







简介
什么是ceph?
Ceph在一个统一的系统中独特地提供对象、块和文件存储。Ceph 高度可靠、易于管理且免费。Ceph 的强大功能可以改变您公司的 IT 基础架构和管理大量数据的能力。Ceph 提供了非凡的可扩展性——数以千计的客户端访问 PB 到 EB 的数据。ceph存储集群相互通信以动态复制和重新分配数据。
为什么使用ceph?
目前众多云厂商都在使用ceph,应用广泛。如:华为、阿里、腾讯等等。目前火热的云技术openstack、kubernetes都支持后端整合ceph,从而提高数据的可用性、扩展性、容错等能力。
一个 Ceph 存储集群至少需要一个Ceph Monitor(监视器)、Ceph Manager(管理) 和 Ceph OSD(对象存储守护进程)。

- Monitors
Ceph Monitor ( ceph-mon) 维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射、MDS 映射和 CRUSH 映射。这些映射是 Ceph 守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常需要至少三个监视器。
- Managers
Ceph Manager守护进程 ( ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。高可用性通常需要至少两个管理器。
- Ceph OSD
一个Ceph OSD(ceph-osd)存储数据、处理数据复制、恢复、重新平衡,并通过检查其他 Ceph OSD 守护进程的心跳来向 Ceph 监视器和管理器提供一些监视信息。冗余和高可用性通常需要至少三个 Ceph OSD。
- MDS
Ceph 元数据服务器(MDS ceph-mds) 代表Ceph 文件系统存储元数据(即 Ceph 块设备和 Ceph 对象存储不使用 MDS)。Ceph 元数据服务器允许 POSIX 文件系统用户执行基本命令(如 ls、find等),而不会给 Ceph 存储集群带来巨大负担。
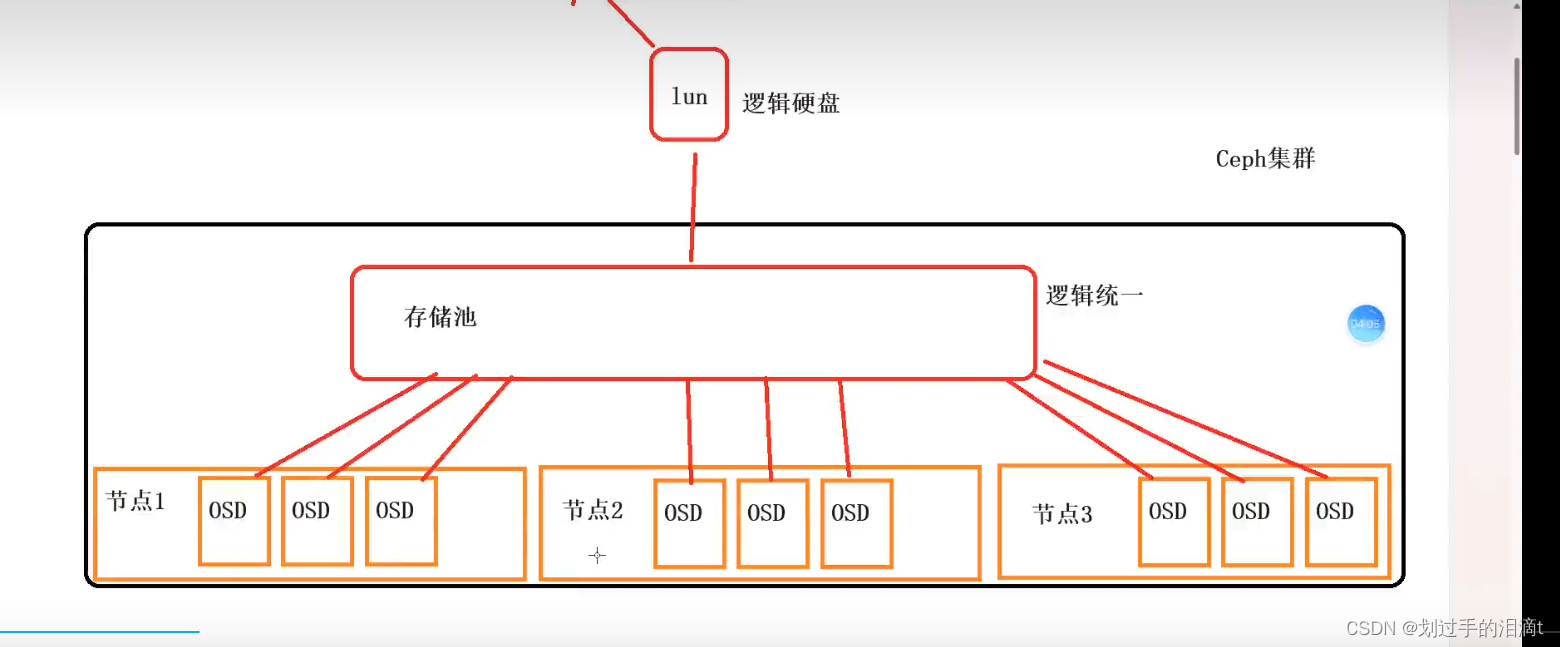
Ceph 将数据作为对象存储在逻辑存储池中。使用 CRUSH算法,Ceph 计算出哪个归置组应该包含该对象,并进一步计算出哪个 Ceph OSD Daemon 应该存储该归置组。CRUSH 算法使 Ceph 存储集群能够动态扩展、重新平衡和恢复。
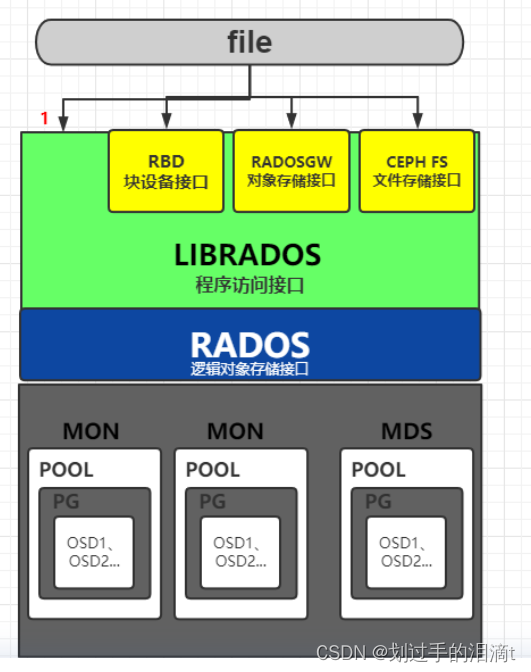
LIBRADOS: 一个允许应用程序直接访问 RADO 的库,支持 C、C++、Java、Python、Ruby 和 PHP
RADOSGW(对象网关): 基于存储桶的 REST网关,兼容s3和Swift
RBD(块存储): 一个负责任的,完全-分布式块设备,使用Linux内核cliont和QEMU/KVM驱动程序
CEPHFS(文件存储): 符合POSIX标准的分发文件系统,具有Linux内核客户端和对FUSE的支持
RADOS: 由自我修复、自我管理、智能存储节点组成的可靠、自主、分布式对象存储
POOL、PG简介
1、POOLS: 存储池,它们是用于存储对象的逻辑分区。
Ceph 客户端从 Ceph 监视器检索集群映射,并将对象写入池中。池size或副本的数量、CRUSH 规则和归置组的数量决定了 Ceph 将如何放置数据。
池至少设置以下参数:
- 对象的所有权/访问权
- 归置组的数量
- 要使用的 CRUSH 规则
2、PG:每个池都有许多归置组。CRUSH 将 PG 动态映射到 OSD。
当 Ceph 客户端存储对象时,CRUSH 会将每个对象映射到一个归置组。
使用集群映射的副本和 CRUSH 算法,客户端可以准确计算在读取或写入特定对象时使用哪个 OSD。
Ceph对于集群内PG的总个数有如下公式:
(OSD个数\*100)/ 副本数 = PGs
以上公式计算得出结果后,再取一个与之较大的2的幂的值,便可作为集群的总PG数。例如,一个配置了200个OSD且副本数为3的集群,计算过程如下:
(200\*100)/3 = 6667. Nearest power of 2 : 8192
得到8192后,可以根据集群内所需建立的POOL的个数及用途等要素,进行PG划分。
l若少于5个OSD, 设置pg_num为128。
l5~10个OSD,设置pg_num为512。
l10~50个OSD,设置pg_num为4096。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5239
5239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









