









深度学习:Xavier初始化理论+代码实现
Xavier初始化理论
权值初始化对网络优化至关重要。早年深度神经网络无法有效训练的一个重要原因就是早期人们对初始化不太重视。我们早期用的方法大部分都是随机初始化,而随着网络深度的加深,随机初始化在控制数值稳定性上也可能失效。Xavier这个方法可以考虑输入层与输出层的维度,使在forward 和backward阶段保持每层之间均值与方差接近。
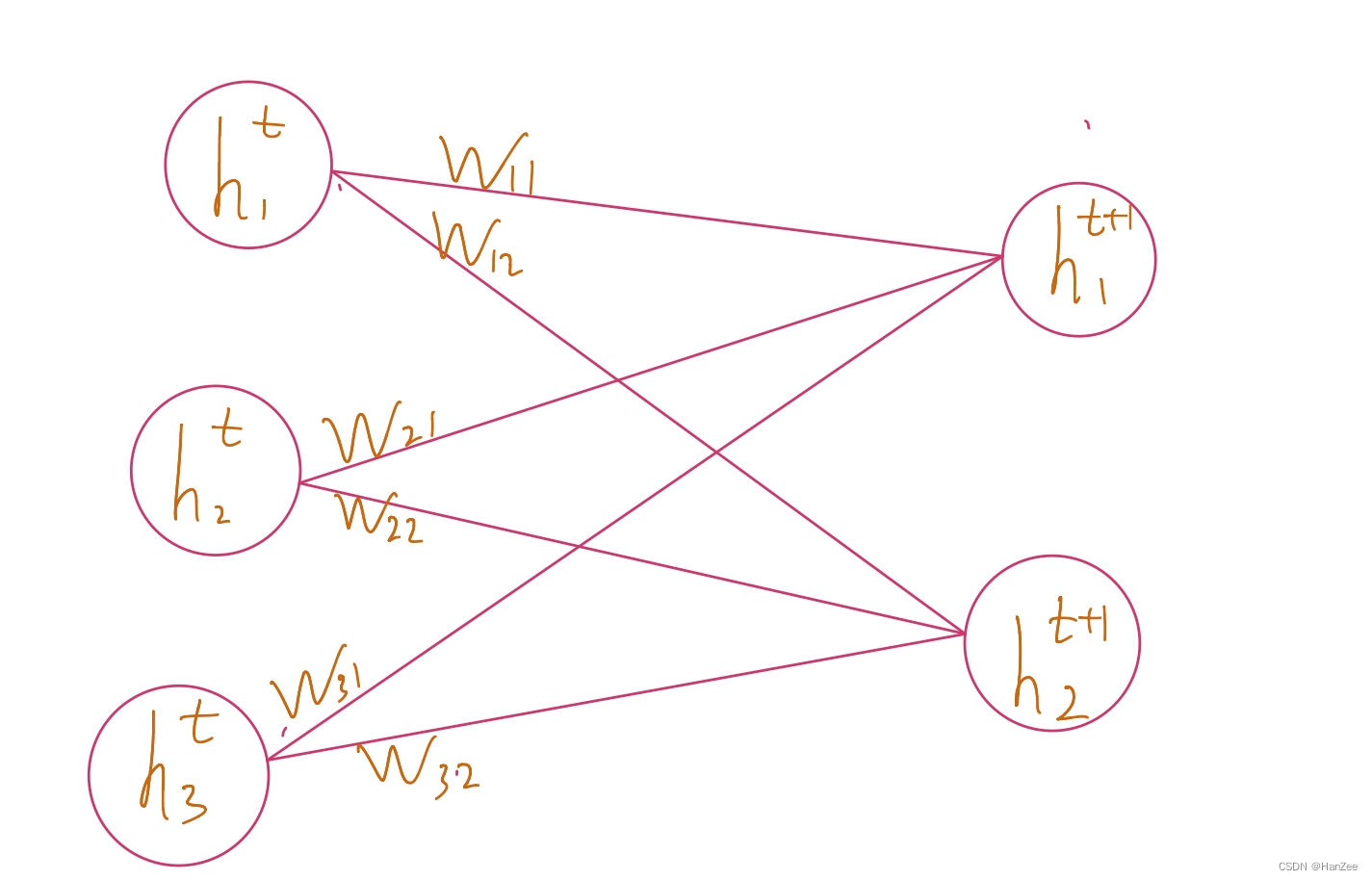
我们拿mlp举例,为了方便运算,忽略激活函数,上图是神经网络的一部分,我们假设
h
1
t
h_1^t
h1t为输入层
h
t
t
+
1
h_t^{t+1}
htt+1为输出层,我们假设权重系数W~iid(independent identically distribution),均值为0,方差为a,其中
h
t
、
h
t
+
1
h^t、h^{t+1}
ht、ht+1独立于w。
前向计算公式为:
h
j
t
+
1
=
∑
i
w
i
j
⋅
h
i
t
h_{j}^{t+1}=\sum _{i}w_{ij}\cdot h_{i}^{t}
hjt+1=i∑wij⋅hit
Xavier的核心思想是让输入层与输出层方差接近,我们首先考虑
h
t
、
h
t
+
1
h^t、h^{t+1}
ht、ht+1的均值。
E
[
h
j
t
+
1
]
=
E
[
∑
i
w
i
j
⋅
h
i
t
]
=
∑
1
E
[
w
i
j
]
⋅
E
[
h
i
t
]
=
∑
i
0
⋅
E
[
h
i
t
]
=
0
\begin{aligned}E\left[ h_{j}^{t+1}\right] =E\left[ \sum _{i}w_{ij}\cdot h_{i}^{t}\right] \\ =\sum _{1}E\left[ w_{ij}\right] \cdot E\left[ hi^{t}\right] \\ =\sum _{i}0\cdot E\left[ hi^{t}\right] \\ =0\end{aligned}
E[hjt+1]=E[i∑wij⋅hit]=1∑E[wij]⋅E[hit]=i∑0⋅E[hit]=0
我们发现t+1层均值为0,之后计算方差:
V
a
r
[
h
j
t
+
1
]
=
E
[
(
h
j
t
+
1
)
2
]
−
E
[
h
j
t
+
1
]
2
=
E
[
h
j
t
+
1
)
2
]
−
0
=
E
[
(
∑
i
w
i
j
⋅
h
i
t
)
2
]
=
E
[
∑
i
(
w
i
j
)
2
(
h
i
t
)
2
]
=
∑
i
E
[
(
w
i
j
)
2
]
E
[
(
h
i
t
)
2
]
=
∑
i
V
a
r
[
w
i
j
]
⋅
V
a
r
[
h
i
t
]
\begin {aligned}Var\left[ h_{j}^{t+1}\right] \\ =E\left[ \left( h_j^{t+1}\right) ^{2}\right] -E\left[ h_{j}^{t+1}\right] ^{2}\\ =E\left[ h_j^{t+1}) ^{2}\right] -0\\ =E\left[ \left( \sum _{i}w_{ij}\cdot h_{i}^{t}\right) ^{2}\right] \\ =E\left[ \sum _{i}\left( w_{ij}\right) ^{2}\left( h_{i}^{t}\right) ^{2}\right] \\ =\sum _{i}E[(w_{ij})^2]E[(h_{i}^{t})^2]\\ =\sum _{i}Var\left[ w_{ij}\right] \cdot Var\left[ h_{i}^t\right] \\ \end{aligned}
Var[hjt+1]=E[(hjt+1)2]−E[hjt+1]2=E[hjt+1)2]−0=E⎣⎡(i∑wij⋅hit)2⎦⎤=E[i∑(wij)2(hit)2]=i∑E[(wij)2]E[(hit)2]=i∑Var[wij]⋅Var[hit]
我们的目标是让前后层方差相等,所以并且w的方差在上面我们假设为a,所以我们要满足:
n
t
∗
a
=
1
n^t*a = 1
nt∗a=1
到目前为止,我们的前向计算的满足条件就计算完成了,我们接下来计算反向传播:
∂
L
o
s
s
∂
h
t
=
∂
l
o
s
s
∂
h
t
+
1
⋅
W
i
j
\dfrac{\partial Loss}{\partial h^{t}}=\dfrac{\partial loss}{\partial h^{t+1}}\cdot W_{ij}
∂ht∂Loss=∂ht+1∂loss⋅Wij
计算步骤可前面一样,最终我们可以得出:
n
t
+
1
∗
a
=
1
n^{t+1}*a = 1
nt+1∗a=1
我们到了一个进退两难的地步,因为无法同时满足:
n
t
∗
a
=
1
n^t*a = 1
nt∗a=1、
n
t
+
1
∗
a
=
1
n^{t+1}*a = 1
nt+1∗a=1,所以Xavier采取了一个折中的方案:
(
n
t
+
n
t
+
1
)
⋅
a
=
2
a
=
n
t
+
n
t
+
1
2
\begin{aligned}\left( n_{t}+n_{t+1}\right) \cdot a=2\\ a=\dfrac{n_{t}+n_{t+1}}{2}\end{aligned}
(nt+nt+1)⋅a=2a=2nt+nt+1
我们有了权重的均值和方差,我们就可以初始化了。
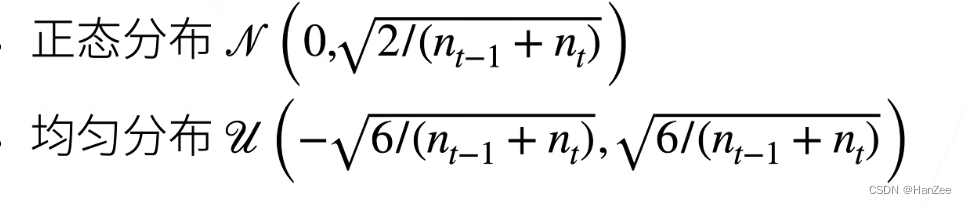
当加入激活函数,是否他们会改变呢?
我们加入激活函数:为了方便运算,假设线性激活函数为:
σ
(
x
)
=
α
x
+
β
E
[
σ
(
h
j
t
+
1
)
]
=
α
E
[
h
j
t
+
1
]
+
E
[
β
]
=
0
\begin{aligned}\sigma \left( x\right) =\alpha x+\beta \\ E\left[ \sigma \left( hj^{t+1}\right) \right] \\ =\alpha E\left[ hj^{t+1}\right] +E\left[ \beta \right] =0\end{aligned}
σ(x)=αx+βE[σ(hjt+1)]=αE[hjt+1]+E[β]=0
为了保证均值为0,其中E
[
h
j
t
+
1
]
[h_j^{t+1}]
[hjt+1]均值为0,
β
\beta
β也要为0.
V
a
r
[
σ
(
h
j
t
+
1
)
]
=
E
[
(
h
j
t
+
1
)
2
]
−
E
[
h
j
t
+
1
)
]
2
=
E
[
(
α
h
j
t
+
1
+
β
)
2
]
=
E
[
(
(
α
h
j
t
+
1
)
2
+
2
α
h
j
t
+
1
β
+
β
2
)
]
=
α
2
E
[
(
h
j
t
+
1
)
2
]
=
α
2
V
a
r
[
h
j
t
+
1
]
\begin{aligned}Var\left[ \sigma (h_{j}^{t+1}) \right] \\ =E\left[ (h_{j}^{t+1}) ^{2}\right] -E\left[ h_j^{t+1}) \right] ^{2}\\ = E\left[ \left( \alpha h_{j}^{t+1}+\beta \right) ^{2}\right] \\ =E\left[ \left( \left( \alpha h_j^{t+1}\right) ^{2}+2\alpha h_j^{t+1}\beta +\beta ^{2}\right) \right] \\ =\alpha ^{2}E\left[ \left( h_{j}^{t+1}\right) ^{2}\right] \\ =\alpha ^{2}Var\left[ hj^{t+1}\right] \end{aligned}
Var[σ(hjt+1)]=E[(hjt+1)2]−E[hjt+1)]2=E[(αhjt+1+β)2]=E[((αhjt+1)2+2αhjt+1β+β2)]=α2E[(hjt+1)2]=α2Var[hjt+1]
我们发现,经过激活函数,变成了之前的alpha 方倍,为了保持方差不变,让 alpha =1。也就是说,我们的激活函数尽量选择与y =x 接近的函数,才可以在Xavier上表现较好。

代码实现
import torch
from torch import nn
model = nn.Linear(20, 30)
input = torch.randn(128, 20)
model.weight=torch.nn.Parameter(nn.init.uniform_(torch.Tensor(30,20)))##均匀分布
model.weight=torch.nn.Parameter(nn.init.normal_(torch.Tensor(30,20)))##正态分布
output = m(input)

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











