dest | 目的进程号 |
| int source | 源进程号(MPI_ANY_SOURCE) |
| int tag | 消息标签(发送和接受要相同,或者MPI_ANY_TAG) |
| MPI_Comm comm | 通信域 |
| MPI_Status *status | 状态 |
注意count:不是长度,例如你要发送一个int整数,这里就填写1,如要是发送“hello”字符串,这里就填写6(C语言中字符串未有一个结束符,需要多一位)。它是接收数据长度的上界. 具体接收到的数据长度可通过调用**MPI_Get_count **函数得到。
MPI环境异常退出
MPI_Abort(comm,errorcode)
–comm 通信域
–errorcode 返回到嵌套环境的错误码

死锁

此时进程0和进程1都在等待对方发送消息
缓存模式

MPI申请缓冲区:
MPI_Buffer_attach(buffer,size)
--buffer 初始缓存地址(可选数据类型)
--size 按字节计数的缓存大小
MPI释放缓冲区
MPI_Buffer_detach(buffer,size)
--buffer 缓冲区初始地址
--size 字节为单位的缓冲区大小
void bsend_test()
{
int rank = 0;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
char str[MSG_SIZE] = { 0 };
sprintf(str, "use bsend hello i'm rank %d", rank);
int strsize = strlen(str);
int bsize = 0;
MPI_Pack_size(strsize, MPI_CHAR, MPI_COMM_WORLD, &bsize);
char * tmpbuffer = nullptr;
tmpbuffer = (char*)malloc(bsize + 2 * MPI_BSEND_OVERHEAD);
if (!tmpbuffer) {
MPI_Abort(MPI_COMM_WORLD, 1);
}
MPI_Buffer_attach(tmpbuffer, bsize + 2 * MPI_BSEND_OVERHEAD);
MPI_Bsend(str, strlen(str), MPI_CHAR, MSG_RECV_RANK, MSG_TAG, MPI_COMM_WORLD);
char * buf;
int tsize = 0;
MPI_Buffer_detach(&buf, &tsize);
double wtime = MPI_Wtime(); // 获取运行时间
double wtick = MPI_Wtick(); // 获取时间单位(s),如果是毫秒则为0.001
cout << "rank " << rank << " bsend success, times :" << wtick * wtime << endl;
}
同步通信模式

MPI_Ssend()参数类似于标准模式
四、组通信
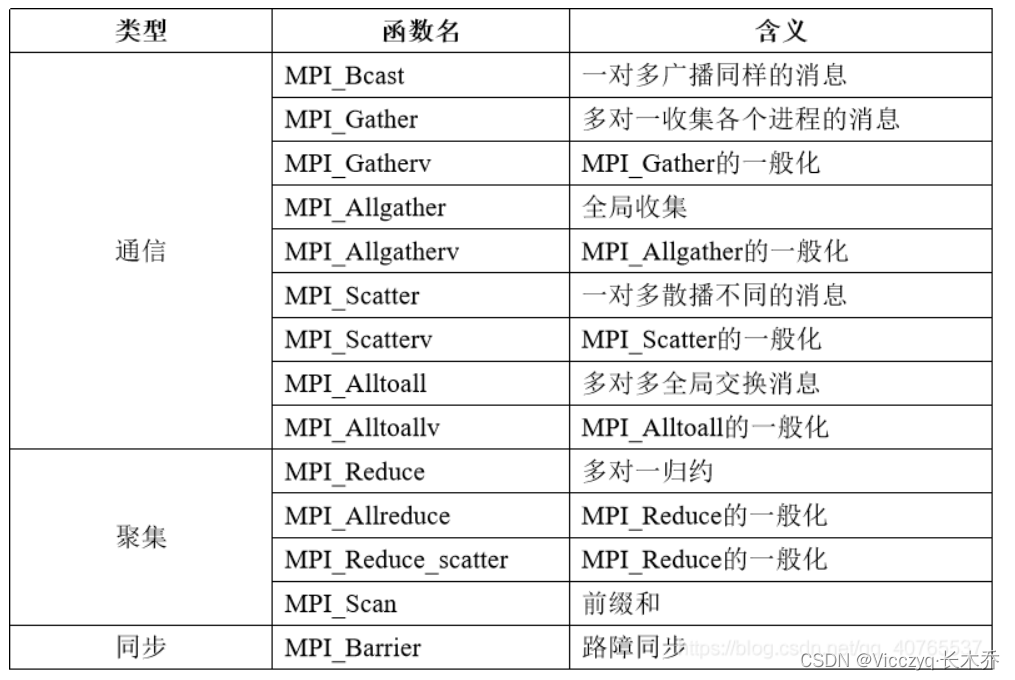
广播Bcast(一对多)

MPI广播函数:MPI_Bcast(buffer,count,dataType,root,comm)
#include <stdio.h>
#include <mpi.h>
#pragma comment(lib,"mpi.lib")
int main(int argc,char *argv[]){
int rank,nproc;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&nproc);
int data = 0;
int tag = 100;
MPI_Status status;
//主进程时把data赋值为99
if(rank == 0){
data = 99;
}
//这里就可以把data的值发出去,如果没有这个函数的话0号进程中的data就会和其他进程中的data不一样。
//MPI_Bcast(&data,1,MPI_INT,0,MPI_COMM_WORLD);
for (int i=0; i<nproc; i++){
printf("data = %d in %d process.\n",data,rank);
}
MPI_Finalize();
return 0;
}
单进程收集Gather(多对一)
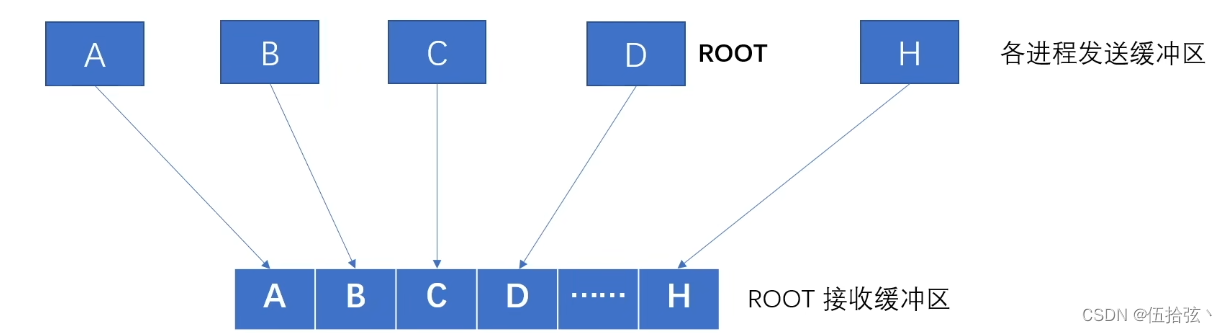
MPI_Gather(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,root,comm)
MPI_GatherV(sendbuf, sendcount , sendtype , recvbuf , recvcounts , displs , recvtype , root , comm)
–recvcounts 数组,表示接受每个进程对应发送的数据数目
–displs 数组,接收数据后存放的偏移量
散发Scatter(多对一)
MPI_Scatter(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,root,comm)
MPI_ScatterV(sendbuff,sendcounts,displs,sendtype,recvbuf,recvcounts,recvtype,root,commf)
组收集Allgather
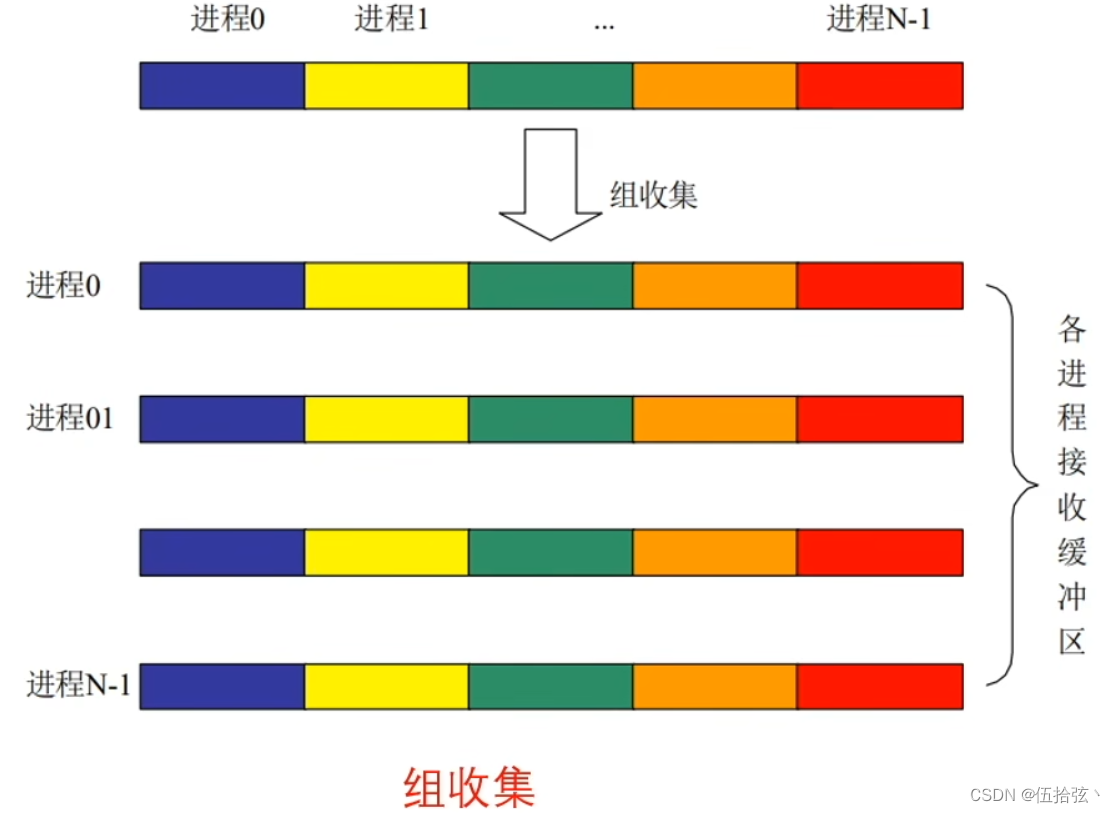
MPI_Allgather(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,root,comm)
同步Barrier
MPI_Barrier(comm)
MPI_BARRIER阻塞所有的调用者直到所有的组成员都调用了它 各个进程中这个调用才可以返回。
规约Reduce
规约Reduce
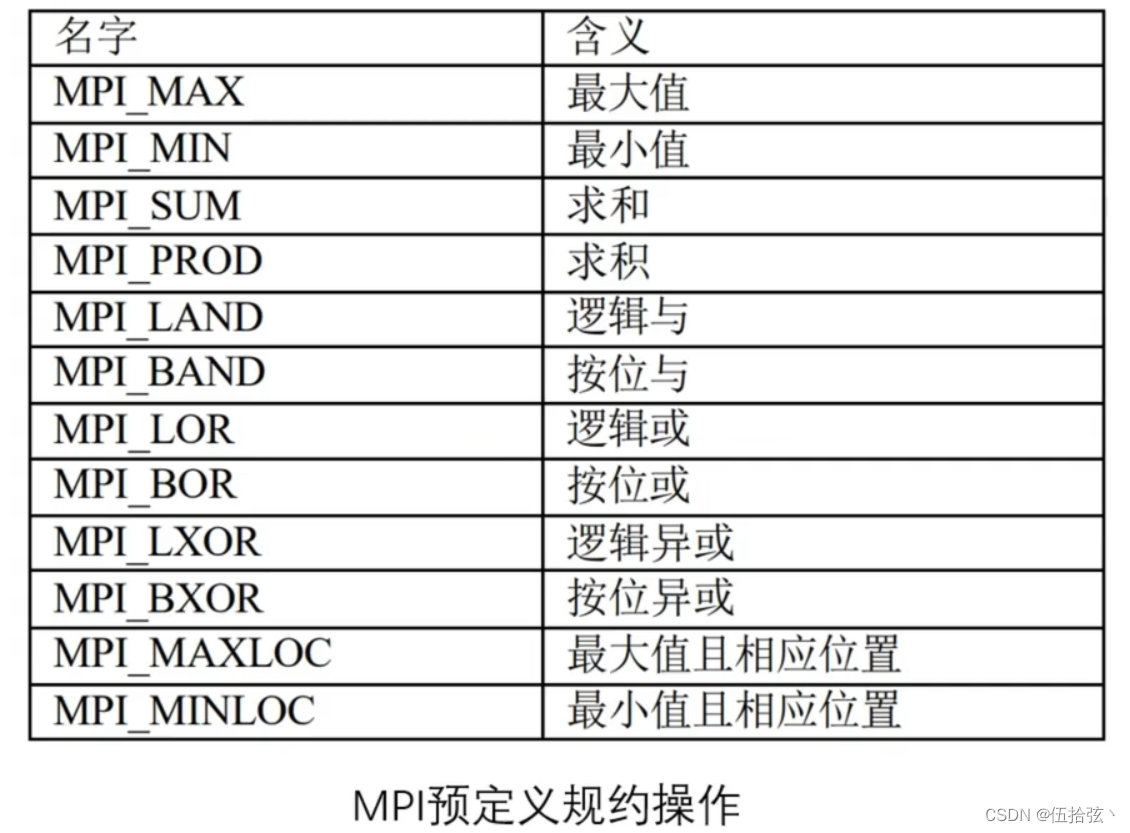
MPI_Reduce(sendbuf,recvbuf,count,datatype,op,root,comm)
–op 规约操作符(如:MPI_MAX,MPI_MIN等)
组规约Allreduce
MPI_Allreduce(sendbuf,recvbuf,count,datatype,op,comm)
注意:没有root,每个进程都进行规约操作
规约并散发Reduce_Scatter
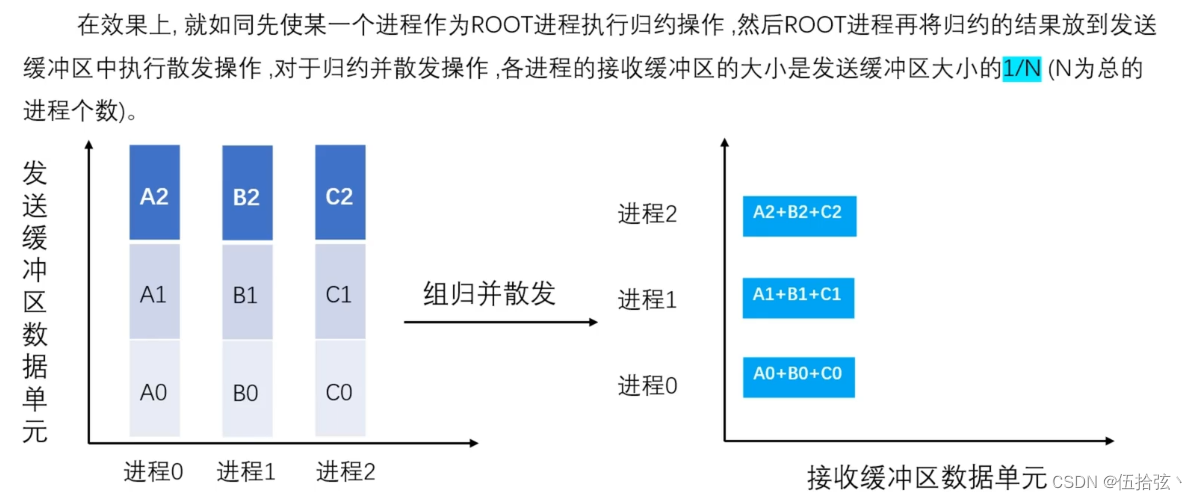
MPI_Reduce_Scatter(sendbuf,recvbuf,recvcounts,datatype,op,comm)
五、打包与解包
打包(Pack)和解包(Unpack)操作是为了发送不连续的数据 在发送前显式地把数据包装到一个连续的缓冲区,在接收之后从连续缓冲区中解包
1、打包Pack
MPI_Pack(inbuf, incount, datatype, outbuf, outcount, position, comm )
IN inbuf 输入缓冲区起始地址(可选数据类型)
IN incount 输入数据项个数(整型)
IN datatype 每个输入数据项的类型(句柄)
OUT outbuf 输出缓冲区开始地址(可选数据类型)
IN outcount 输出缓冲区大小(整型)
INOUT position 缓冲区当前位置(整型)
IN comm 通信域(句柄)
int MPI_Pack(void* inbuf, int incount, MPI_datatype, void *outbuf, int outcount, int
*position, MPI_Comm comm)
把由inbuf,incount,datatype指定的发送缓冲区中的 inbount个datatype类型的消息放到起始为outbuf的连续空间,该空间共有outcount个字节。
输入缓冲区可以是MPI_SEND允许的任何通信缓冲区 入口参数,position的值是输出缓冲区中用于打包的起始地址,打包后它的值根据打包消息的大小来增加,出口参数position的值是被打包的消息占用的输出缓冲区后面的第一个地址。通过连续几次对不同位置的消息调用打包操作 就将不连续的消息放到了一个连续的空间,comm参数是将在后面用于发送打包的消息时用的通信域。
2、解包Unpack
MPI_Unpack(inbuf, insize, position, outbuf, outcount, datatype, comm )
IN inbuf 输入缓冲区起始(选择)
IN insize 输入数据项数目(整型)
INOUT position 缓冲区当前位置, 字节(整型)
OUT outbuf 输出缓冲区开始(选择)
IN outcount 输出缓冲区大小, 字节(整型)
IN datatype 每个输入数据项的类型(句柄)
IN comm 打包的消息的通信域(句柄)
int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int
outcount, MPI_Datatype datatype, MPI_Comm comm)
从inbuf和insize指定的缓冲区空间将不连续的消息解开,放到outbuf,outcount,datatype指定的缓冲区中。
输出缓冲区可以是MPI_RECV允许的任何通信缓冲区,输入缓冲区是一个连续的存储空间大小为insize字节,开始地址为inbuf
入口参数position的初始值是输出缓冲区中被打包消息占用的起始地址,解包后它的值根据打包消息的大小来增加,因此出口参数position的值是输出缓冲区中被解包的消息占用空间后面的第一个地址。
通过连续几次对已打包的消息调用与打包时相应的解包操作就可以将连续的消息解开放到一个不连续的空间 comm参数是用于接收消息的通信域
#include <stdio.h>
#include "mpi.h"
int main( argc, argv )
int argc;
char **argv;
{
int rank;
int packsize, position;
int a;
double b;
char packbuf[100];
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
do {
if (rank == 0) {/*进程0读入数据*/
scanf( "%d %lf", &a, &b );
packsize = 0;/*打包开始位置*/
MPI_Pack( &a, 1, MPI_INT, packbuf, 100, &packsize,MPI_COMM_WORLD );/*将整数a打包*/
MPI_Pack( &b, 1, MPI_DOUBLE, packbuf, 100, &packsize,MPI_COMM_WORLD );/*将双精度数b打包*/}
MPI_Bcast( &packsize, 1, MPI_INT, 0, MPI_COMM_WORLD );/*广播打包数据的大小*/
MPI_Bcast( packbuf, packsize, MPI_PACKED, 0, MPI_COMM_WORLD );/*广播打包的数据*/
if (rank != 0) {
position = 0;
MPI_Unpack( packbuf, packsize, &position, &a, 1, MPI_INT,MPI_COMM_WORLD );/*其他进程先将a解包*/
MPI_Unpack( packbuf, packsize, &position, &b, 1, MPI_DOUBLE,MPI_COMM_WORLD );/*再将b解包*/}
printf( "Process %d got %d and %lf\n", rank, a, b );
} while (a >= 0);/*若a为负数则结束 否则继续上述过程*/
MPI_Finalize( );
return 0;
}
六、进程组和通信域
进程组是通信域的重要组成部分,MPI学习中一直使用的通信域MPI_COMM_WORLD所对应的进程组就是全体进程的集合
一个通信域包括:自身对应的进程组,通信上下文,虚拟处理器拓扑,属性等等。需要注意的是,一旦一个通信域被创建,通信域和进程组是一一对应的(组间通信域除外)。
通讯域
-
返回给定的通信域中包含的进程的个数
MPI_COMM_SIZE(comm,size) IN comm 通信域(句柄) OUT size comm组内的进程数(整数) int MPI_Comm_size(MPI_Comm comm, int *size) -
返回调用进程在给定的通信域中的编号rank
MPI_COMM_RANK(comm,rank) IN comm 通信域(句柄) OUT rank 调用进程的标识号 整型 int MPI_Comm_rank(MPI_Comm comm, int *rank) -
调用对两个给定的通信域进行比较。
(1)如果comm1和comm2是同一对象的句柄时,结果为MPI_IDENT
(2)如果仅仅是各进程组的成员和序列编号都相同 则结果为MPI_CONGRUENT
(3)如果两个通信域的组成员相同但序列编号不同 则结果是MPI_SIMILAR 否则结果是MPI_UNEQUAL
MPI_COMM_COMPARE(comm1,comm2,result)
IN comm1 第一个通信域(句柄)
IN comm2 第二个通信域(句柄)
OUT result 比较结果(整数)
int MPI_Comm_compare(MPI_Comm comm1,MPI_Comm comm2,int *result)
- 对已有的通信域comm进行复制 得到一个新的通信域newcomm
MPI_COMM_DUP(comm,newcomm)
IN comm 通信域(句柄)
OUT newcomm comm的拷贝(句柄)
int MPI_Comm_dup(MPI_Comm comm,MPI_Comm *newcomm)
-
根据group所定义的进程组 创建一个新的通信域 该通信域具有新的上下文。
所有的group参数都必须具有同样的值,而且group必须是comm对应进程组的一个子集
MPI_COMM_CREATE(comm,group,newcomm)
IN comm 通信域(句柄)
IN group 进程组 (句柄)
OUT newcomm 返回的新通信域(句柄)
int MPI_Comm_create(MPI_Comm comm,MPI_Group group,MPI_Comm *newcomm)
- 根据color值的不同,此调用首先将具有相同color值的进程形成一个新的进程组,新产生的通信域与这些进程组一一对应
MPI_COMM_SPLIT(comm,color,key,newcomm)
IN comm 通信域(句柄)
IN color 标识所在的子集 (整数)
IN key 对进程标识号的控制(整数)
OUT newcomm 新的通信域(句柄)
int MPI_Comm_split(MPI_Comm comm,int color, int key,MPI_Comm *newcomm)
- 调 用 释 放 给 定 的 通 信 域
MPI_COMM_FREE(comm)
IN/OUT comm 将被释放的通信域 句柄
int MPI_Comm_free(MPI_Comm *comm)
进程组
-
返回指定进程组中所包含的进程的个数
MPI_GROUP_SIZE(group,size) IN group 进程组 句柄 OUT size 组内进程数 整数 int MPI_Group_size(MPI_Group group,int *size) -
返回调用进程在给定进程组中的编号 rank 有些类似MPI_COMM_RANK
MPI_GROUP_RANK(group,rank)
IN group 进程组 句柄
OUT rank 调用进程的序列号/MPI_UNDEFINED 整数
int MPI_Group_rank(MPI_Group group,int *rank)
-
返回进程组group1中的n个进程由rank1指定 在 进程组group中对应的编号,相应的编号放在rank2中
MPI_GROUP_TRANSLATE_RANKS(group1,n,ranks1,group2,ranks2) IN group1 进程组1 句柄 IN n 数组rank1和rank2的大小 整数 IN ranks1 进程标识数组 整数数组 在进程组group1中的标识 IN group2 进程组2 句柄 OUT ranks2 ranks1在进程组group2中对应的标识数组 整型数组 int MPI_Group_translate_ranks(MPI_Group group1,int n,int *ranks1,MPI_Group group2,int *ranks2) -
对两个进程组group1和group2进行比较
如果两个进程组group1 和group2所包含的进程以及相同进程的编号都完全相同 则 返回MPI_IDENT
如果两个进程组group1和group2所包含的进程完全相同但是相同进程的编号在两个组中并不相同 则 返回MPI_SIMILAR
否则返回MPI_UNEQUAL
MPI_GROUP_COMPARE(group1,group2,result) IN group1 进程组 句柄 IN group2 进程组 句柄 OUT result 比较结果 整数 int MPI_Group_compare(MPI_Group group1,MPI_Group group2,int *result) -
返回指定的通信域所包含的进程组
MPI_COMM_GROUP(comm,group) IN comm 通信域 句柄 OUT group 和comm对应的进程组 句柄 int MPI_Comm_group(MPI_Comm comm, MPI_Group * group) -
N返回的新进程组newgroup是同时在进程组group1和进程组group2中出现的进程
MPI_GROUP_INTERSECTION(group1,group2,newgroup) IN group1 进程组 句柄 IN group2 进程组 句柄 OUT newgroup 求交后得到的进程组 句柄 int MPI_Group_intersection(MPI_Group group1,MPI_Group group2,MPI_Group *newgroup) -
返回的新进程组newgroup是在第一个进程组group1中出现但是又不在第二个进程组group2中出现的进程
MPI_GROUP_DIFFERENCE(group1,group2,newgroup) IN group1 进程组 句柄 IN group2 进程组 句柄 OUT newgroup 求差后得到的进程组 句柄 int MPI_Group_difference(MPI_Group group1,MPI_Group group2,MPI_Group *newgroup) -
将已有进程组中的n个进程rank[0] … rank[n-1]形成一个新的进程组newgroup
MPI_GROUP_INCL(group,n,ranks,newgroup) IN group 进程组 句柄 IN n ranks数组的大小 整型 IN ranks 进程标识数组 整数数组 OUT newgroup 新的进程组 句柄 int MPI_Group_incl(MPI_Group group,int n,int *ranks,MPI_Group *newgroup) -
将已有进程组group中的n个进程ranks[0],…,ranks[n-1]删除后形成新 的进程组newgroup
MPI_GROUP_EXCL(group,n,ranks,newgroup) IN group 进程组(句柄) IN n 数组ranks的大小(整型) IN ranks 不出现在newgroup中的进程标识数组 整型数组 OUT newgroup 新进程组 句柄 int MPI_Group_excl(MPI_Group group, int n , int *ranks,MPI_Group *newgroup) -
释放一个已有的进程组
MPI_GROUP_FREE(group) IN/OUT group 进程组(句柄) int MPI_Group_free(MPI_Group *group)
通信域和进程组示例
#include "mpi.h"
#include <stdio.h>
#include <stdlib.h>
#define LEN 5
int main(int argc, char *argv[])
{
MPI_Init(&argc, &argv);
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_rank(MPI_COMM_WORLD, &world_size);
MPI_Group world_group;
MPI_Comm_group(MPI_COMM_WORLD, &world_group);//获取MPI_COMM_WORLD中的进程组
int n = 3;
const int ranks[3] = {1,3,5};
const int ori1[1] = {1};
const int ori2[1] = {0};
int root1, root2;
// 从world_group进程组中构造出来两个进程组
MPI_Group group1, group2;
MPI_Group_incl(world_group, n, ranks, &group1);
MPI_Group_excl(world_group, n, ranks, &group2);
// 根据group1 group2分别构造两个通信域
MPI_Comm comm1, comm2;
MPI_Comm_create(MPI_COMM_WORLD, group1, &comm1);
MPI_Comm_create(MPI_COMM_WORLD, group2, &comm2);
// 清理进程组和通信域
if(MPI_GROUP_NULL!=group1) MPI_Group_free(&group1);
if(MPI_GROUP_NULL!=group2) MPI_Group_free(&group2);
if(MPI_COMM_NULL!=comm1) MPI_Comm_free(&comm1);
if(MPI_COMM_NULL!=comm2) MPI_Comm_free(&comm2);
MPI_Finalize();
}
七、实例
1、求π
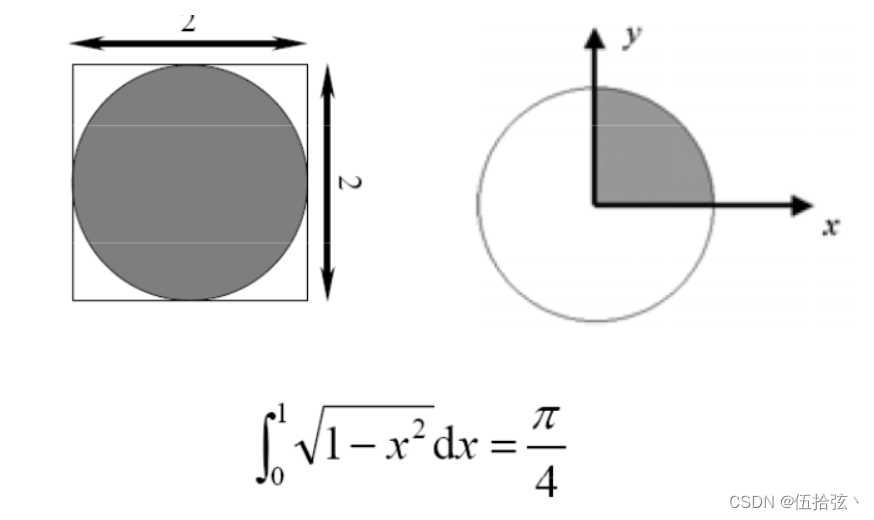

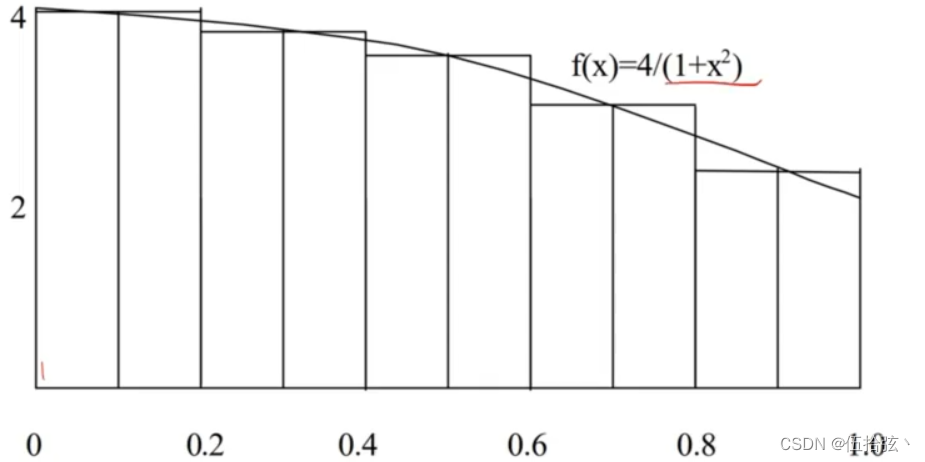
其中(i-0.5)/n是为了让长方形块取中间
#include <iostream>
#include <omp.h>
#include <math.h>
using namespace std;
int n=1e9;
double step_len = 1.0/n;
int main()
{
double PI=0;
double sum=0;
#pragma omp parallel for reduction(+:sum)
for(int i=1;i<=n;i++)
{
double x=step_len*(double(i));
sum+=(4.0/(1+pow(x,2)));
}
printf("%.16lf",sum*step_len);
return 0;
}
#include <stdio.h>
#include <mpi.h>
#include <math.h>
int main()
{
int n,myid,numproces;
double h,mypi=0,pi=0,sum=0,stm,et;
MPI_Init(NULL,NULL);
MPI_Comm_size(MPI_COMM_WORLD,&numproces);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if(myid==0)
{
n=100;
}
stm = MPI_Wtime();
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
h=1.0/(double)n;
int i=0;
for(i=myid+1;i<=n;i+=numproces)
{
double x=h*((double)i-0.5);
sum+=4.0/(pow(x,2)+1);
}
mypi = h*sum;
MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
if(myid==0)
{
printf("pi is %.16lf\n",pi);
et=MPI_Wtime();
printf("time:%f\n",et-stm);
}
MPI_Finalize();
return 0;
}















 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









