







数据分析:基于Pandas的全球自然灾害分析与可视化
问题描述
本次课程设计选题来源于对数据源为《1900-2021世界自然灾害统计》的数据进行分析,大概1.6w条数据,实现了各种分析,最后可视化展示。
数据下载:
链接: https://pan.baidu.com/s/15f3z_H6_ygGEBsZVakEtJA?pwd=g6ce 提取码: g6ce
–来自百度网盘超级会员v1的分享
处理流程
DataSet以excel文件形式储存,通过Jupyter Notebook 调用Pandas库来读取数据,把按照老师的分析对数据进行数据清洗,数据规约,数据探查,以及统计等工作,数据整理好后,把数据用Excel,PowerBi,PowerPoint进行数据可视化。
数据预处理
数据提取
excel中元数据为路径,通过观察,数据存在规则有序的噪声,通过excel的替换功能与正则表达式进行筛洗,消除噪声。 遍历所有数据到jupyter内存。
import pandas as pd
io = '/Users/hanze/Desktop/副本自然灾害数据库(1)(1).xlsx'
data = pd.read_excel(io)
data.head()
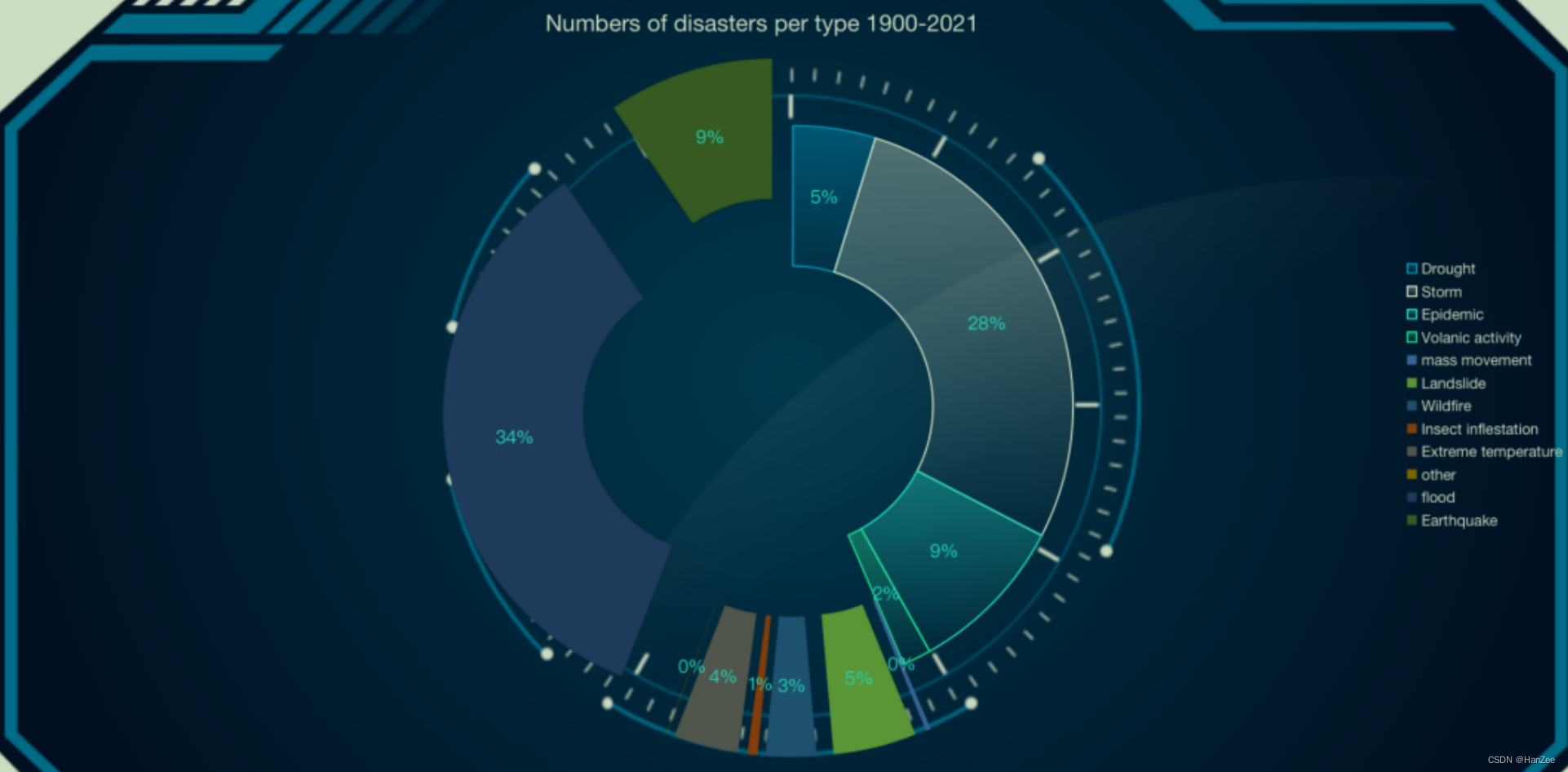
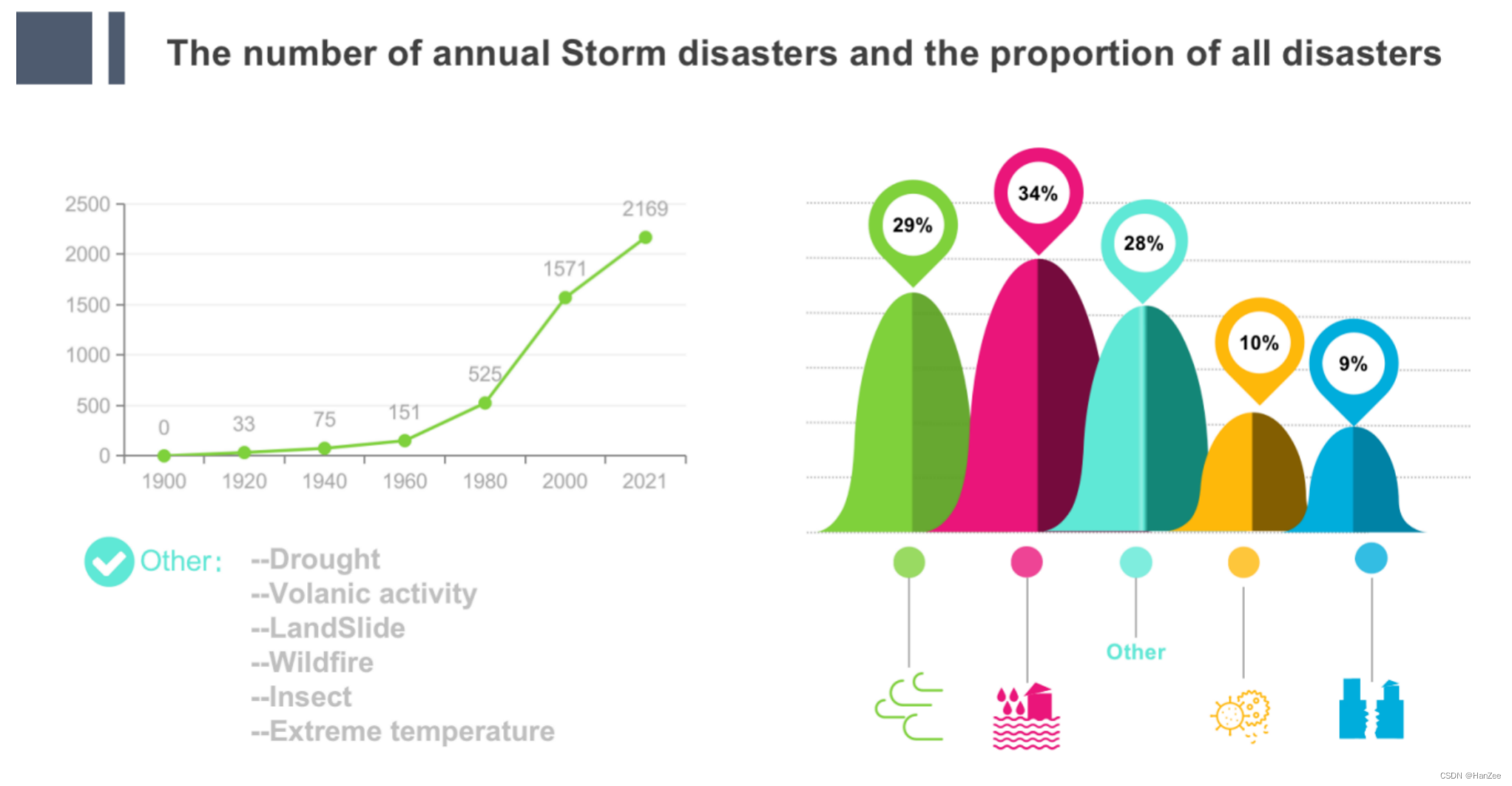
按主要类别与年份统计灾害数
建立一个空字典,首先把数据读进字典,年份作为key,发生的灾害名称作为value,然后利用dict.items()方法和两个for循环遍历外层字典与内层values,统计没年每种灾害发生的次数,然后把1900-2021的所有每年的发生的灾害求和,这样就得到了全部的结果,代码如下:
import csv
data1=dict()
f = open('feng.csv','w',encoding='utf-8')
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
for i in data.values:
keys = list(data1.keys())
# print(keys,i[1],i[5])
if i[1] in keys:
data1[i[1]].append(i[6])
# print(1)
else:
data1[i[1]]=[]
data1[i[1]].append(i[6])
temp={}
temp2={}
a=[]
for i,v in data1.items():
templist=[]
for v1 in v:
if v1 not in templist:
templist.append(v1)
for v2 in templist:
if v2=='Storm':
num = v.count(v2)
print(v2,num ,i)
csv_writer.writerow([i,num,v2])
# a.append([i,num,v2])
统计每类灾害影响的人数
读取数据到jupyter 内存中,把数据读取进字典,key为年份。value为每类灾害影响人数,然后把相同的灾害影响人数相加求个,最后把每年灾害的影响人数放进一个数据。最后通过count函数统计1900-2021年的每类灾害的所有人数,代码如下:
data1=dict()
for i in data.values:
keys = list(data1.keys())
# print(keys,i[1],i[5])
if i[1] in keys:
data1[i[1]].append(i[6])
# print(1)
else:
data1[i[1]]=[]
data1[i[1]].append(i[6])
temp={}
a=[]
temp2={}
for i,v in data1.items():
templist=[]
for v1 in v:
if v1 not in templist:
templist.append(v1)
for v2 in templist:
num = v.count(v2)
# print(v2,num ,i)
a.append([v2,num])
temp={}
for i in a:
keys = list(temp.keys())
if i[0] not in keys:
temp[i[0]]=int(i[1])
elif i[0] in keys:
temp[i[0]]+=int(i[1])
sum=int(0)
for i in temp.items():
sum+=int(i[1])
for i in temp.items():
# print(i[1],sum)
print(round(int(i[1])/int(sum),2),i[0],i[1])
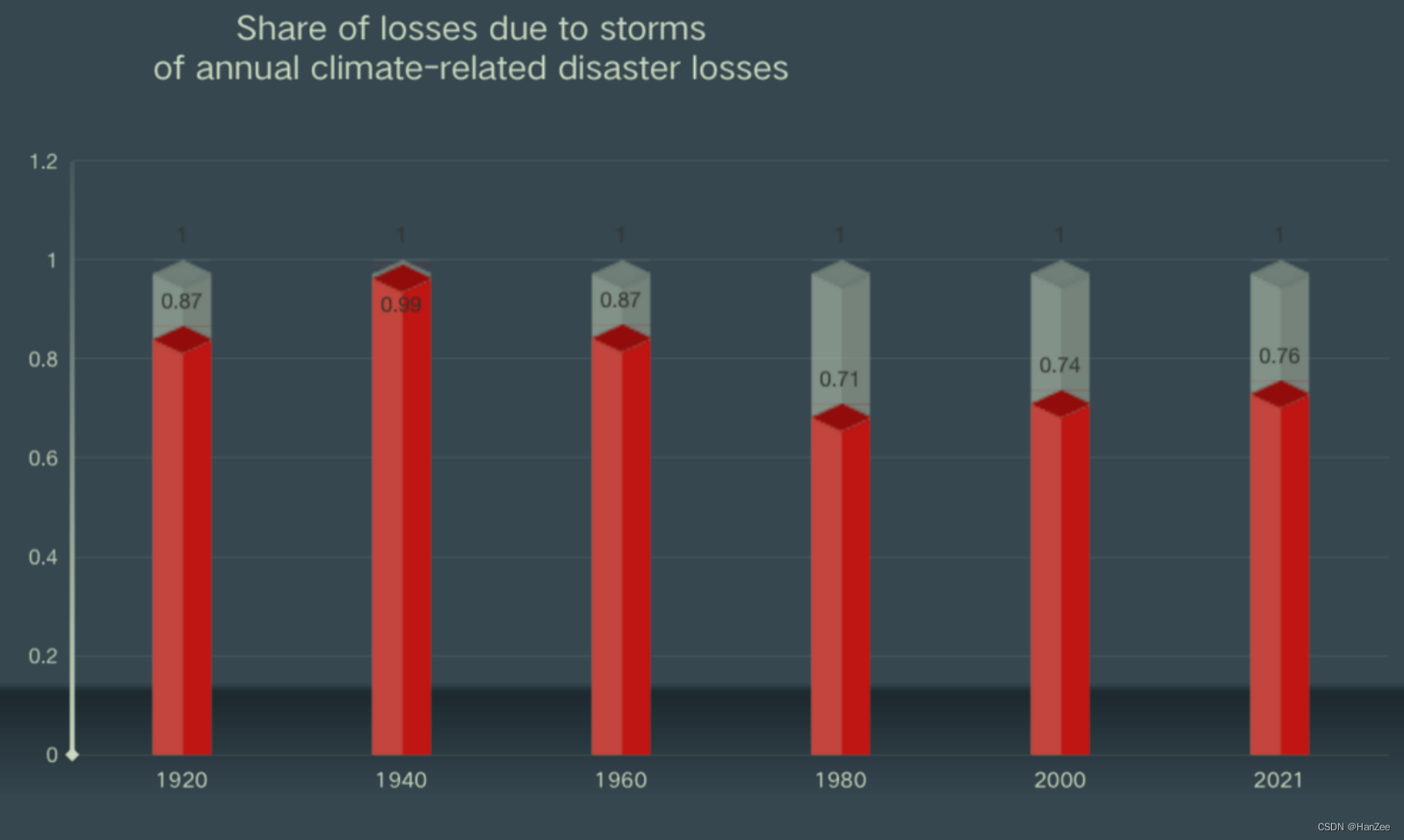
统计从1990到2021年的每类灾害造成的死亡人数
这个分析比较简单,直接提取数据,把每类灾害的费用放在一个变量里面,然后循环累加求和就可以得到最终的死亡人数,代码如下:
dict4={}
for i in data.values:
# print(i[6],i[35])
keys=list(dict4.keys())
if i[6] in keys and pd.isnull(i[34]) is False:
dict4[i[6]]+=int(i[34])
# print(1)
elif i[6] not in keys and pd.isnull(i[34]) is False:
dict4[i[6]]=int(i[34])
# print(2)
# else:
# continue
print(dict4)
统计每个洲由于灾害受影响人数与死亡人数与与经济损失并求出百分
首先利用for循环提取出每年的受影响人数,死亡人数,经济损失与属于那个洲,把上一步骤的ouput作为第二个step的input然后再次遍历提取,利用if筛选出每个洲的数据,最后得到每个洲总的数据,然后汇总求和,代码如下:
dict8={}
for i in data.values:
keys=list(dict7.keys())
if i[13] in keys and pd.isnull(i[44]) is False and pd.isnull(i[34]) is False and pd.isnull(i[38]) is False:
dict7[i[13]].append([i[5],i[34],i[38],i[44]])
elif i[13] not in keys and pd.isnull(i[44]) is False and pd.isnull(i[34]) is False and pd.isnull(i[38]) is False:
dict7[i[13]]=[[i[5],i[34],i[38],i[44]]]
# print(i[10],i[13],i[34],i[38],i[44])
# print(dict7)
a=[]
for i in dict7.items():
if i[0] =='Africa':
death=0
affect=0
economic=0
for v in i[1]:
# print(v
if v[0]=='Geophysical':
death+=v[1]
affect+=v[2]
economic+=v[3]
a.append([death,affect,economic])
if i[0] =='Americas':
death=0
affect=0
economic=0
for v in i[1]:
# print(v[0])
if v[0]=='Geophysical':
death+=v[1]
affect+=v[2]
economic+=v[3]
a.append([death,affect,economic])
# print(death,affect,economic)
if i[0] =='Asia':
death=0
affect=0
economic=0
for v in i[1]:
# print(v)
if v[0]=='Geophysical':
death+=v[1]
affect+=v[2]
economic+=v[3]
# print(death,affect,economic)
a.append([death,affect,economic])
if i[0] =='Oceania':
death=0
affect=0
economic=0
for v in i[1]:
if v[0]=='Geophysical':
death+=v[1]
affect+=v[2]
economic+=v[3]
a.append([death,affect,economic])
if i[0] =='Europe':
death=0
affect=0
economic=0
for v in i[1]:
# print(v)
if v[0]=='Geophysical':
death+=v[1]
affect+=v[2]
economic+=v[3]
a.append([death,affect,economic])
# # print(death,affect,economic)
sum1=int(0)
sum2=0
sum3=0
for i in a:
print(i)
# i[0]+=sum1
# i[1]+=sum2
# i[2]+=sum3
# print(sum1,sum2,sum3)
# for i in a:
# print(i[0]/sum1)
# print(i[1]/sum2)
# print(i[2]/sum3)
代码下载
链接: https://pan.baidu.com/s/1Qq0Smfl2lctkrUQcci65SA?pwd=hyu2 提取码: hyu2
–来自百度网盘超级会员v1的分享
可视化
链接: https://pan.baidu.com/s/1JApFuLmUcmSKtmpNc8P5xw?pwd=zqq5 提取码: zqq5
–来自百度网盘超级会员v1的分享

















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











