







引子:
工作中遇到这样的问题,调用alloc_pages(GFP_KERNEL, 13),返回值为NULL,并且打印告警。使用cat /proc/buddyinfo 命令查看,最大为2的10次方,将13改为10,函数成功调用。
引.1 alloc_pages函数
alloc_pages 是 Linux 内核中用于分配物理内存页面的函数。它通常用于内核模块、驱动程序等需要直接访问物理内存的场景。alloc_pages 函数可以分配一个或多个连续的物理页面,并且分配的页面个数只能是2的整数次幂。在Linux 中,内存管理是非常核心和复杂的一部分,其中 alloc_pages 函数处于内核内存管理的最底层。无论slab、vmalloc、kmalloc、mmap、brk 还是 page cache、buffer,都需要通过 alloc_pages 获取最基本的物理内存 pages。
函数原型如下:
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);参数解释:
gfp_mask:这是一个标志掩码,用于指定内存分配的策略和行为。不同的 gfp_mask 值表示不同的内存分配类型,例如:是否可以睡眠、是否需要回收页面、是否允许从高端内存区域分配等。
order:这是一个无符号整数,表示要分配的物理页面的数量。例如,order 为3表示分配2^3=8个连续的物理页面,一般一个页的大小为4kB,所以order为3时表示分配32kB的内存。
返回值
如果成功,alloc_pages 返回一个指向分配的第一个 struct page 的指针。如果失败,返回 NULL。
函数功能
alloc_pages 的主要功能是从物理内存中分配指定数量的连续页面。这些页面可用于各种目的,例如缓冲区、缓存、映射等。
page_address 是 Linux 内核中的一个宏,用于获取物理页面的逻辑地址。在 Linux 中,物理内存页面是通过 page 结构体来表示的,而 page_address 宏的作用就是将一个指向 page 结构体的指针转换为该页面的逻辑地址,这个逻辑地址是该页面的虚拟地址,可以用于访问和操作该页面。
引.2 /proc/buddyinfo文件
/proc/buddyinfo 是 Linux 内核中 Buddy 算法的输出文件,用于显示内存空闲和分配情况,帮助管理员和开发者更好地了解和管理系统的内存资源。
cat buddyinfo结果示例:
[root@100ask:/proc]# cat buddyinfo
Node 0, zone Normal 13 9 4 4 3 5 3 1 3 3 3 3 1 8Node 0: 表示这是第一个NUMA节点。如果你的系统有多个处理器和内存节点,那么每个节点都会有一个对应的条目。
zone Normal: 表示这是Normal内存区域,这是最常见的内存区域类型,用于普通的页面分配。
接下来的数字代表了从Order 0到Order 15的空闲页面块的数量。在这个例子中,数字分别对应:
Order 0: 13
Order 1: 9
Order 2: 4
Order 3: 4
Order 4: 3
Order 5: 5
Order 6: 3
Order 7: 1
Order 8: 3
Order 9: 3
Order 10: 3
Order 11: 3
Order 12: 1
Order 13: 8
(注意:Order 14 和 Order 15 的数量没有显示,通常这意味着它们的值为0。)
这些数字表明系统中有多少连续的内存页面块是空闲的,并且可以被用来满足相应大小的内存分配请求。例如,Order 0有13个空闲页面块,每个块包含一个页面;Order 1有9个空闲块,每个块包含两个页面,依此类推。
分析这些数字可以帮助你了解系统的内存使用情况和潜在的碎片问题。如果高阶的块数量很少,而低阶的块数量很多,这可能意味着存在内存碎片。这是因为大型的内存分配请求可能需要高阶的连续内存块,而这些块可能由于碎片而不可用。
引.3 为什么要分配连续的物理页
DMA需要使用连续物理内存。
1.内存管理相关知识目录

2.内存的硬件电路与接口
计算机最小系统至少包含内存+机械硬盘(flash),内存读写速度快但是断电丢失,机械硬盘读写速度慢但是断电不丢失。
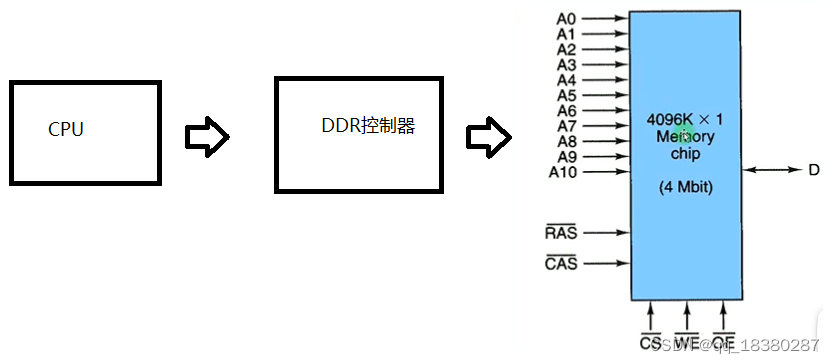
控制器将CPU发出来的地址信号转换为控制DDR的读写信号,所以设备上电后的一个重要工作的就是初始化DDR控制器。
一般CPU中会集成一块SRAM,程序先从flash中加载到SRAM中去执行,在SARM中执行的程序中会初始化DDR控制器,然后再把程序拷贝到DDR中去执行。
广义内存泄漏:多次在DDR中申请内存,导致内存中没有连续的内存空间,再次申请连续内存时失败,即内存碎片化。
狭义内存泄漏:申请内存后,没有释放。
3.物理内存管理page,zone和node
为了避免内存碎片,linux会对物理内存进行严格的管理。内存管理分为权限管理和分区管理。
3.1 页:
将物理内存划分为大小相同的块,每个块称为页帧,大小一般为4kB,也有16KB甚至更大的情况。每个页使用结构体struct page来表示。

page结构体很长,但是里面使用了很多共用体,当page用来描述不同的内存时,他是用的共用体成员是不一样的。
page结构体本身也会占用内存,在内存初始化时,对于每一个物理页帧都会定义一个page结构体来表示它,物理页帧与page结构体存在一一对应的关系。然后所有的page结构体本身也会存储在内存的某个区域上,使用全局指针mem_map指针指向page结构体存储的区域。
例如一个页是4K,那么,物理页帧号pfn = 物理地址paddr >>12(对于4K来说,右移12位相当于把页内的偏移量去掉),一般12这个数用一个宏来表示PAGE_SHIFT(2^12=4096)。
page结构体存储时,按照他们描述的物理页帧的顺序线性排列。
可以由page结构体的地址找到物理页帧号;也可以由物理页帧号找到其对应的page结构体。

3.2 区:
将物理内存按照不同的功能划分为不同的区。例如,X86架构经典分区为高端内存区,低端内存区和DMA区。每个区使用结构体struct zone来表示。例如,x86架构的一个经典分区如下。DMA在工作的时候需要一段连续的物理内存,因此需要分一块内存给DMA单独使用。

结构体zone定义在include/linux/mmzone.h里面。
zone结构体的几个主要成员介绍如下:

zone_start_pfn:表示当前这个分区所管理的内存起始页帧号;
_watermark:表示当前分区内存的使用率,会根据水位的高低进行调节,例如内存回收等;
使用如下枚举变量定义当前的分区是什么类型:

PS:一般X86架构才单独划分DMA区域,ARM架构使用CMA机制,后续会有介绍。
ZONE_NORMAL表示低端内存;ZONE_HIGH表示高端内存;
3.3 节点node:
节点是相对于服务器而言的。使用node表示当前cpu能够访问到的内存资源。对于服务器而言可能有多个node,对于嵌入式系统而言,一般只有一个node。

3.4 物理内存管理架构
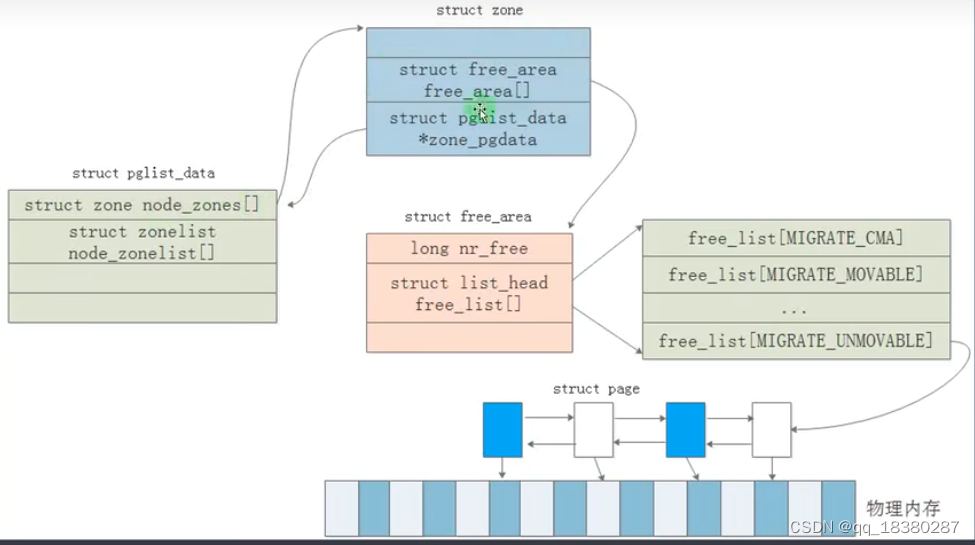
一个简单的计算机系统,使用一个node来表示他的所有的内存资源。在一个node里面通过node_zones数组,把内存划分为不同的区,注意区是可以配置的,例如在内核中不配置高端内存,那么就没有这个区。每个区下面都有一个数组,表示page,进而找到其管理的物理页帧。

4.伙伴系统(buddy system)
伙伴系统——用来管理物理内存。管理物理内存实际上就是管理这些page结构体。
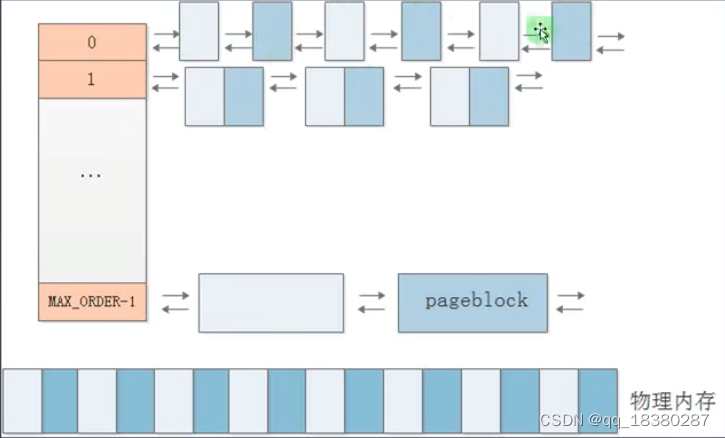
伙伴系统的管理思路:将所有的物理内存划分成不同大小的块,然后使用链表将相同大小的块连接起来,将所有的链表头保存到一个数组里面。例如,最小的是使用每个物理页组成一个块,然后使用链表将他们连接起来;也可以使用两个物理也组成一个块,然后使用链表连接起来,链表头放到数组。数组的索引其实就是一个阶数,组成块的物理页数=2^数组索引。内核里面定义了这样一个宏MAX_ORDER来表示最大物理块的大小,这个数一般是11,所以最大的内存块一般是2^(11-1)*4KB=4MB。这个最大的内存块又称为pageblock(页块)。
在系统初始化时,伙伴系统会将所有的物理内存按照pageblock划分为多个块,然后使用链表连接起来。
当用户申请的时候,会根据用户申请的大小到数组中去找对应的索引进而找到对应的链表。例如申请4KB,如果在有4KB的块则直接申请使用就可以了,假如没有,则会去检查是否有8KB的如果有则将8KB的分割成两个4KB的,一个返回给用户另一个则挂在4KB对应的链表上,如果8KB仍然没有则到16KB去找,以此类推。
当用户释放内存的时候,会根据返回的内存块的大小,插入到对应的链表。注意,插入时有一个内存合并的操作,如果待插入的内存块与其中一个内存块大小相等且地址相邻(将这两个内存块成为一对伙伴),则会拼接成一个物理块并插入到对应的链表。
伙伴系统通过上述过程在一定程度上缓解了内存碎片化。
伙伴系统管理内存实际上是按照分区进行管理的,实际就是将某一个分区上的绝大部分内存页放到伙伴系统里面,这里就要重提zone结构体了。zone结构体中free_area成员就是上述描述中所谓的数组,存放这个各个不同的链表的表头,每个表头指向不同大小的内存块。zone结构体中还有另一个成员lowmem_reserve,实际上并不是将分区中所有的物理页都放到伙伴系统里面,剩余的物理页作为备份,lowmem_reserve成员就是用来存放备份物理页的。
新版伙伴系统中,会将一个分区内的物理页划分成不同的类型,例如可移动的、不可移动的、可回收的等,例如程序代码所存储的位置是不能移动的,而有些数据是可以移动的,例如为某个变量申请一个内存后,再申请一段连续内存的时候恰好之前的这个变量破坏了这段连续的内存,那么就会将这个变量拷贝到其他位置,这个时候这个变量的内存类型就是可移动的。
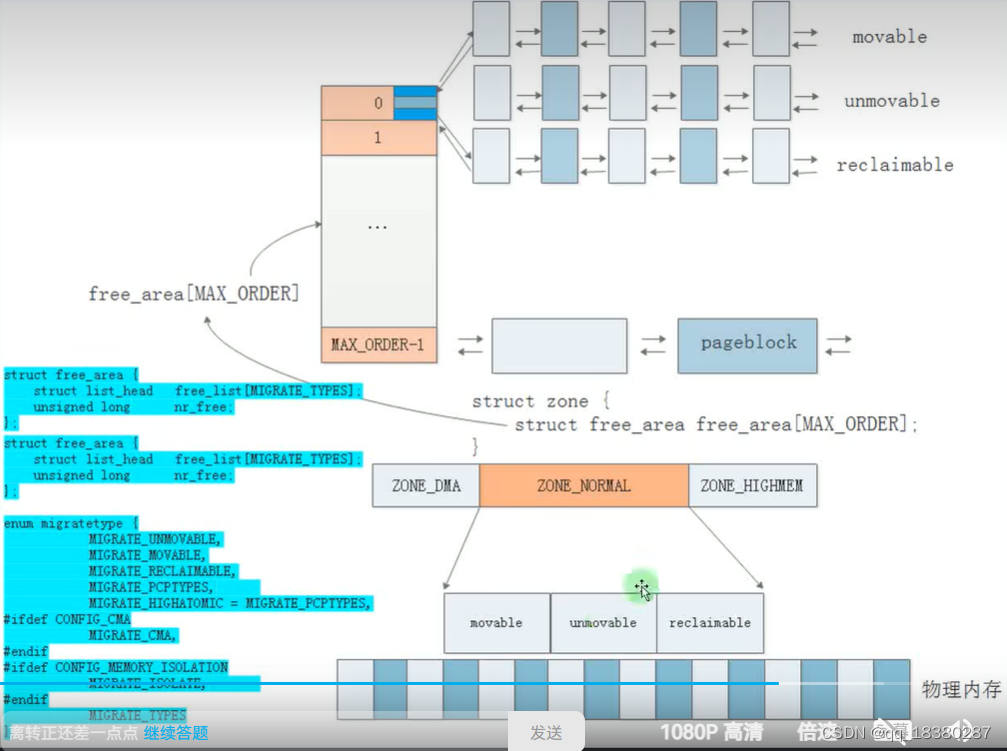
在Linux系统中,/proc/pagetypeinfo 文件提供了关于内存页面类型的详细信息,特别是与伙伴系统(Buddy System)相关的页面。这个文件是内核暴露给用户空间的一个接口,用于了解当前系统中不同类型页面的使用情况和状态。

Page block order: 这是页面块的大小指数。在你的输出中,页面块的大小是 (2^{13}) 或 8192 页。这意味着每个页面块包含 8192 个连续的物理内存页面。
Pages per block: 每个页面块包含的页面数量。在你的输出中,每个块有 8192 个页面,这与页面块的大小指数相匹配。
接下来,输出列出了每种迁移类型(migratetype)在不同阶(order)上的空闲页面数量。阶(order)表示页面块的大小,Order 0 表示单个页面,Order 1 表示包含 2 个页面的块,依此类推,直到 Order 13,即包含 8192 个页面的块。
每种迁移类型代表不同类型的内存页面,它们有不同的用途和管理策略:
Unmovable: 这些页面不能移动,通常因为它们被内核数据结构(如内核线程栈或某些内核数据结构)或硬件映射(如设备内存映射)所使用。这些页面不能被移动到其他位置,因此它们不能用于满足需要移动性的内存分配请求。
Movable: 这些页面是可以移动的,意味着它们可以被内核重新分配到系统的其他部分。当系统需要内存时,这些页面可以被回收并重新分配给需要它们的进程。Movable 页面通常用于常规进程分配。
Reclaimable: 这些页面当前被用作文件缓存,但它们可以被回收以释放内存。当系统需要更多内存时,这些页面可以被释放并用于满足其他内存分配请求。Reclaimable 页面是文件缓存的一部分,用于加速文件读写操作。
HighAtomic: 这些页面用于需要原子性的操作,即不能阻塞或睡眠的操作。它们通常用于中断处理程序或其他需要快速响应的内核代码路径。由于这些页面不能阻塞,它们通常用于低延迟的上下文。
CMA (Contiguous Memory Allocator): CMA 保留了一块连续的内存区域,用于满足需要大块连续内存的设备驱动程序。CMA 旨在提供一块预留的、连续的物理内存,以便设备驱动程序可以在不需要进一步分配或重新排列内存的情况下使用它。这对于需要连续内存块的硬件设备(如某些图形卡或网络设备)非常重要。
Isolate: 这些页面被隔离,通常是为了满足某些特定的内存分配需求。它们可能正在被用于特定的内存管理操作,如内存回收或页面迁移。
在输出中,对于每种迁移类型,你都可以看到从 Order 0 到 Order 13 的空闲页面块数量。例如,对于 Unmovable 类型,在 Order 0 上有 4 个空闲页面块,在 Order 1 上有 5 个,依此类推。这些数字提供了关于系统中每种迁移类型的空闲页面分布的信息。
最后,输出中的最后一部分显示了每种迁移类型的页面块总数。这提供了每种迁移类型在整个系统中占用的页面块数量的概览。例如,在你的输出中,Unmovable 类型有 1 个页面块,Movable 类型有 4 个页面块,依此类推。
通过查看 /proc/pagetypeinfo 输出,系统管理员和开发人员可以获得关于系统中不同类型页面的使用情况和状态的详细信息。这有助于诊断内存相关问题(如内存泄漏、碎片或过度使用),以及优化系统的内存管理策略。
如何判断某一个物理页有没有被分配给伙伴系统使用,或者有没有被分配给用户,可以通过page结构体里面的_mapcount成员;另一个成员private,表示物理页当前所在的内存块的大小。

5.物理页面的迁移类型(migratetype)

6.Per-CPU页帧缓存(migratetype)
如果是一个多核的计算机系统,每个CPU都有一个本地缓存链表,在这个链表里面缓存了单个的页。所以在申请内存是,如果申请的是单个的页,他会先到CPU这个本地链表去申请,如果不是单个的页则到伙伴系统中去申请。
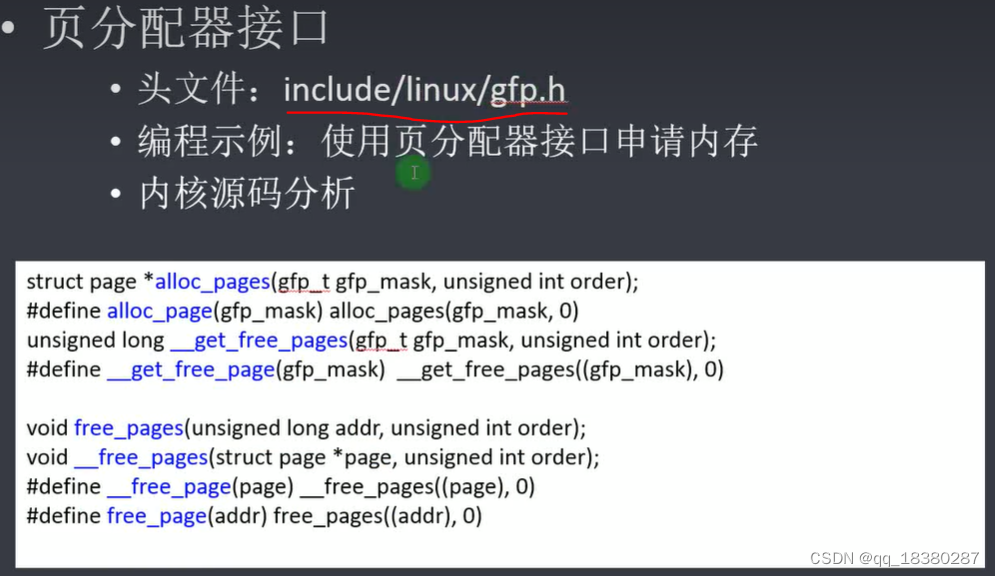
7.页分配器接口:alloc_pages
伙伴系统接管了对物理内存的管理之后,会将某一个分区上的整片内存划分成大小不同的块挂接到不同的链表上,同时也提供分配内存、释放内存的编程接口(alloc_pages, free_page),原理很简单,就是链表的移除和插入。
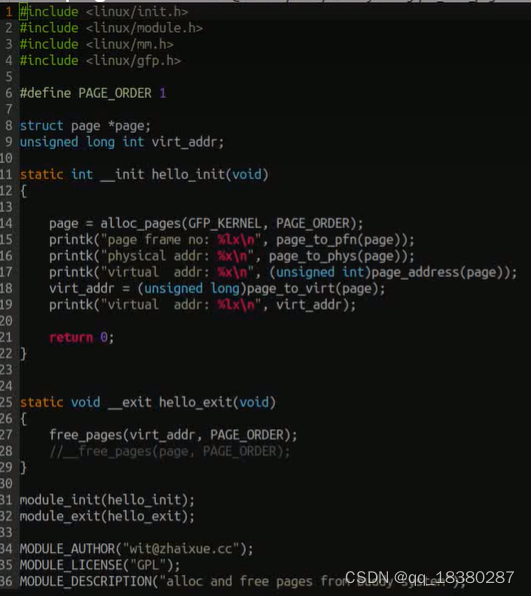
编写代码实现一个测试程序,代码内容如下,编译后在开发板insmode alloc_page.ko,测试之后需要执行rmmod alloc_page.ko释放掉内存。引流——内核模块开发
在内核源码的具体实现中,申请内存主要分为两种,fastpath:从伙伴系统的空闲链表中获取path;slowpath:对内存进行整理,迁移,压缩,交换,腾出大块的连续物理内存。
8.连续内存分配器-CMA(Contiguous Memory Allocator)
CMA的作用是申请大块的连续物理内存。伙伴系统也可以申请大块的连续物理内存,但是其大小受限于MAX_ORDER(一般情况下MAX_ORDER为11,所以能够申请的最大连续物理内存就是 2 ^(MAX_ORDER-1)*4kB=4MB)。当很多的驱动或者使用DMA功能时,需要更大的连续物理内存,这时伙伴系统就不能满足需求了。
为解决上述问题,在X86系统中,会预留出一部分区域专门用于DMA,(即前述DMA区域),这样做存在一个缺点就是,当没有DMA使用需求时,这部分区域就是空闲的,现在很多模块都会需要大块的物理内存,例如一个3200万像素的的摄像头,拍照时会需要100多MB的物理内存,如果专门划出几百M的区域用于DMA,在不使用时是对内存的极大的浪费。因此引入CMA技术。
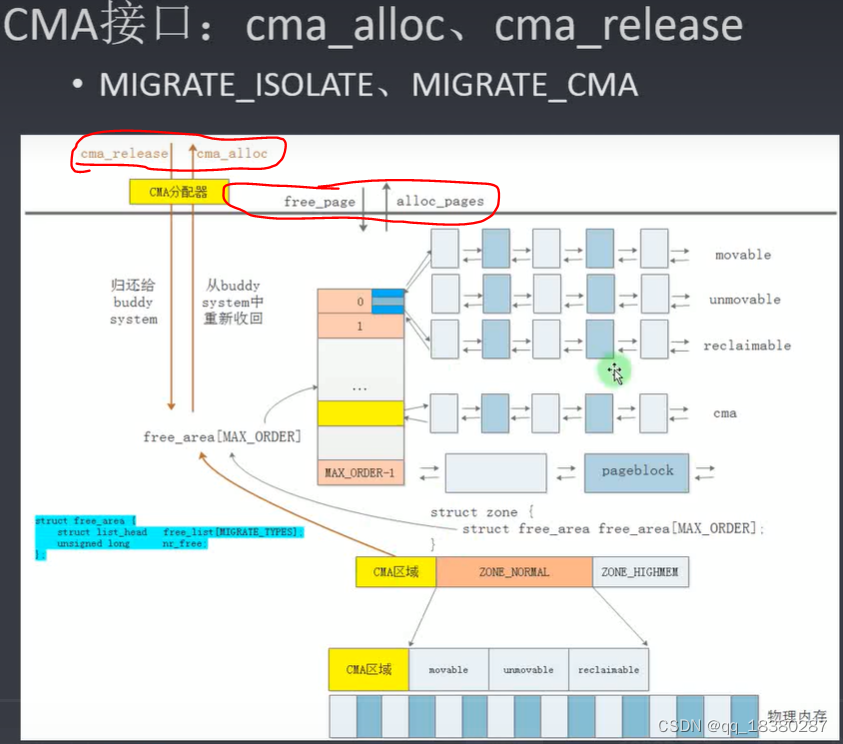
CMA与DMA类似,也是留出一部分区域用于分配连续物理内存,区别是当这段区域没有被使用时,CMA区域也会被纳入伙伴系统的管理中,通过伙伴系统的接口被分配出去。
当使用CMA分配器接口申请连续的物理内存是,如果要申请的区域已经被伙伴系统分配出去了,那么伙伴系统通过迁移操作,将数据迁移到其他位置,然后将内存交还给CMA,以供CMA分配器使用。
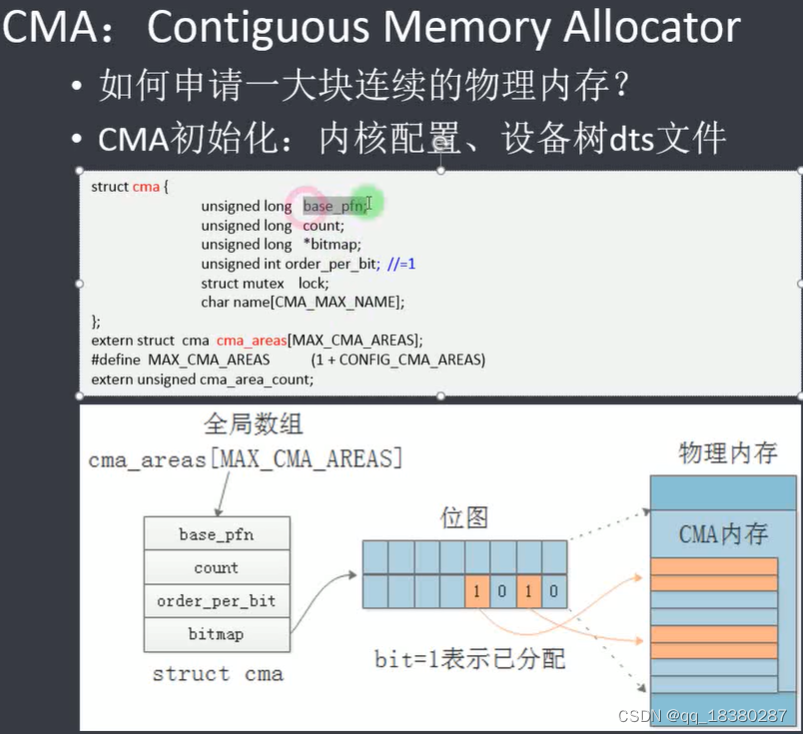
base_pfn:表示这片CMA区域的起始物理页帧号。
count:物理页的个数。
bitmap:表示当前CMA区域物理页的使用情况,每个bit位表示对应的物理页(块)是否已经被分配,bit=1表示已经被分配。
oredr_per_bit:与bitmap配合使用,oredr_per_bit=0时,bitmap中每一位表示一个物理页;oredr_per_bit=1时,bitmap中每一位表示两个物理页;即,bitmap中每一位表示2^(oredr_per_bit)个物理页。
可以同时存在多个CMA区域,所以定义了一个全局的结构体数组cma_areas。CMA区域的个数是可以通过内核配置的。
当CMA区域未被使用时,会被加入到伙伴系统中,CMA区域在伙伴系统中的类型为MIGRATE_CMA,只有当用户申请的物理内存是可移动的类型时,才会使用CMA区域。
当类型被设置为MIGRATE_ISOLATE时,伙伴系统便不会再使用该区域,因为该区域已被用作DMA。
使用CMA内存时,一般情况下不会直接调用cma_alloc和cma_release,因为CMA主要就是给DMA功能使用,所以一般情况下是使用DMA的相关API来申请CMA内存。
9.伙伴系统初始化(一)——memblock管理器
10.伙伴系统初始化(二)——memblock内存释放
11.伙伴系统初始化(三)——init内存释放
12.伙伴系统初始化(四)——CMA内存释放
13.slab缓存机制(slab、slob和slub分配器)
- slab:对伙伴系统的改进和补充。伙伴系统对于内存的管理是以page为单位的,使用伙伴系统的接口申请小于page的内存时,实际上他返回的也是一个page,这就造成了内存的浪费,slab机制弥补了这一缺点。
- slab的工作机制。先使用伙伴系统的接口申请一个页或几个页组成的内存块,然后将其切割为大小相等的小内存块(称之为内存对象object)
- 三种分配器(实现方式):slab、slob、slub。可以通过配置内核config变量来决定使用哪种分配器。在分析内存管理源码时,一定要注意,不同的配置对应的结构体定义以及函数分支的走向是不一样的,因此在分析基于某一平台或者某一内核版本的源码时,一定要搞清楚他用的是哪个机制,可以通过查看config变量来确认他用的是哪一个机制。

14.kmalloc机制实现分析
14.1 如何在内核驱动中申请和释放内存
#include <linux/slab.h>
void *kmalloc(size_t size, gpf_t flags);
void kfree(const void *);
14.2 kmalloc实现机制
在kmalloc的具体实现中,会根据不同的宏选择不同的分支。会根据申请的内存大小进行判断,如果申请的内存大于8KB(宏定义的一个阈值),直接从伙伴系统中(调用alloc_pages)申请物理内存页。如果不大于8KB,则会到slub/slab/slob缓存中申请。
14.3 问题思考
- kmalloc能申请的最大内存是多少——pageblock[2^(MAX_ORDER-1) * 4kB];
- kmalloc返回的地址对齐方式——如果使用伙伴系统那么就是页对齐;如果是slab缓存那么就与创建slab时使用的对齐方式相同;
- kmalloc返回的是虚拟地址还是物理地址——kmalloc无论是从伙伴系统中拿内存还是从slab缓存中拿内存,最终都会调用page_to_virt函数将物理地址转换成虚拟地址,然后返回给用户使用,所以kmalloc返回的是一个虚拟地址;
15. 虚拟地址和MMU(Memory Management Unit)工作原理
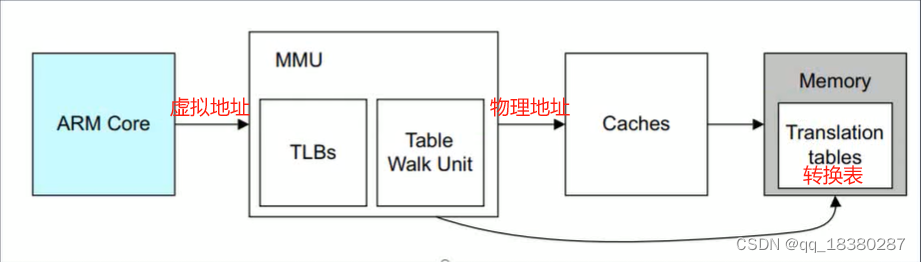
注:linux默认MMU是开启的,所以linux里面跑的都是虚拟地址。
cpu内部通过mmu将虚拟地址转换为物理地址,然后将物理地址通过管脚发给DDR。
虚拟页帧号与物理页帧号:MMU以页为单位进行地址转换。
页表中保存着物理地址与虚拟地址之间的转换关系,MMU从页表中读取这些转换关系,每次读取时不是只读取一个转换关系,而是将其相邻的转换关系同时读取然后缓存在TLB中,可以提升效率。
15. 页表工作原理
页表:以物理页为单位进行映射,建立虚拟页与物理页之间的对应关系
15.1 一级页表

PS:一级页表的引入是为了更好的理解页表的工作原理,实际上linux内核是不会使用一级页表的。
页表所做的工作实际上就是虚拟页号与物理页号之间的映射;
虚拟地址0x80003160中的低12位(即0x160)实际上就是页内偏移(page为4KB)。
按照上述映射方法,每一个页对应一个映射条目,一个进程的地址空间是4G,那么一个进程就要映射出4G/4K=1MB个映射条目,加入一个映射条目按照4个字节存储的话,那么就需要4MB的存储空间。假如系统运行时有100个进程,那么光存储页表就需要100*4MB=400MB的存储空间,这显然是不行的。
15.2 二级页表
二级页表的优势:
- 不需要大量的连续物理内存
- 一个进程不会映射所有的虚拟地址空间
- 随着页表级数的增加,可以节省物理内存

高12位作为一级页表的偏移;中间8位作为二级页表的偏移;低12位作为页内偏移。
在一级页表中,每一个条目都对应着一个二级页表,每个条目中的内容就是其对应的为二级页表的首地址。
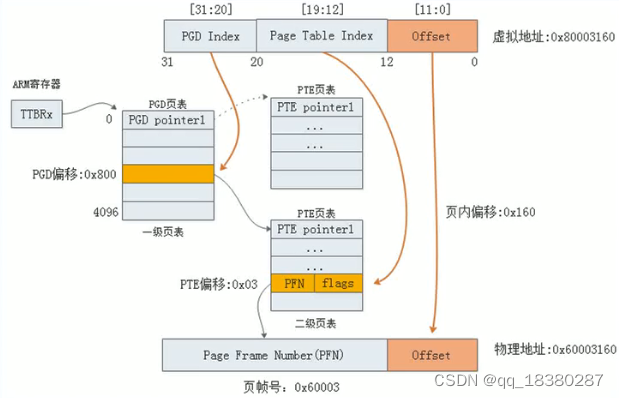
arm一般情况下就是使用二级映射,即二级页表,linux内核默认最大支持5级页表。
16. 揭开页表的神秘面纱

16.1 不同的映射方式,页表有什么区别
前面有分析过一级页表的page映射是以4KB为单位进行映射,其缺点是占用内存空间较大,其基本原理是,对于32位的虚拟地址,高20位作为页表索引,低12位作为页内偏移。
另一种一级页表映射方式是section映射,以1MB为单位进行映射,高12位作为页表索引,低20位作为section内偏移。

内核启动之前是section映射,内核启动之后是page映射。
一篇比较好的关于内存管理的博客















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









