










正则表达式的先行断言和后行断言一共有 4 种形式:
- (?=pattern) 零宽正向先行断言(zero-width positive lookahead assertion)
- (?!pattern) 零宽负向先行断言(zero-width negative lookahead assertion)
- (?<=pattern) 零宽正向后行断言(zero-width positive lookbehind assertion)
- (?<!pattern) 零宽负向后行断言(zero-width negative lookbehind assertion)
这里面的 pattern 是一个正则表达式。
如同 ^ 代表开头,$ 代表结尾,\b 代表单词边界一样,先行断言和后行断言也有类似的作用,它们只匹配某些位置,在匹配过程中,不占用字符,所以被称为"零宽"。所谓位置,是指字符串中(每行)第一个字符的左边、最后一个字符的右边以及相邻字符的中间(假设文字方向是头左尾右)。
下面分别举例来说明这 4 种断言的含义。
(?=pattern) 正向先行断言
代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配 pattern。
例如对 "a regular expression" 这个字符串,要想匹配 regular 中的 re,但不能匹配 expression 中的 re,可以用 re(?=gular),该表达式限定了 re 右边的位置,这个位置之后是 gular,但并不消耗 gular 这些字符。
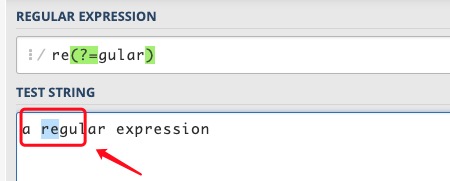
将表达式改为 re(?=gular).,将会匹配 reg,元字符 . 匹配了 g,括号这一砣匹配了 e 和 g 之间的位置。
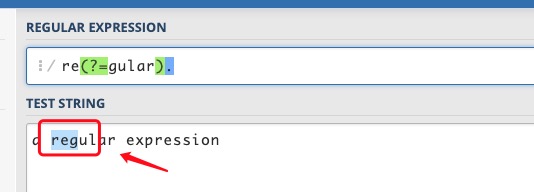
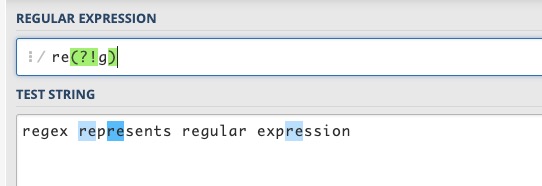
(?!pattern) 负向先行断言
代表字符串中的一个位置,紧接该位置之后的字符序列不能匹配 pattern。
例如对 "regex represents regular expression" 这个字符串,要想匹配除 regex 和 regular 之外的 re,可以用 re(?!g),该表达式限定了 re 右边的位置,这个位置后面不是字符 g。
负向和正向的区别,就在于该位置之后的字符能否匹配括号中的表达式。
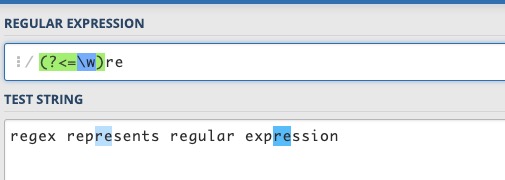
(?<=pattern) 正向后行断言
代表字符串中的一个位置,紧接该位置之前的字符序列能够匹配 pattern。
例如对 regex represents regular expression 这个字符串,有 4 个单词,要想匹配单词内部的 re,但不匹配单词开头的 re,可以用 (?<=\w)re,单词内部的 re,在 re 前面应该是一个单词字符。
之所以叫后行断言,是因为正则表达式引擎在匹配字符串和表达式时,是从前向后逐个扫描字符串中的字符,并判断是否与表达式符合,当在表达式中遇到该断言时,正则表达式引擎需要往字符串前端检测已扫描过的字符,相对于扫描方向是向后的。
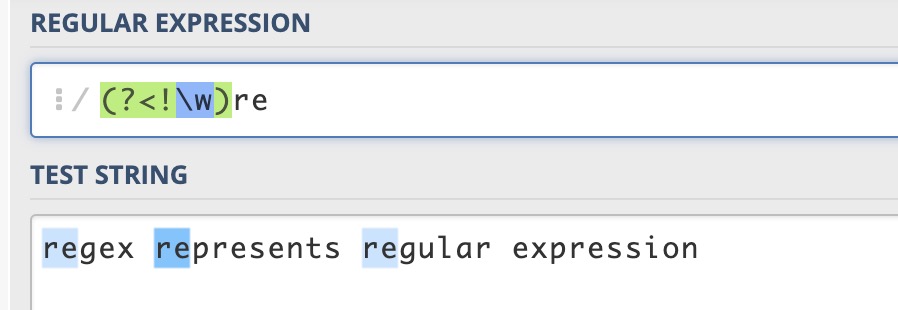
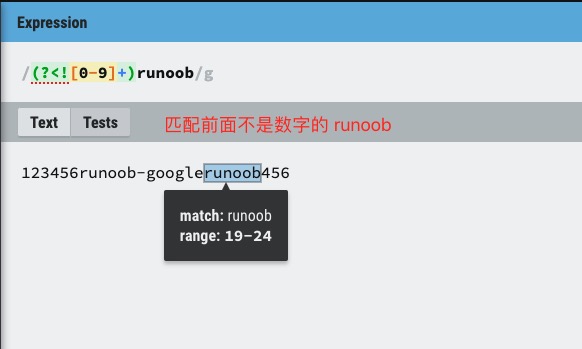
(?<!pattern) 负向后行断言
代表字符串中的一个位置,紧接该位置之前的字符序列不能匹配 pattern。
例如对 "regex represents regular expression" 这个字符串,要想匹配单词开头的 re,可以用 (?<!\w)re。单词开头的 re,在本例中,也就是指不在单词内部的 re,即 re 前面不是单词字符。当然也可以用 \bre 来匹配。
对于这 4 个断言的理解,可以从两个方面入手:
-
1、关于先行(lookahead)和后行(lookbehind):正则表达式引擎在执行字符串和表达式匹配时,会从头到尾(从前到后)连续扫描字符串中的字符,设想有一个扫描指针指向字符边界处并随匹配过程移动。先行断言,是当扫描指针位于某处时,引擎会尝试匹配指针还未扫过的字符,先于指针到达该字符,故称为先行。后行断言,引擎会尝试匹配指针已扫过的字符,后于指针到达该字符,故称为后行。
-
2、关于正向(positive)和负向(negative):正向就表示匹配括号中的表达式,负向表示不匹配。
对这 4 个断言形式的记忆:
-
1、先行和后行:后行断言 (?<=pattern)、(?<!pattern) 中,有个小于号,同时也是箭头,对于自左至右的文本方向,这个箭头是指向后的,这也比较符合我们的习惯。把小于号去掉,就是先行断言。
-
2、正向和负向:不等于 (!=)、逻辑非 (!) 都是用 !号来表示,所以有 ! 号的形式表示不匹配、负向;将 ! 号换成 = 号,就表示匹配、正向。
我们经常用正则表达式来检测一个字符串中包含某个子串,要表示一个字符串中不包含某个字符或某些字符也很容易,用 [^...] 形式就可以了。要表示一个字符串中不包含某个子串(由字符序列构成)呢?
用 [^...] 这种形式就不行了,这时就要用到(负向)先行断言或后行断言、或同时使用。
例如判断一句话中包含 this,但不包含 that。
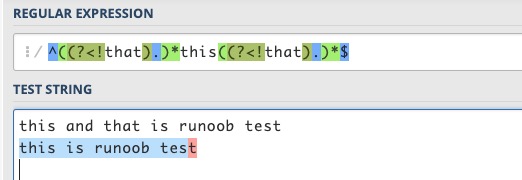
包含 this 比较好办,一句话中不包含 that,可以认为这句话中每个字符的前面都不是 that 或每个字符的后面都不是 that。正则表达式如下:
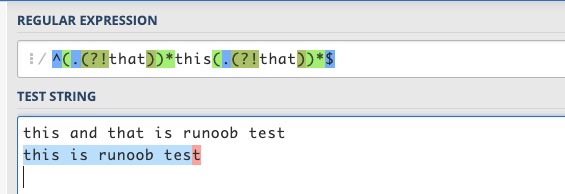
^((?<!that).)*this((?<!that).)*$ 或 ^(.(?!that))*this(.(?!that))*$
对于 this is runoob test 这句话,两个表达式都能够匹配成功,而 this and that is runoob test 都匹配失败。
在一般情况下,这两个表达式基本上都能够满足要求了。考虑极端情况,如一句话以 that 开头、以 that 结尾、that 和 this 连在一起时,上述表达式就可能不胜任了。 如 runoob thatthis is the case 或者 this is the case, not that 等。
只要灵活运用这几个断言,就很容易解决:
^(.(?<!that))*this(.(?<!that))*$ ^(.(?<!that))*this((?!that).)*$ ^((?!that).)*this(.(?<!that))*$ ^((?!that).)*this((?!that).)*$
这 4 个正则表达式测试上述的几句话,结果都能够满足要求。
上述 4 种断言,括号里的 pattern 本身是一个正则表达式。但对 2 种后行断言有所限制,在 Perl 和 Python 中,这个表达式必须是定长(fixed length)的,即不能使用 *、+、? 等元字符,如 (?<=abc) 没有问题,但 (?<=a*bc) 是不被支持的,特别是当表达式中含有|连接的分支时,各个分支的长度必须相同。之所以不支持变长表达式,是因为当引擎检查后行断言时,无法确定要回溯多少步。Java 支持 ?、{m}、{n,m} 等符号,但同样不支持 *、+ 字符。Javascript 干脆不支持后行断言,不过一般来说,这不是太大的问题。
先行断言和后行断言某种程度上就好比使用 if 语句对匹配的字符前后做判断验证。
以下列出 ?=、?<=、?!、?<!= 的使用
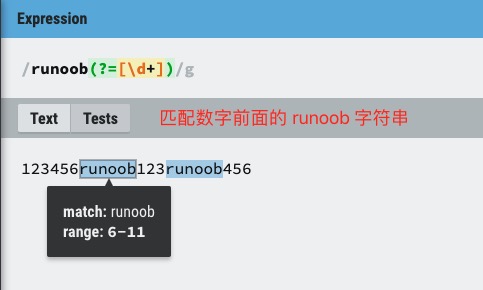
exp1(?=exp2):查找 exp2 前面的 exp1。
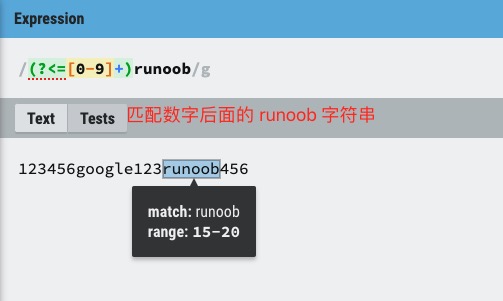
(?<=exp2)exp1:查找 exp2 后面的 exp1。
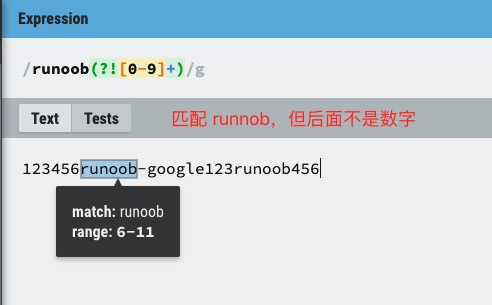
exp1(?!exp2):查找后面不是 exp2 的 exp1。
(?<!=exp2)exp1:查找前面不是 exp2 的 exp1。
正则表达式基本知识:
– 基本语法
– 高级语法
– 练习
– editplus,notpad++,ultraedit,eclipse中使用正则
• JAVA复杂文本操作
正则表达式实用语法大全
正则表达式基本符号:
^ 表示匹配字符串的开始位置 (例外 用在中括号中[ ] 时,可以理解为取反,表示不匹配括号中字符串)
$ 表示匹配字符串的结束位置
* 表示匹配 零次到多次
+ 表示匹配 一次到多次 (至少有一次)
? 表示匹配零次或一次
. 表示匹配单个字符
| 表示为或者,两项中取一项
( ) 小括号表示匹配括号中全部字符
[ ] 中括号表示匹配括号中一个字符 范围描述 如[0-9 a-z A-Z]
{ } 大括号用于限定匹配次数 如 {n}表示匹配n个字符 {n,}表示至少匹配n个字符 {n,m}表示至少n,最多m
\ 转义字符 如上基本符号匹配都需要转义字符 如 \* 表示匹配*号
\w 表示英文字母和数字 \W 非字母和数字
\d 表示数字 \D 非数字
常用的正则表达式
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配IP地址的正则表达式:/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
sql语句:^(select|drop|delete|create|update|insert).*$
1、非负整数:^\d+$
2、正整数:^[0-9]*[1-9][0-9]*$
3、非正整数:^((-\d+)|(0+))$
4、负整数:^-[0-9]*[1-9][0-9]*$
5、整数:^-?\d+$
6、非负浮点数:^\d+(\.\d+)?$
7、正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
8、非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$
9、负浮点数:^(-((正浮点数正则式)))$
10、英文字符串:^[A-Za-z]+$
11、英文大写串:^[A-Z]+$
12、英文小写串:^[a-z]+$
13、英文字符数字串:^[A-Za-z0-9]+$
14、英数字加下划线串:^\w+$
15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$
17、邮政编码:^[1-9]\d{5}$
18、中文:^[\u0391-\uFFE5]+$
19、电话号码:^((\d2,3)|(\d{3}\-))?(0\d2,3|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$
20、手机号码:^((\d2,3)|(\d{3}\-))?13\d{9}$
21、双字节字符(包括汉字在内):^\x00-\xff
22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)
23、匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>
24、匹配空行:\n[\s| ]*\r
25、提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
26、提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
27、提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
29、提取信息中的中国手机号码:(86)*0*13\d{9}
30、提取信息中的中国固定电话号码:(\d3,4|\d{3,4}-|\s)?\d{8}
31、提取信息中的中国电话号码(包括移动和固定电话):(\d3,4|\d{3,4}-|\s)?\d{7,14}
32、提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
33、提取信息中的浮点数(即小数):(-?\d*)\.?\d+
34、提取信息中的任意数字 :(-?\d*)(\.\d+)?
35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)
36、电话区号:/^0\d{2,3}$/
37、腾讯QQ号:^[1-9]*[1-9][0-9]*$
38、帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
39、中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$
• 为什么需要正则表达式?
– 文本的复杂处理。
• 正则表达式的优势和用途?
– 一种强大而灵活的文本处理工具;
– 大部分编程语言 、 数据库、 文本编辑器、 开发环境都支持正则表达式。
• 正则表达式定义:
– 正如他的名字一样是描述了一个规则, 通过这个规则可以匹配一类字符串。
– 学习正则表达式很大程度上就是学习正则表达式的 语法规则 。
• 开发中使用正则表达式的流程:
– 分析所要匹配的数据, 写出测试用的典型数据
– 在工具软件中进行匹配测试
– 在程序中调用通过测试的正则表达式
• 普通字符
– 字母、 数字、 汉字、 下划线、 以及没有特殊定义的标点符
号, 都是 “普通字符” 。 表达式中的普通字符, 在匹配一
个字符串的时候, 匹配与之相同的一个字符 。
• 简单的转义字符
\n 代表换行符
\t 制表符
\\ 代表 \ 本身
\^ , \$,\. , \( , \) , \{ , \} , \? , \+ , \* ,
\| , \[ , \]
匹配这些字符本身
• 标准字符集合 :
– 能够与 ‘多种字符’ 匹配的表达式
– 注意区分大小写, 大写是相反的意思
\d 任意一个数字, 0~9 中的任意一个
\w 任意一个字母或数字或下划线, 也就是 A~Z,a~z,0~9,_ 中任意一个
\s 包括空格、 制表符、 换行符等空白字符的其中任意一个
.
小数点可以匹配任意一个字符 ( 除了换行符 )
如果要匹配包括“ \n” 在内的所有字符, 一般用 [\s\S]
• 自定义字符集合 :
– [ ]方括号匹配方式, 能够匹配方括号中 任意一个 字符
– 正则表达式的特殊符号, 被包含到中括号中, 则失去特殊意义, 除了
^,-之外。
– 标准字符集合, 除小数点外, 如果被包含于中括号, 自定义字符集合
将包含该集合。 比如:
• [\d.\-+]将匹配: 数字、 小数点、 +、 -
[ab5@] 匹配 "a" 或 "b" 或 "5" 或 "@"
[^ abc] 匹配 "a","b","c" 之外的任意一个字符
[f-k] 匹配 "f"~"k" 之间的任意一个字母
[^A-F0-3] 匹配 "A"~"F","0"~"3" 之外的任意一个字符
• 量词( Quantifier)
– 修饰匹配次数的特殊符号
• 匹配次数中的 贪婪模式(匹配字符越多越好, 默认!)
• 匹配次数中的 非贪婪模式( 匹配字符越少越好, 修饰匹配次数
的特殊符号后再加上一个 "?" 号)
{n} 表达式重复 n 次
{m,n} 表达式至少重复 m 次, 最多重复 n 次
{m,} 表达式至少重复 m 次
? 匹配表达式 0 次或者 1 次, 相当于 {0,1}
+ 表达式至少出现 1 次, 相当于 {1,}
* 表达式不出现或出现任意次, 相当于 {0,}
• 字符边界
– (本组标记匹配的不是字符而是位置, 符合某种条件的位置)
– \b匹配这样一个位置: 前面的字符和后面的字符不全是\w
^ 与字符串开始的地方匹配
$ 与字符串结束的地方匹配
\b 匹配一个单词边界
• IGNORECASE 忽略大小写模式
– 匹配时忽略大小写。
– 默认情况下, 正则表达式是要区分大小写的。
• SINGLELINE 单行模式
– 整个文本看作一个字符串, 只有一个开头, 一个结尾。
– 使小数点 "." 可以匹配包含换行符(\n) 在内的任意字符。
• MULTILINE 多行模式
– 每行都是一个字符串, 都有开头和结尾。
– 在指定了 MULTILINE 之后, 如果需要仅匹配字符串开始和结束位置, 可以使
用 \A 和 \Z
• 选择符和分组
• 反向引用(\nnn)
– 每一对()会分配一个编号, 使用 () 的捕获 根据左括号的顺序从 1 开始自动编号 。
– 通过反向引用, 可以对 分组已捕获的字符串 进行引用。
表达式 作用
|
分支结构
左右两边表达式之间 " 或 " 关系, 匹配左边或者右边
( )
捕获组
(1). 在被修饰匹配次数的时候, 括号中的表达式可以作为整体被修饰
(2). 取匹配结果的时候, 括号中的表达式匹配到的内容可以被单独得到
(3). 每一对括号会分配一个编号, 使用 () 的捕获根据左括号的顺序从 1
开始自动编号。 捕获元素编号为零的第一个捕获是由整个正则表达式模式
匹配的文本
(?:Expression)
非捕获组
一些表达式中, 不得不使用 ( ) , 但又不需要保存 ( ) 中子表达式匹
配的内容, 这时可以用非捕获组来抵消使用 ( ) 带来的副作用。
• 预搜索(零宽断言)
– 只进行子表达式的匹配, 匹配内容不计入最终的匹配结果, 是零宽度
– 这个位置应该符合某个条件。 判断当前位置的前后字符, 是否符合指
定的条件, 但不匹配前后的字符。 是对位置的匹配。
– 正则表达式匹配过程中, 如果子表达式匹配到的是字符内容, 而非位置, 并被
保存到最终的匹配结果中, 那么就认为这个子表达式是占有字符的; 如果子表
达式匹配的仅仅是位置, 或者匹配的内容并不保存到最终的匹配结果中, 那么
就认为这个子表达式是 零宽度 的。 占有字符还是零宽度, 是针对匹配的内容是
否保存到最终的匹配结果中而言的。
(?=exp) 断言自身出现的位置的后面能匹配表达式 exp
(? 断言自身出现的位置的前面能匹配表达式 exp
(?!exp) 断言此位置的后面不能匹配表达式 exp
(? 断言此位置的前面不能匹配表达式 exp
• 电话号码 验证
– (1)电话号码由数字和"-"构成
– (2)电话号码为7到8位
– (3)如果电话号码中包含有区号, 那么区号为三位或四位, 首位是0.
– (4)区号用"-"和其他部分隔开
– (5)移动电话号码为11位
– (6)11位移动电话号码的第一位和第二位为"13“,” 15” ,” 18”
• 电子邮件地址验证
– 1.用户名: 字母、 数字、 中划线、 下划线组成。
– 2.@
– 3.网址: 字母、 数字组成。
– 4. 小数点: .
– 5. 组织域名:2-4位字母组成。
– 不区分大小写匹配中文字符 [\u4e00-\u9fa5]
匹配空白行 \n\s*\r
匹配 HTML 标记 ]*>.*?|
匹配首尾空白字符 ^\s*|\s*$
匹配 Email 地址 \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址 URL [a-zA-z]+://[^\s]*
匹配国内电话号码 \d{3}-\d{8}|\d{4}-\d{7}
匹配腾讯 QQ 号 [1-9][0-9]{4,}
匹配中国邮政编码 [1-9]\d{5}(?!\d)
匹配身份证 \d{15}|\d{18}
匹配 ip 地址 \d+\.\d+\.\d+\.\d+
• 开发环境和文本编辑器中使用正则
– eclipse
– Notepad++
– Editplus
– UltraEdit
• 数据库中也可以使用正则
– Mysql5.5以上
– Oracle10g以上
– 例如:
•SELECT prod_name
FROM products
WHERE prod_name REGEXP '.000'
. 匹配任意字
符
• 相关类位于: java.util.regex 包下面
• 类 Pattern :
– 正则表达式的编译表示形式。
– Pattern p = Pattern.compile(r,int); //建立正则表达式, 并启用相应模式
• 类 Matcher :
– 通过解释 Pattern 对 character sequence 执行匹配操作的引擎
– Matcher m = p.matcher(str); //匹配str字符串


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











