







目录
Flink SQL除了支持基本查询外,还支持一些复杂的高阶聚合和关联。
高阶聚合
语法
group by cube(维度 1,维度 2,维度 3)
group by grouping sets( (维度 1,维度 2) ,(维度 1,维度 3), (维度 2),())
group by rollup(省,市,区)
示例
select
province, city, region, count(distinct uid) as u_cnt
from t
group by cube(province, city, region)
select
province, city, region, count(distinct uid) as u_cnt
from t
group by rollup(province, city, region)
select
province, city, region, count(distinct uid) as u_cnt
from t
group by grouping sets((province, city),(province, city, region))
时间窗口 TVF(表值函数)
Windowing table-valued functions (Windowing TVFs)
flink1.13 开始,提供了时间窗口聚合计算的 TVF 语法
表值函数的使用约束:
- 在窗口上做分组聚合,必须带上 window_start 和 window_end 作为分组 key。
- 在窗口上做 topN 计算 ,必须带上 window_start 和 window_end 作为 partition 的 key。
- 带条件的 join,必须包含 2 个输入表的 window start 和 window end 等值条件。
语法示例
select
......
from table(
tumble (table t, descriptor(rt), interval '10' minutes)
)
支持的时间窗口类型
- 滚动窗口 (Tumble Windows)
TUMBLE(TABLE t_action,DESCRIPTOR(时间属性字段), INTERVAL '10' SECONDS[窗口长度])
- 滑动窗口(Hop Windows)
HOP (TABLE t_action, DESCRIPTOR(时间属性字段), INTERVAL '5' SECONDS[滑动步长], INTERVAL '10' SECONDS[窗口长度] )
- 累计窗口(Cumulate Windows)
CUMULATE (TABLE t_action, DESCRIPTOR(时间属性字段), INTERVAL '5' SECONDS[更新最大步长] , INTERVAL '10' SECONDS[窗口最大长度] )
- 会话窗口(Session Windows)
暂不支持
window 聚合
案例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// bidtime | price | item | supplier_id |
DataStreamSource<String> s1 = env.socketTextStream("hdp01", 9999);
SingleOutputStreamOperator<Bid> s2 = s1.map(s -> {
String[] split = s.split(",");
return new Bid(split[0], Double.parseDouble(split[1]), split[2], split[3]);
});
// 把流变成表
tenv.createTemporaryView("t_bid", s2, Schema.newBuilder()
.column("bidtime", DataTypes.STRING())
.column("price", DataTypes.DOUBLE())
.column("item", DataTypes.STRING())
.column("supplier_id", DataTypes.STRING())
.columnByExpression("rt", $("bidtime").toTimestamp())
.watermark("rt", "rt - interval '1' second")
.build());
// 查询
// tenv.executeSql("select bidtime,price,item,supplier_id,current_watermark(rt) as wm from t_bid").print();
// 每分钟,计算最近5分钟的交易总额
tenv.executeSql(
"select" +
" window_start," +
" window_end," +
" sum(price) as price_amt" +
"from table(" +
" hop(table t_bid,descriptor(rt), interval '1' minutes, interval '5' minutes)" +
")" +
"group by window_start,window_end"
)/*.print()*/;
// 每2分钟计算最近2分钟的交易总额
tenv.executeSql(
"select" +
" window_start," +
" window_end," +
" sum(price) as price_amt" +
"from table(" +
" tumble(table t_bid, descriptor(rt), interval '2' minutes)" +
")" +
"group by window_start, window_end"
)/*.print()*/;
// 每2分钟计算今天以来的总交易额
tenv.executeSql(
"select" +
" window_start," +
" window_end," +
" sum(price) as price_amt" +
"from table(" +
" cumulate(table t_bid,descriptor(rt),interval '2' minutes, interval '24' hour)" +
")" +
"group by window_start,window_end"
)/*.print()*/;
// 时间窗口上聚合后求topN
// 每10分钟计算一次,最近10分钟内交易总额最大的前2个供应商及其交易单数
tenv.executeSql(
"select * from" +
"(select" +
" window_start,window_end," +
" supplier_id," +
" price_amt," +
" bid_cnt," +
" row_number() over(partition by window_start, window_end order by price_amt desc) as rn" +
" from (" +
" select" +
" window_start," +
" window_end," +
" supplier_id," +
" sum(price) as price_amt," +
" count(1) as bid_cnt" +
" from table(tumble(table t_bid, descriptor(rt), interval '10' minutes) ) " +
" group by window_start,window_end,supplier_id" +
" )" +
") " +
"where rn<=2"
)/*.print()*/;
// 时间窗口上直接求topN
// 每10分钟窗口中,交易金额最大的前2单
tenv.executeSql("SELECT * from" +
"(SELECT" +
" bidtime," +
" price," +
" item," +
" supplier_id," +
" row_number() over(partition by window_start, window_end order by price desc) as rn" +
"FROM TABLE(TUMBLE(table t_bid, descriptor(rt), interval '10' minute))" +
")" +
"WHERE rn<=2")
.print();
env.execute();
}
window join
在 TVF 上使用 join 要点
- 参与 join 的两个表都需要定义时间窗口
- join 的条件中必须包含两表的 window_start 和 window_end 的等值条件
支持的 join 方式
- inner/left/right/full
- semi(即:where id in … )
- anti( 即:where id not in … )
示例
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
/**
* 1,a,1000
* 2,b,2000
* 3,c,2500
* 4,d,3000
* 5,e,12000
*/
DataStreamSource<String> s1 = env.socketTextStream("hdp01", 9998);
SingleOutputStreamOperator<Tuple3<String, String,Long>> ss1 = s1.map(s -> {
String[] arr = s.split(",");
return Tuple3.of(arr[0], arr[1],Long.parseLong(arr[2]));
}).returns(new TypeHint<Tuple3<String, String,Long>>() {
});
/**
* 1,bj,1000
* 2,sh,2000
* 4,xa,2600
* 5,yn,12000
*/
DataStreamSource<String> s2 = env.socketTextStream("hdp01", 9999);
SingleOutputStreamOperator<Tuple3<String, String,Long>> ss2 = s2.map(s -> {
String[] arr = s.split(",");
return Tuple3.of(arr[0], arr[1],Long.parseLong(arr[2]));
}).returns(new TypeHint<Tuple3<String, String,Long>>() {
});
// 创建两个表
tenv.createTemporaryView("t_left",ss1, Schema.newBuilder()
.column("f0", DataTypes.STRING())
.column("f1", DataTypes.STRING())
.column("f2", DataTypes.BIGINT())
.columnByExpression("rt","to_timestamp_ltz(f2,3)")
.watermark("rt","rt - interval '0' second")
.build());
tenv.createTemporaryView("t_right",ss2, Schema.newBuilder()
.column("f0", DataTypes.STRING())
.column("f1", DataTypes.STRING())
.column("f2", DataTypes.BIGINT())
.columnByExpression("rt","to_timestamp_ltz(f2,3)")
.watermark("rt","rt - interval '0' second")
.build());
// 各类窗口join示例
// INNER
tenv.executeSql(
"SELECT" +
" a.f0,a.f1,a.f2,b.f0,b.f1 " +
"from " +
"( select * from table(tumble(table t_left,descriptor(rt),interval '10' second)) ) a" +
"join " +
"( select * from table(tumble(table t_right,descriptor(rt),interval '10' second)) ) b" +
"on a.window_start=b.window_start and a.window_end = b.window_end and a.f0=b.f0"
)/*.print()*/;
// left / right / full outer
tenv.executeSql(
"SELECT" +
" a.f0,a.f1,a.f2,b.f0,b.f1" +
"from \n" +
"( select * from table(tumble(table t_left,descriptor(rt),interval '10' second)) ) a" +
"full join" +
"( select * from table(tumble(table t_right,descriptor(rt),interval '10' second)) ) b" +
"on a.window_start=b.window_start and a.window_end = b.window_end and a.f0=b.f0"
)/*.print()*/;
// semi Join ==> where ... in ....
tenv.executeSql(
"SELECT" +
" a.f0,a.f1,a.f2" +
"from" +
"( select * from table(tumble(table t_left,descriptor(rt),interval '10' second)) ) a" +
"where f0 in " +
"(" +
" select f0 from " +
" (select * from table(tumble(table t_right,descriptor(rt),interval '10' second))) b" +
" where a.window_start=b.window_start and a.window_end=b.window_end " +
")"
).print();
// semi Join ==> where ... not in ....
tenv.executeSql(
"SELECT" +
" a.f0,a.f1,a.f2" +
"from " +
"( select * from table(tumble(table t_left,descriptor(rt),interval '10' second)) ) a" +
"where f0 not in " +
"(" +
" select f0 from" +
" (select * from table(tumble(table t_right,descriptor(rt),interval '10' second))) b" +
" where a.window_start=b.window_start and a.window_end=b.window_end" +
")"
).print();
}
FlinkSql 提供了非常丰富的 join 功能,为实现各类关联场景提供强大的功能支撑
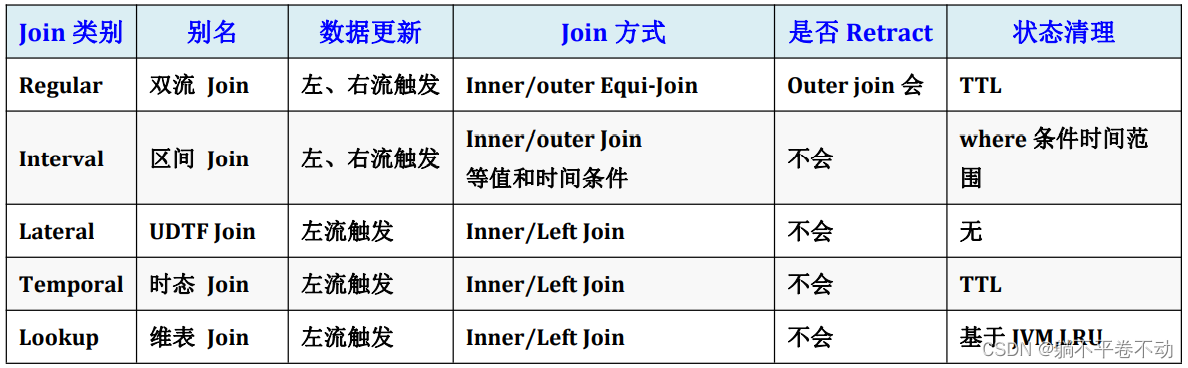
regular join
常规 join,flink 底层是会对两个参与 join 的输入流中的数据进行状态存储的;
所以,随着时间的推进,状态中的数据量会持续膨胀,可能会导致过于庞大,从而降低系统的整体效
率;
如何去缓解呢:自己根据自己业务系统数据特性(估算能产生关联的左表数据和右表数据到达的最
大时间差),根据这个最大时间差,可以设置状态的 ttl 时长,来控制状态的体积上限。
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 设置 table 环境中的状态 ttl 时长
tenv.getConfig().getConfiguration().setLong("table.exec.state.ttl", 60*60*1000L);
interval join
tenv.executeSql("select a.f0, a.f1, a.f2, b.f0, b.f1 from t_left a join t_right b " +
"on a.f0 = b.f0 " +
"and a.rt between b.rt - interval '2' second and b.rt")
.print();
lookup join
lookup join 为了提高性能,lookup 的连接器会将查询过的维表数据进行缓存(默认未开启此机制),
可以通过参数开启,比如 jdbc-connector 的 lookup 模式下,有如下参数:
- lookup.cache.max-rows = (none) 未开启
- lookup.cache.ttl = (none) ttl 缓存清除的时长
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 设置table环境中的状态ttl时长
tenv.getConfig().getConfiguration().setLong("table.exec.state.ttl", 60 * 60 * 1000L);
/**
* 1,a
* 2,b
* 3,c
* 4,d
* 5,e
*/
DataStreamSource<String> s1 = env.socketTextStream("hdp01", 9998);
SingleOutputStreamOperator<Tuple2<Integer, String>> ss1 = s1.map(s -> {
String[] arr = s.split(",");
return Tuple2.of(Integer.parseInt(arr[0]), arr[1]);
}).returns(new TypeHint<Tuple2<Integer, String>>() {
});
// 创建主表(需要声明处理时间属性字段)
tenv.createTemporaryView("a", ss1, Schema.newBuilder()
.column("f0", DataTypes.INT())
.column("f1", DataTypes.STRING())
.columnByExpression("pt", "proctime()") // 定义处理时间属性字段
.build());
// 创建lookup维表(jdbc connector表)
tenv.executeSql(
"create table b( " +
" id int, " +
" name string, " +
" gender STRING, " +
" primary key(id) not enforced " +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://hdp01:3306/flinktest'," +
" 'table-name' = 'stu'," +
" 'username' = 'root'," +
" 'password' = 'root' " +
")"
);
// lookup join 查询
tenv.executeSql("select a.*, c.* from a JOIN b FOR SYSTEM_TIME AS OF a.pt AS c ON a.f0 = c.id").print();
env.execute();
}
temporal join
左表的数据永远去关联右表数据的对应时间上的最新版本。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
/**
* 订单Id,币种,金额,订单时间
* 1,a,100,167438436400
*/
DataStreamSource<String> s1 = env.socketTextStream("hdp01", 9998);
SingleOutputStreamOperator<Order> ss1 = s1.map(s -> {
String[] arr = s.split(",");
return new Order(Integer.parseInt(arr[0]), arr[1], Double.parseDouble(arr[2]), Long.parseLong(arr[3]));
});
// 创建主表(需要声明处理时间属性字段)
tenv.createTemporaryView("orders", ss1, Schema.newBuilder()
.column("orderId", DataTypes.INT())
.column("currency", DataTypes.STRING())
.column("price", DataTypes.DOUBLE())
.column("orderTime", DataTypes.BIGINT())
.columnByExpression("rt", "to_timestamp_ltz(orderTime,3)") // 定义处理时间属性字段
.watermark("rt","rt")
.build());
//tenv.executeSql("select orderId,currency,price,orderTime,rt from orders").print();
// 创建 temporal 表
tenv.executeSql("CREATE TABLE currency_rate (\n" +
" currency STRING, \n" +
" rate double , \n" +
" update_time bigint , \n" +
" rt as to_timestamp_ltz(update_time,3) ," +
" watermark for rt as rt - interval '0' second ," +
" PRIMARY KEY(currency) NOT ENFORCED\n" +
" ) WITH ( \n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'hdp01',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = 'root',\n" +
" 'database-name' = 'flinktest',\n" +
" 'table-name' = 'currency_rate'\n" +
")");
//tenv.executeSql("select * from currency_rate").print();
// temporal 关联查询
tenv.executeSql(
"SELECT \n" +
" orders.orderId, \n" +
" orders.currency, \n" +
" orders.price, \n" +
" orders.orderTime, \n" +
" rate \n" +
"FROM orders \n" +
"LEFT JOIN currency_rate FOR SYSTEM_TIME AS OF orders.rt \n" +
"ON orders.currency = currency_rate.currency"
).print();
env.execute();
}
array join
public static void main(String[] args) {
TableEnvironment tenv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
Table table = tenv.fromValues(DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("tags", DataTypes.ARRAY(DataTypes.STRING())))
, row("1", "zs", array("stu", "child"))
, row("2", "bb", array("miss"))
);
tenv.createTemporaryView("t",table);
tenv.executeSql("select t.id,t.name,x.tag from t cross join unnest(tags) as x(tag)")/*.print()*/;
tenv.createTemporarySystemFunction("mysplit",MySplit.class);
tenv.executeSql("select t.id, t.name, tag from t, lateral table(mysplit(tags)) ")/*.print()*/;
tenv.executeSql("select t.id, t.name, x.tag2 from t, lateral table(mysplit(tags)) x(tag2)")/*.print()*/;
tenv.executeSql("select t.id, t.name, tag from t left join lateral table(mysplit(tags)) on true")/*.print()*/;
tenv.executeSql("select t.id, t.name, x.tag2 from t left join lateral table(mysplit(tags)) x(tag2) on true").print();
}
@FunctionHint(output = @DataTypeHint("ROW<tag string>"))
public static class MySplit extends TableFunction<Row> {
public void eval(String[] arr){
for (String s : arr) {
collect(Row.of(s));
}
}
}
over 窗口聚合
row_number( ) over ( )
flinksql 中,over 聚合时,指定聚合数据区间有两种方式
-
方式 1,带时间设定区间
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW -
方式 2,按行设定区间
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW














 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









