







 K-Means算法是一种广泛应用的聚类算法,通过迭代找到使平均误差准则函数达到最优的类别划分。该算法依赖于点群中心的计算,包括欧几里得距离和曼哈顿距离。然而,K-Means存在对初始值敏感、需要预设簇数量和对噪声数据敏感等缺陷。K-Means++是为解决这些问题而提出的改进方法,通过加权方式选择种子点以提高聚类质量。
K-Means算法是一种广泛应用的聚类算法,通过迭代找到使平均误差准则函数达到最优的类别划分。该算法依赖于点群中心的计算,包括欧几里得距离和曼哈顿距离。然而,K-Means存在对初始值敏感、需要预设簇数量和对噪声数据敏感等缺陷。K-Means++是为解决这些问题而提出的改进方法,通过加权方式选择种子点以提高聚类质量。
聚类与分类
聚类(clustering)是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
在分类( classification )中,对于目标数据库中存在哪些类是知道的,要做的就是将每一条记录分别属于哪一类标记出来。
聚类分析也称无监督学习, 因为和分类学习相比,聚类的样本没有标记,需要由聚类学习算法来自动确定。聚类分析是研究如何在没有训练的条件下把样本划分为若干类。
K-Means 算法
K-means算法, 也被称为k-平均或k-均值算法,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优(平均误差准则函数E ),从而使生成的每个聚类(又称簇)内紧凑,类间独立。
, 该算法最常见的形式是采用被称为劳埃德算法(Lloyd algorithm)的迭代式改进探索法。劳埃德算法首先把输入点分成k个初始化分组,可以是随机的或者使用一些启发式数据。然后计算每组的中心点,根据中心点的位置把对象分到离它最近的中心,重新确定分组。继续重复不断地计算中心并重新分组,直到收敛,即对象不再改变分组(中心点位置不再改变)。
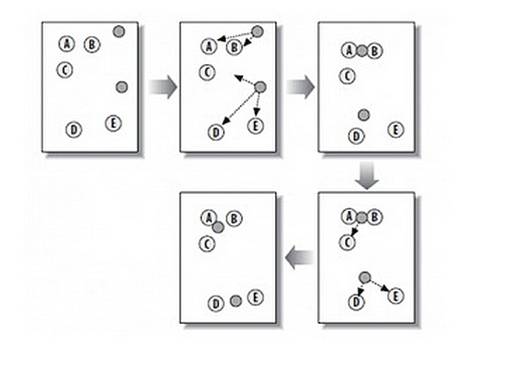
1. 计算两个类别,初始化两个类别
2. 每个种子点都计算与另外所有的白色点的距离
3. 对于白点pi,若种子点si距离pi最近,则si属于pi
4. 重新计算求中心点 xn=(x1+x2+x3)/3,yn=(y1+y2+y3)/3
迭代至类别无变化求点群中心的算法
Minkowski Distance (闵可夫斯基距离)
Euclidean Distance(欧几里得距离)
Manhattan Distance(曼哈顿距离)
闵可夫斯基距离
闵氏距离不是一种距离,而是一组距离的定义
闵氏距离的定义:
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
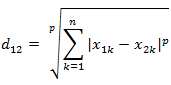
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离根据变参数的不同,闵氏距离可以表示一类的距离。
欧几里得距离
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离
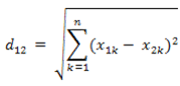
曼哈顿距离
曼哈顿距离——两点在南北方向上的距离加上在东西方向上的距离,即d(i,j)=|xi-xj|+|yi-yj|。对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离因此曼哈顿距离又称为出租车距离
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的曼哈顿距离
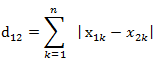
算法缺陷
在簇的平均值被定义的情况下才能使用,这对于处理符号属性的数据不适用。
必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。经常发生得到次优划分的情况。解决方法是多次尝试不同的初始值。
它对于“躁声”和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响
K-Means++
先从我们的数据库随机挑个随机点当“种子点”。
对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,**先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
重复第(2)和第(3)步直到所有的K个种子点都被选出来。
进行K-Means算法。**
package org.bigdata.mapreduce.kmeans;
import java.io.IOException;
import java.util.Map.Entry;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import org.bigdata.util.HadoopCfg;
/**
* 计算种子点
*
* @author wwhhf
*
*/
public class ClusterMapReduce {
/**
* 2,1,3,4,1,4
*
* @author wwhhf
*
*/
public static class ClusterMapper extends
Mapper<LongWritable, Text, Text, DoubleWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String terms[] = value.toString().split(",");
for (int i = 0, len = terms.length; i < len; i++) {
context.write(new Text("c" + (i + 1)), new DoubleWritable(
Double.valueOf(terms[i])));
}
}
}
public static class ClusterReducer extends
Reducer<Text, DoubleWritable, Text, Text> {
@Override
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8775
8775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









