







一、简介
1.1关于项目


Tesseract是一款优秀的开源OCR软件,是由HP实验室开发,Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
目前由Google维护改进,已发展到5.0版本,从4.0版本起增加了基于LSTM神经网络的识别引擎
本项目使用Springboot + Tesseract OCR引擎实现图片文字自动识别功能。
1.2准备
JDK:17
Maven:3.6
开发工具:IntelliJ IDEA
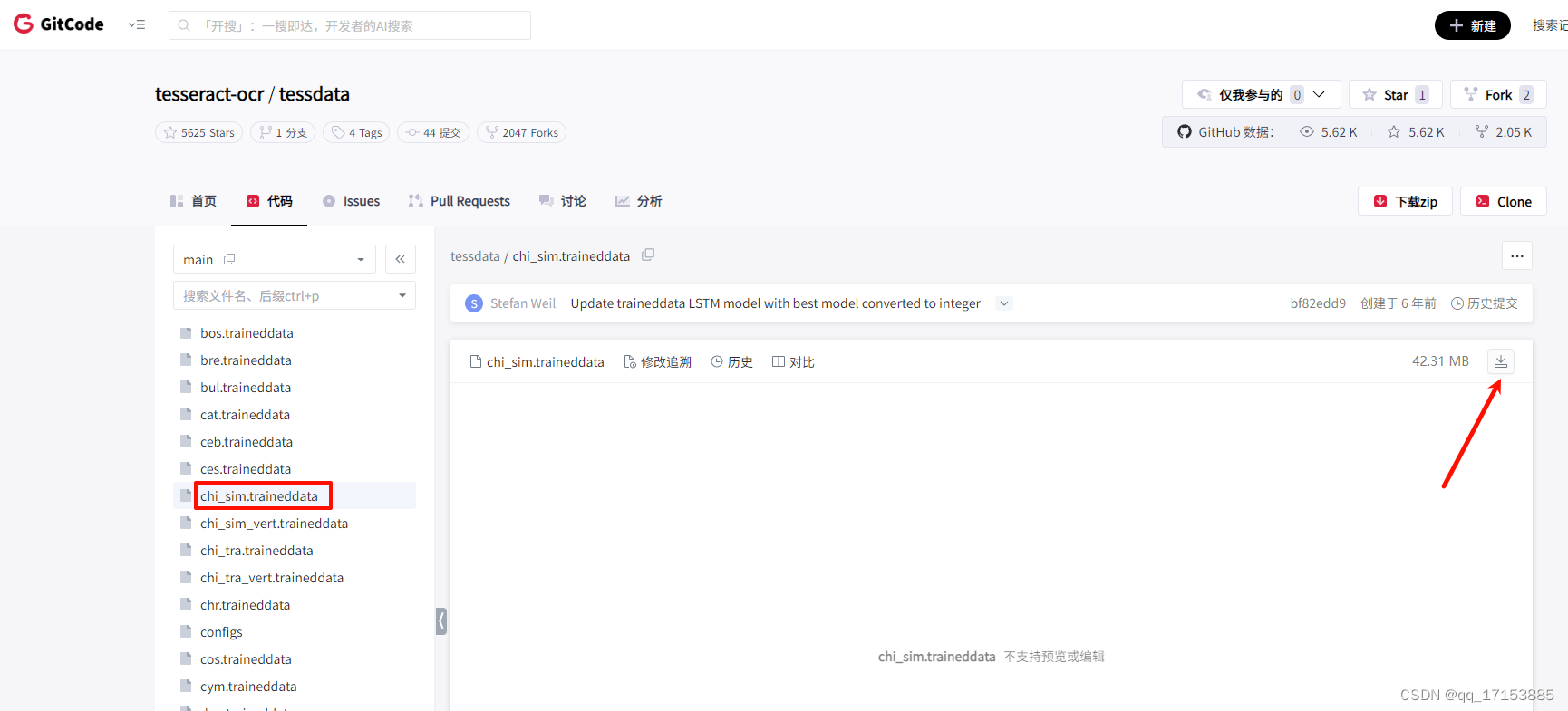
Tesseract模型文件:chi_sim.traineddata
本项目源代码:可私信提供
1.3Tesseract模型文件下载
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









