







SparkSQL 是如何将SQL语句转化为Spark任务的呢?
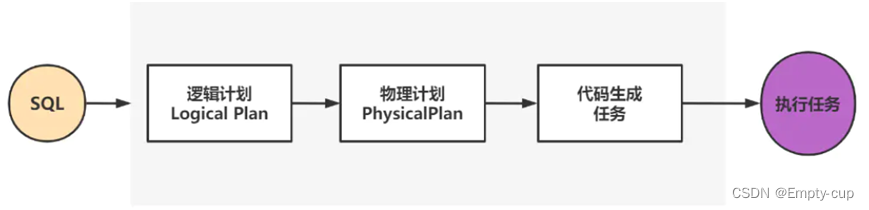
详细过程如下图
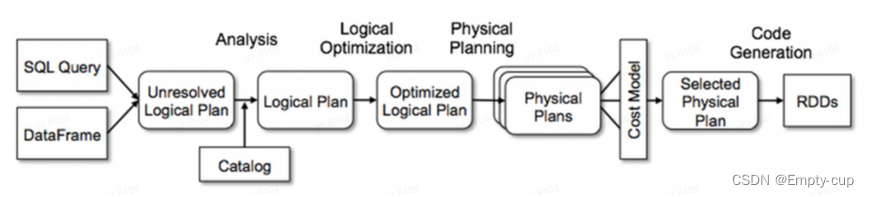
主要流程大概可以分为以下几步:
- Sql语句经过Antlr4解析,生成Unresolved Logical Plan;
- Analyzer与Catalog进行绑定(Catlog存储元数据),生成Logical Plan;
- optimizer对Logical Plan优化,生成Optimized LogicalPlan;
- SparkPlan将Optimized LogicalPlan转换成 Physical Plan;
- prepareForExecution() 将 Physical Plan 转换成 executed Physical Plan;
- execute()执行可执行物理计划,得到RDD;

通过拉去 github 的 Spark 源码,查看 SparkSQL 模块的 readme.txt 文件可以看出,SparkSQL 包含4个方面的内容
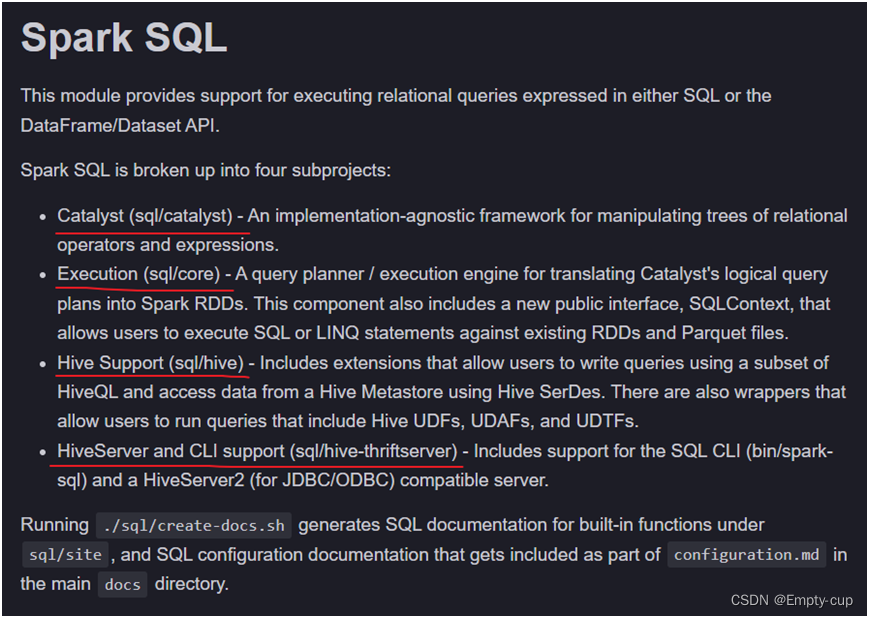
SparkSQL源码主要包含4大模块
- Catalyst (sql/catalyst):sql词法语法解析、绑定、逻辑执行计划优化。
- Execution (sql/core):查询规划器/执行引擎,用于将Catalyst的逻辑查询计划转换为Spark RDD。
- Hive Support (sql/hive):负责对hive数据的处理逻辑,包括允许用户使用HiveQL子集编写查询和使用HiveSerdes从HiveMetastore访问数据的扩展。还有一些包装器允许用户运行包含配置单元UDF、UDAFs和UDTFs的查询。
- HiveServer and CLI support (sql/hive-thriftserver):提供client和JDBC/ODBC接口,包括对SQL CLI(bin/spark-sql)和HiveServer2(用于JDBC/ODBC)兼容服务器的支持。
什么是Catalyst ?
Catalyst 负责解析 SQL,生成执行计划,具体过程包括:
- 解析SQL,生成抽象语法树(AST)
- 在 AST 中加入元数据信息,生成逻辑执行计划
- 对已经加入元数据的 AST,输入优化器,进行规则优化(RBO) ,生成优化后的逻辑执行计划。
哪些阶段属于Catalyst ?
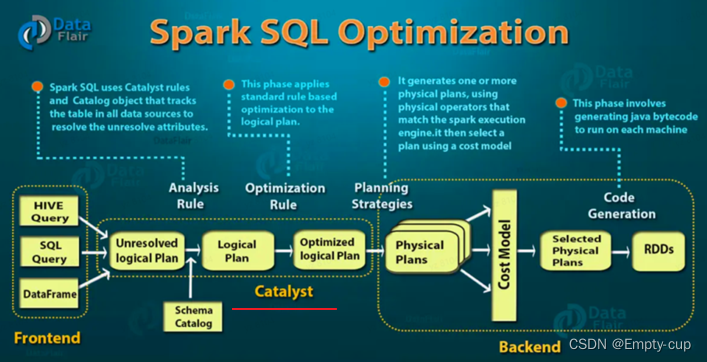
Catalyst 作用是什么?
首先,RDD大致运行步骤:先将 RDD 解析为由 Stage 组成的 DAG,后将 Stage 转为 Task 运行。任务会按照代码所示运行,重度依赖开发者的优化,开发者会在很大程度上影响运行效率。
与 RDD 不同,SparkSQL 可以获知数据的 Schema 来进行优化,SparkSQL 的 DSL 和 SQL 并不是直接生成计划交给集群执行,而是经过了一个叫做 Catalyst 的优化器,这个优化器能够自动帮助开发者优化代码。SparkSQL 中正是由于 Catalyst 优化器存在,使得无论基于SQL还是DSL分析数据,性能都是一样的,并且底层做了很多优化。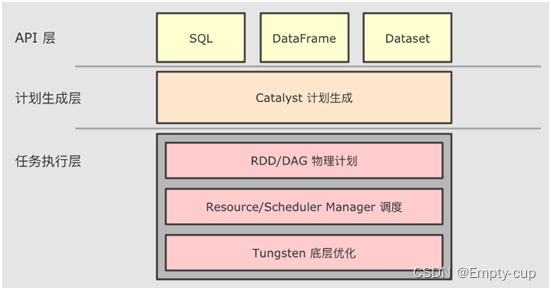














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









