







一、CPU引入缓存
我们知道处理器的处理速度很快,内存处理速度远远赶不上处理器的处理速度,为了解决CPU处理速度和内存处理速度不对等的问题,我们引入了CPU Cache
CPU架构图
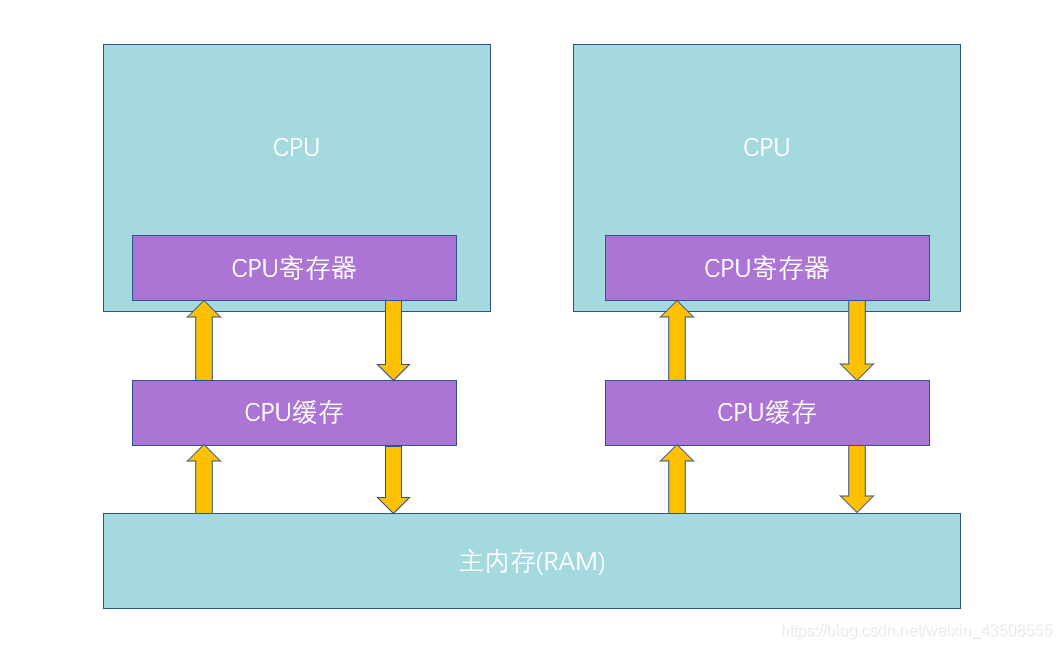
二、CPU工作原理
- 首先CPU工作的时候,由控制单元充当大脑,负责协调。
- 让运算单元做运算的时候,会首先从最靠近CPU的寄存器(其实是和CPU一体的)上读取数据,在寄存器上有CPU运行的常用指令
- 如果寄存器上没有想要的数据,则就从三级缓存的L1级缓存中获取,如果L1取到数据了,会加载到寄存器中,再转输给CPU运算单元。
- 如果L1中没有,则从L2级缓存中读取,同理,如果没有,则从L3中取。
- 如果L3中也没有,这个时候,就比较麻烦了。要从主内存中取。
- 而从主内存中取的时候,会经过系统总线及内存总线,这时因受到总线的限制,速度会大大降低。而且会存在众多问题
三、为什么要加载缓存
从主内存中取的时候,会经过系统总线及内存总线,这时因受到总线的限制,速度会大大降低。而且会存在众多问题。读入缓存,下次用时从缓存读取,效率会大大提高
缓存一致性协议-MESI
如何解决缓存不一致性问题
为是什么会不一致?
- 如果cpu1改变了从主内存中读取的一个数据,而cpu2也刚好访问同一块区域也需要读取这个数据,那么读到的就会是未改变的值,造成缓存不一致
那么为了解决一致性的问题,需要各个处理器访问缓存时都 遵循一些协议,在读写时要根据协议来进行操作。常用的方法是总线加锁或是缓存一致性协议-MESI
MESI是四种状态
M:修改
E: 独享
S: 共享
I: 无效
MESI缓存一致性协议原理
- 假如现在有CPU1和CPU2,主内存有变量X= 1 。现在要做 x+1的操作。
- 当CPU1从主内存中读取到X=1时,CPU1会把此变量标记成独享状态
- 并监听总线,是否有其它CPU去读取此变量
- 当CPU2从主内存中读取X=1变量时,CPU1会通过嗅探机制监听到。
- 此时CPU1的X变量会变成共享状态,通知其他缓存状态的变动,CPU2的状态都为共享状态。继续进行计算,计算完变成X=2。CPU2查询x变量,会延迟等到CPU1同步数据。
- 此时要回写到主内存之前。先锁住缓存行。并标记X变量为修改状态。并向总线发消息。
- 其它CPU2监听总线时,会监听到,并把X标记成无效状态。
- CPU1把变量X=2回写到主内存后,会由修改状态变成独享状态。
此时,如果CPU2如果想修改X变量时,要重启从主内存中读取。然后开始新的轮回
MESI引入之后的问题以及优化
- 存储缓存
- 失效队列
存储缓存(Store buffer)
修改状态之后,等到其他缓存收到消息完成各自的切换并且发出回应消息,这么一长串的时间,CPU都会等待所有缓存相应完成。
CPU切换状态阻塞解决- 存储缓存(store buffers)
处理器把它想要写入到主存的值写到缓存(store buffers),然后继续处理其他事情,当所有失效确认都接收到时,数据才最终被提交写入到cache中
这种方式存在的风险:
- 当再次读取值时,返现缓存的值还没有提交,读取到值后直接返回。
- 保存什么时候完成,并没有任何保证
失效队列(Invalidate Queue)
执行失效也不是一个简单的操作,它需要处理器去处理。另外,存储缓存(Store Buffers)并不是无穷大的,所以处理器有时需要等待失效确认的返回。这两个操作都会使得性能大幅降低。为了应付这种情况,引入了失效队列。无效队列的作用就是CPU接收到validate广播的时候马上返回给对方validate ack响应。等当前的操作执行完再回来真正的把缓存里面的值标识为validate状态。它们的约定如下:
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送
- Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate
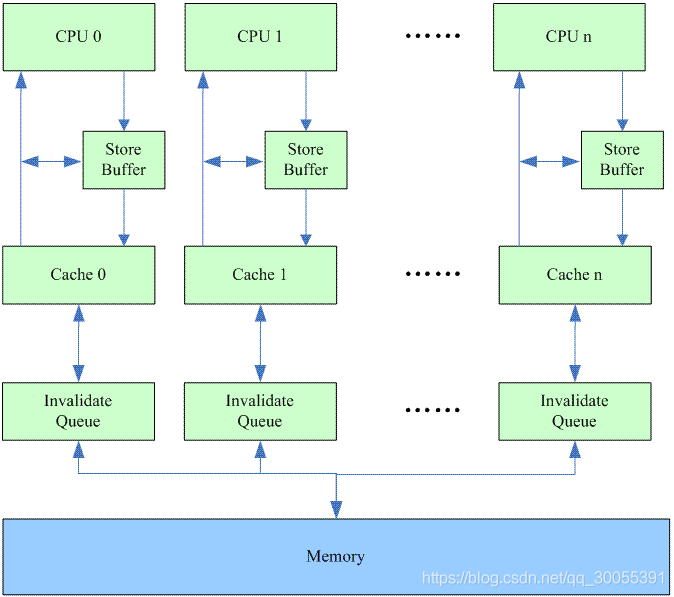
存储缓存和无效队列存在的问题
存储缓存是对方CPU还没有给我们回答的时候我们已经执行下一步代码
无效队列是对方CPU还有没有将值的状态修改为无效,就读取返回。 当一个CPU尝试读取实际已经失效但未执行 Invalidate Acknowledge 的数据时,会导致数据不一致
他们的引入带来了内存重排序和可见性的问题
由于 存储缓存和无效队列 的引入,导致 存储缓存写入缓存行和执行失效队列的时机需要十分合适才能尽可能释放CPU的处理能力,实际上CPU并不知道什么时候会执行,因此将这个任务留给了写程序的人,这就是我们常说的内存屏障
flush指令和reflush指令
为解决内存可见性问题,新增两条指令来保证
flush: 当读操作时,强制将无效队列刷新到缓存区中
reflush:当写操作时,强制将写缓存区写入到内存去中
内存屏障
内存屏障:是CPU或编译器对内存随机访问的操作的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行之后的操作。
- 写屏障 是一条告诉处理器在执行这之后的指令之前,应用所有已经在 存储缓存中的保存的指令到缓存行中。
- 读屏障是一条告诉处理器在执行任何的加载前,应用所有已经在失效队列中的失效操作的指令。
void executedOnCpu0() {
value = 10;
// 在更新数据之前必须将所有存储缓存(store buffer)中的指令执行完毕。
storeMemoryBarrier();
finished = true;
}
void executedOnCpu1() {
while(!finished);
// 在读取之前将所有失效队列中关于该数据的指令执行完毕。
loadMemoryBarrier();
assert value == 10;
}















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









