







环境背景
使用DolphinScheduler3.0.0+CDH6.3.2(适配之前已存在任务环境)
已知问题
DolphinScheduler3.1.4默认是zookeeper3.8,需要手动编译zk3.4+,使用3.0.0正常
DolphinScheduler的hive相关依赖和CDH的版本不一致,需要在编译时修改pom文件
开启Kerberos时使用DolphinScheduler添加Hive数据源日志报错Peer indicated failure: Unsupported mechanism type PLAIN,在github的issue上有人说是bug,所以我手动编译3.1.4版本,问题依然存在,最终确定是依赖问题,下面附解决方法
hive数据源配置kerberos连接失败
执行spark yarn cluster任务失败 code -1000
添加hive数据源jdbc连接参数{"principal":"hive/_HOST@EXAMPLE.COM"},3.x版本的principle参数填写无效,保存->编辑无法回显,但是可正常使用
开始配置
按照官网说明修改master,worker,api模块下面的conf/common.properties相关的Kerberos配置
使用kadmin.local生成keytab文件及相应的princal,不让之前配置密码失效加-norandkey
kadmin.local -q "xst -k /opt/hdfs.keytab hdfs@EXAMPLE.COM"crontab添加定时任务kinit -kt /opt/software/kerberos/hdfs.keytab hdfs
配置正确重启小海豚,spark任务不需要任何修改是可以正常执行的,添加hive数据源异常
思路参考
方法一(简单)
(1)复制依赖hive-shim相关依赖
cdh_jars=/opt/xxx/CDH-xxx/jars
dol314=/opt/dolphinscheduler
cp $cdh_jars/hive-shims-* $dol314/mater-server/libs
cp $cdh_jars/hive-shims-* $dol314/worker-server/libs
cp $cdh_jars/hive-shims-* $dol314/api-server/libs(2)连接参数配置{"principal":"hive/_HOST@EXAMPLE.COM"}
方法二
(1)重新编译小海豚,修改pom文件,添加hive-shim依赖注意版本
连接成功
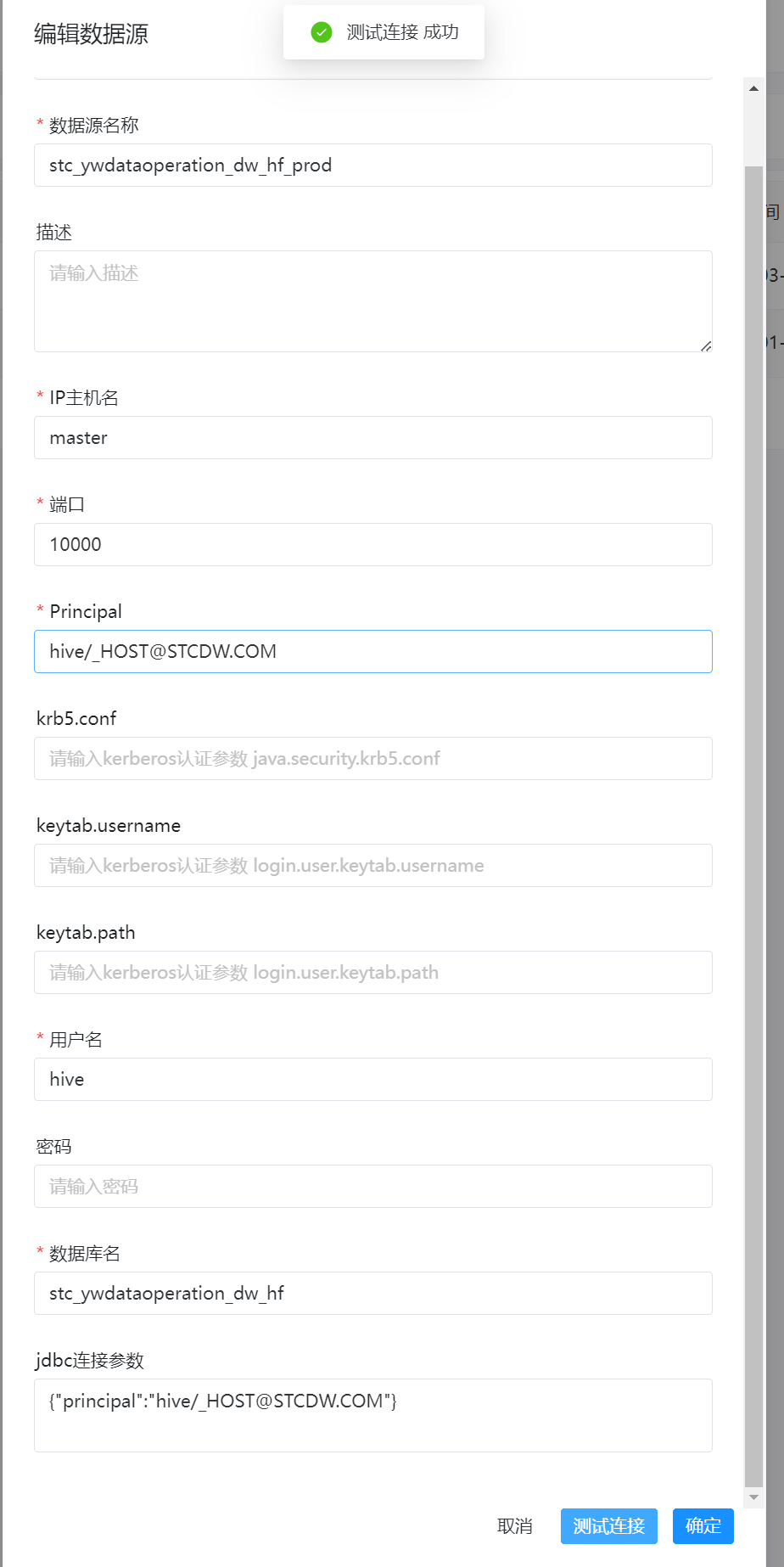
tips:第一次连接成功后,会有缓存,删除jdbc连接参数也能连接成功,所以会误导,而且存在一个bug,保存后再次点击编辑,principle的值没有回显,但是不影响使用
可能报错
java.sql.SQLException: Could not open client transport with JDBC Uri: GSS initiate failed
检查配置的kerberos相关信息是否正确
java.lang.NoClassDefFoundError: org/apache/hadoop/hive/thrift/TFilterTransport
shim-*.jar包依赖问题或者jdbc连接参数中存在{"principal":"hive/_HOST@EXAMPLE.COM"}
spark本地模式正常,集群模式失败:
Requested user hdfs is not whitelisted and has id 994,which is below the minimum allowed 1000
user: hdfs
修改CM的yarn配置,min.user.id->改为0和banned.users->删除hdfs,保存,重启yarn
注意事项
hive的principle可以使用配置文件里面的,也可以使用CM创建的hive/master@EXAMPLE.COM,用户名默认hive就行
kerberos命名规则,用户/主机@Realm,使用keytab,原来的密码失效(创建keytab可添加密码不失效参数-norandkey),一个用户可以访问所有服务
window客户端使用要保证krb5.conf的kdc和admin_server和服务端一致
使用kerberos服务要么用户定时任务使用keytab文件认证要么参数配置principle参数
注意keytab文件的权限,用户无权访问keytab文件也会报错

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









