







利用OpenMP的多线程,对数组进行分组求和,最后对每个线程的局部求和结果进行求和。
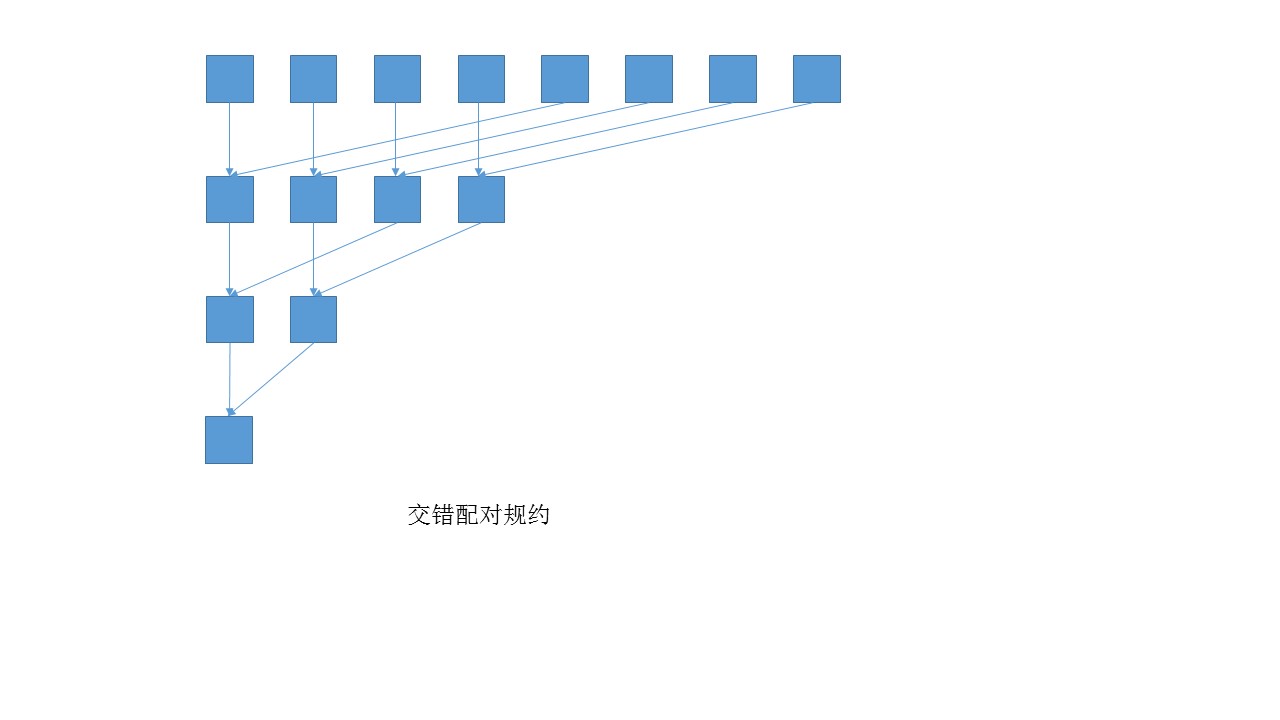
这里采用交错配对(下文还有相邻配对),如图所示。
#include"iostream"
#include"omp.h"
using namespace std;
#define NUM_THREADS 4
//并行规约
template <class T>
T omp_reduction(T*data ,int length)
{
if (length == 1) return *data;
int strize = length / 2;
for (int i = 0; i < strize; i++)
{
data[i]+=data[i+strize];
}
omp_reduction(data,strize);
}
//数组初始化
template<class T>
void datainit(T* data,int length)
{
for (int i = 0; i < length; i++)
{
data[i]=i;
}
}
//计算结果检查
template<class T>
bool check_result(T data1,T data2,int length)
{
if (data1!=data2) return false;
return true;
}
int main()
{
//基本参数设置
const int datalen=256;
int* data=new int[datalen];
int local_sum[NUM_THREADS];
int total_sum_serial=0;
int total_sum_omp=0;
int step=datalen/NUM_THREADS;
bool check_ok;
//数组初始化
datainit(data,datalen);
//设置并启动4个并行的omp线程
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel
{
int index=omp_get_thread_num();//获取当前线程号
local_sum[index]
=omp_reduction(data+index*step,step);//调用规约函数计算当前线程所分配的任务
}
//对线程的局部求和结果进行求和
for (int i = 0; i < NUM_THREADS; i++)
{
total_sum_omp+=local_sum[i];
}
//串行数组求和
datainit(data,datalen);
for (int i = 0; i < datalen; i++)
{
total_sum_serial+=data[i];
}
check_ok=check_result(total_sum_omp,total_sum_serial,datalen);
if (check_ok)
{
cout<<"omp并行规约计算正确!"<<endl;
}
else
{
cout<<"omp并行规约计算错误!"<<endl;
}
cin.get();
return 0;
}















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









