







MPI基本知识学习汇总
目的
目的:降低程序运行时间
MPI:message passing interface(消息传递库)
分布存储系统:程序员显式的安排消息传递方式
FORTRAN:include mpif.h或use mpi
基本概念
MPI_COMM_WORLD:最大(全局)通信域,所有进程的集合;
Call MPI_Init(ierror):mpi初始化;(integer ierror)
Call MPI_Finalize(ierror):mpi结束;(integer ierror)
Call MPI_Comm_size(comm,size,ierror):获取一个通信域中有多少个进程;(integer comm——指定通信域,size——包含的进程总数,ierror)
Call MPI_Comm_rank(comm,rank,ierror):获取进程编号ID,0~(size-1);(integer comm,rank——该进程在制定通信域中的ID,ierror)
Call MPI_Send(buf——发送缓冲区,count——将要发送的数据个数,datatype——MPI数据类型,dest——目标(接收)进程号,tag——消息标签,comm——通信域,ierror):发送消息;(integer count,dp(datatype),dest,tag,comm,ierror)将本进程缓冲区buf中的datatype数据类型的count个数据发送给进程dest,该消息标识为tag。
call MPI_Recv(buf——接收缓冲区,count——最多可接收的数据个数,dp,source——来源(发送进程号),tag,comm,sts——返回状态,存放实际接收消息的状态信息,包括消息的源进程标识,消息标签,包含的数据项个数等,err):消息接收;(integer count,dp,source,tag,comm,sts(status_size),err)
call MPI_SendRecv发送和接收数据
error类型
- 因为call mpi_recv 在call mpi_send 前面,程序就会发生锁死;
- 如果call mpi_send和call mpi_recv后面括号中的进程号不一样的话,也会发生锁死。
例子jacobi中迭代划分区域时,会出现需要虚拟进程的情况,此时需要用到MPI_PROC_NULL。
1.消息传递模型
指程序通过在进程间传递消息(消息可以理解成带有一些信息和数据的一个数据结构)来完成某些任务。
举例来说,主进程(master process)可以通过对从进程(slave process)发送一个描述工作的消息来把这个工作分配给它。
另一个例子就是一个并发的排序程序可以在当前进程中对当前进程可见的(我们称作本地的,locally)数据进行排序,然后把排好序的数据发送的邻居进程上面来进行合并的操作。
几乎所有的并行程序可以使用消息传递模型来描述。
2.MPI就是消息传递接口的标准
3.MPI在消息传递模型设计上的经典概念:
(1)通讯器(communicator)。通讯器定义了一组能够互相发消息的进程。
(2)在这组进程中,每个进程会被分配一个序号,称作秩(rank),进程间显性地通过指定秩来进行通信。
(3)通信的基础建立在不同进程间发送和接收操作。
(4)一个进程可以通过指定另一个进程的秩以及一个独一无二的消息标签(tag)来发送消息给另一个进程。
接受者可以发送一个接收特定标签标记的消息的请求(或者也可以完全不管标签,接收任何消息),然后依次处理接收到的数据。
类似这样的涉及一个发送者以及一个接受者的通信被称作点对点(point-to-point)通信。
(5)当然在很多情况下,某个进程可能需要跟所有其他进程通信。
比如主进程想发一个广播给所有的从进程。在这种情况下,手动去写一个个进程点对点的信息传递就显得很笨拙。而且事实上这样会导致网络利用率低下。
MPI 有专门的接口来帮我们处理这类所有进程间的集体性(collective)通信。
(6)把点对点通信和集体性通信这两个机制合在一起已经可以创造十分复杂的并发程序了。
4.MPI简单的程序hello world介绍:
主要是c++程序在集群上跑程序时如何设置节点,以及多核节点如何设置进程生成
5.MPI中的send和receive
(1)A进程把消息打包放入缓存中,通信设备把信息传递到特定的秩rank对应的进程B,
B确认想接受来自A的数据,确认后,A收到数据传递成功信息,执行其他操作。
A传递多个不同消息时,B可以通过标签tags进行区分,其余不需要的信息暂被缓存。
(2)send和recv使用了一种在更高层次指定消息结构的方法。
例如,如果一个进程想要发送一个整数给另一个进程,它会指定 count 为 1,数据结构为 MPI_INT(因为c语言的整数是int)。
6.预估和动态的接受信息——未知长度
MPI_recv中有一项是MPI_Status,在mpi接收完成后填充附加信息:发送者的等级/秩rank、消息的标签tag、消息的长度count。
7
.MPI的点对点通信只会涉及到两个不同的进程,对于多个进程来说,需要进行MPI集体通信(collective communication)。(对我而言,控制体的并行需要集体通信,但如果是一二回路系统之间的并行则可以点对点通信)
8.集体通信:
特点:引入了同步点的概念,用函数MPI_Barrier,当所有进程都到达call MPI_Barrier时,进程才会继续向前执行。同步的一个用途是精确计时代码中的某部分。(注意:使用前一定要确保所有的进程都会执行到这一步)
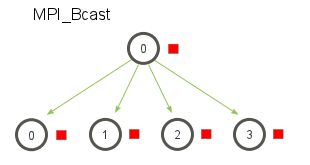
9.标准集体通信机制之一——广播MPI_Bcast(一对多-相同)
一个广播发生的时候,一个进程(根/root进程)会把同样一份数据传递给一个communicator里的所有其他进程(接收进程)。
一般用途:把用户输入传递给一个分布式程序或把所有配置参数传递给所有进程。
当根节点调用MPI_Bcast 函数的时候,data变量里的值会被发送到其他的节点上。当其他的节点调用MPI_Bcast的时候,data变量会被赋值成从根节点接受到的数据。
MPI_Bcast可以是MPI_send和MPI_recv的封装。但不是简单地叠加,而是利用树算法来进行设计,在两个进程以上时,会有明显的加速。
10. MPI_Wtime:
返回以浮点数形式展示的从1970-01-01到现在为止进过的秒数,可以多次调用MPI_Wtime函数,并去差值,来计算代码运行的时间。
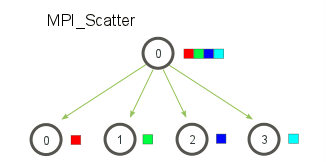
11.其他集体通信机制——MPI Scatter(一对多-不同)
MPI_Scatter:设计一个指定的根进程,根进程会将数据发送到communicator 里面的所有进程。
MPI_Bcast和MPI_Scatter的主要区别:MPI_Bcast给每个进程发送的是同样的数据;MPI_Scatter给每个进程发送的是一个数组的一部分数据。
MPI_Bcast在根进程上接收一个单独的数据元素(红色的方块),然后把它复制到所有其他的进程。
MPI_Scatter接收一个数组,并把元素按进程的秩分发出去。第一个元素(红色方块)发往进程0,第二个元素(绿色方块)发往进程1,以此类推。尽管根进程(进程0)拥有整个数组的所有元素,MPI_Scatter 还是会把正确的属于进程0的元素放到这个进程的接收缓存中。
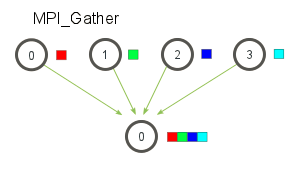
12.MPI_Gather(多对一)
MPI_Gather跟MPI_Scatter是相反的。MPI_Gather是从好多进程里面收集数据到一个进程(根进程)上面。元素是根据接收到的进程的秩排序的。可用于并行的排序和搜索。
在MPI_Gather中,只有根进程需要一个有效的接收缓存。所有其他的调用进程可以传递NULL给recv_data。另外,recv_count参数是从每个进程接收到的数据数量,而不是所有进程的数据总量之和。
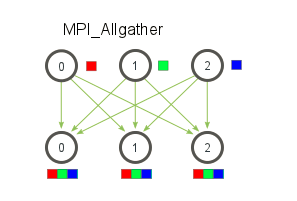
13.MPI_Allgather(多对多)
对于分发在所有进程上的一组数据来说,MPI_Allgather会收集所有数据到所有进程上。每个进程上的元素是根据他们的秩为顺序被收集起来的
MPI_Allgather相当于一个MPI_Gather操作之后跟着一个MPI_Bcast操作。
14.Reduce
Reduce是函数式编程的经典概念。reduce是指通过一个函数将一组数字缩减为更小的一组数字。例如,我们有一个数字列表[1,2,3,4,5]。使用sum函数来减少这个数字列表将产生sum([1,2,3,4,5])=15。同样地,乘法缩减会产生乘([1,2,3,4,5])=120。
在一组分布数上应用约简函数是非常麻烦的。与此同时,很难有效地编程非交换约简(必须按一定顺序发生的约简)。
MPI Reduce函数可以处理程序员在并行应用程序中需要做的几乎所有常见的压缩。
15.MPI_reduce
与MPI_Gather类似,MPI_Reduce在每个进程上接受一个输入元素数组,并向根进程返回一个输出元素数组。输出元素包含简化后的结果。
不是将所有数组中的所有元素相加为一个元素,而是将每个数组中的第i个元素相加为进程0的结果数组中的第i个元素。


MPI Reduce的约简操作主要包含:
MPI_MAX—返回最大元素。
MPI_MIN—返回最小元素。
MPI_SUM—对元素求和。
MPI_PROD—将所有元素相乘。
MPI_LAND—跨元素执行逻辑和。
MPI_LOR—跨元素执行逻辑或。
MPI_BAND—按位和跨元素的位执行。
MPI_BOR—按位或跨元素的位执行。
MPI_MAXLOC—返回最大值和拥有它的进程的级别。
MPI_MINLOC—返回最小值及其所属进程的级别。
16.MPI_ALLReduce
MPI_Allreduce是约简值并将结果分发给所有进程。
MPI_Allreduce相当于一个MPI_Reduce操作之后跟着一个MPI_Bcast操作。

用MPI Allreduce计算标准偏差
17.MPI_COMM_WORLD
一般默认的是全局的所有进程,但也可以根据需求进行拆分,然后确定拆分后属于哪一个通信器communicator,一般根据秩的顺序进行划分。
18. communicator 创建函数
MPI_Comm_split:最常见的通信器创建函数,最简单的办法;
MPI_Comm_dup:创建通信器的副本,对于使用库执行特定函数(如数学库)的应用程序非常有用;在这类应用程序中,用户代码和库代码不相互干扰是很重要的。为了避免这种情况,每个应用程序应该做的第一件事就是创建MPI COMM WORLD的副本,这将避免其他库也使用MPI COMM WORLD的问题。
MPI_Comm_create:对Comm中的每个进程的集合。
MPI_Comm_create_group:对group中包含的进程组的集合。















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









