






前言
Linux对页面分配分快速和慢速两种方法。在__alloc_pages_nodemask函数中,首先会使用快速方法进行内存分配,当分配失败时会进入慢速路径,函数最终会返回申请到的内存第一个页面page。本文主要对内存分配中的快速方法所涉及到的重要函数进行分析。
alloc_pages()
这个函数是内存分配的入口函数,最终会调用__alloc_pages_nodemask函数,关于内存分配的所以内容都会在这个函数中实现。它在mm/page_alloc.c中实现如下:
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,//alloc_pages函数最终调用此函数,伙伴系统核心函数
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;//表示页面分配的行为和属性,这里允许内存分配的判断条件为低水位
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };//伙伴系统分配函数保持相关参数的数据结构
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (unlikely(order >= MAX_ORDER)) {//判断分配的order是否超过最大的order=11
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))//函数计算相关信息保存在ac中
return NULL;
finalise_ac(gfp_mask, &ac);//确定首选的zone,并保存在ac中
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered
*/
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask);//用于内存碎片化方面的一个优化,首选zone是高端zone。
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);//从伙伴系统的空闲链表分配内存,成功返回第一个页面的page
if (likely(page))
goto out;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}.
*/
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);//分配不成功进入慢速分配
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}
这个函数主要做了两件事:
1,利用prepare_alloc_pages和finalise_ac函数填充一个alloc_context数据结构。这个结构是内存分配时的私有数据结构。其中finalise_ac函数会确定首选的zone
struct alloc_context {
struct zonelist *zonelist; //指向内存节点对应的zonelist,zonelist一般会有本地和远端两种类型
nodemask_t *nodemask;//表示分配掩码
struct zoneref *preferred_zoneref;//首选zone的zoneref,zoneref用于描述一个zone,它是zonelist成员
int migratetype; //内存的迁移类型
enum zone_type high_zoneidx;//根据分配掩码计算得到,表示允许内存分配的最高zone类型
bool spread_dirty_pages;//指定是否传递脏页
};
zonelist,zoneref,zone之间关系:
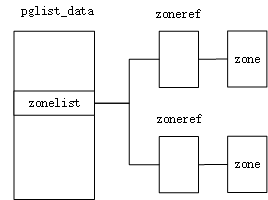
zonelist第一个成员一般会是首选zone。
2,从伙伴系统的空闲链表中分配内存并返回第一个页面page。当分配失败时会进入慢速路径分配。
get_page_from_freelist()
函数在mm/page_alloc.c文件中实现
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback;
retry:
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;//此标志表示需要避免内存碎片化
z = ac->preferred_zoneref;//表示zonelist中首选的zone,finalise_ac()函数通过first_zones_zonelist宏计算得到
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,//从首选的zone开始遍历所有zone
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
if (ac->spread_dirty_pages) {
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
if (no_fallback && nr_online_nodes > 1 && //当分配的内存的zone在远端,要考虑得是内存本地性(重新分配),而不是内存碎片化。本地访问速度快。
zone != ac->preferred_zoneref->zone) {
int local_nid;
/*
* If moving to a remote node, retry but allow
* fragmenting fallbacks. Locality is more important
* than fragmentation avoidance.
*/
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);//计算zone中的某个水位页面大小,三个水位:最低警戒,低水位,高水位
if (!zone_watermark_fast(zone, order, mark,//函数判断当前zone内存空间是否满足低水位,同时根据order判断是否有足够大的内存快。返回true表示zone的页面高于指定的水位或满足order分配需求
ac_classzone_idx(ac), alloc_flags)) {
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (node_reclaim_mode == 0 ||//为0表示从下一个zone或内存节点分配内存,否则当前zone可以进行内存回收操作,默认关闭本地回收内存
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);//此函数尝试回收一部分内存
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
/*从当前zone分配内存*/
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order,//函数会在伙伴系统中分配内存,伙伴系统核心分配函数
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);//分配成功要设置一些页面属性和做必要检查
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
首先,会从首选的zone开始遍历所有zone,如果当前zone在远端,会更改分配标志之后重新遍历所有zone,因为本地的访问速度比访问远端内存快的多,所有一般不会在远端zone上分配内存。接着判断zone中是否有足够的空闲内存用于分配,当不满足时会尝试回收一部分内存,当然这块一般默认是关闭的,不会进行内存回收。从try_this_zone标签开始就进入到真正的分配内存阶段。这块通过rmqueue函数实现。之后进行一些必要的检查就可以返回申请到的页面。
rmqueue()
从这个函数开始就进入到真正的页面分配中了,下面列出它的实现方法
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) {
page = rmqueue_pcplist(preferred_zone, zone, order,//函数从Per_CPU变量per_cpu_pages数据结构中分配单个页面,此数据结构暂存了一个由单页面组成的链表,需要但页面时会从这里申请,每个zone都有一个Per_CPU变量
gfp_flags, migratetype, alloc_flags);
goto out;
}
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));//处理order大于0的情况
spin_lock_irqsave(&zone->lock, flags);//申请锁保护zone中的伙伴系统
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);//去其他order切内存
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);//分配内存
} while (page && check_new_pages(page, order));//函数判断分配的页面是否合格
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),//成功分配的页面需要更新zone的NR_FREE_PAGES统计信息
get_pcppage_migratetype(page));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
out:
/* Separate test+clear to avoid unnecessary atomics */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {// 如果此标志位置位(说明有外内存碎片化倾向),会将其清零。之后唤醒kswapd线程进行内存回收
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}
在这里,它将申请单个页面和多个页面分开处理,单个页面会从的一个per_cpu_pages数据结构中申请。每个zone中都有一个这样的数据结构,它里面暂存了一部分单个的物理页面,当需要申请当页面时就会从这里面取,这种设计方式可以避免申请多个页面时的锁操作,提高效率。相关申请操作如下:
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list = &pcp->lists[migratetype];
page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list);
在do while函数中处理多个页面申请的情况,首先__rmqueue函数会调用_rmqueue_smallest函数从申请的order开始向上遍历每一个order,当申请到页面之后,会删除页面所在的链表并从伙伴系统中移出,接着会调用expand函数将剩余页面添加到低一级order的空闲链表中。如果申请失败就会调用__rmqueue_fallback函数在其他迁移类型的空闲页面中借用内存。check_new_pages函数会检查申请到的页面是否合格,返回真说明页面有问题会接着分配,为假说明申请的页面没有问题。最终会返回申请到的第一个页面数据结构。
参考:奔跑吧Linux内核卷1第二版















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









