







上一章简单介绍了分词和分词框架的功能以及基本的使用,那么今天说一下分词常用的原则和算法支撑,因为在实际生产环境中,有时候可能需要根据自己的业务对已有的分词进行扩展或者像一些大型互联网的公司基本上都是直接自研发分词器,这个时候就需要对分词常用的算法需要有所了解,才有可能根据自己公司或者特定的业务数据来完善开源的分词或者自研发分词.对于分词算法而言可以大体上分为两大类,一类是基于概率,一类是基于词典
基于概率:
优点:是不需要依赖词典,通过算法计算出来哪两个词在一起出现的可能性大,就进行切分
缺点:是要完成这样的功能,其算法比较复杂,而且效率也不高,不易维护
基于词典:
优点:因为依赖已有的词典,一般分词的结果是有据可循,效率也是比较高的
缺点:需要用户维护一大推的词典
算法及原则:
常用的分词原则主要有:正向最大匹配原则和逆向最大匹配原则和双向匹配原则
常用的分词算法主要有:HMM,CRF,VIBERT,TIRE
接下来细说,每一种原则和算法的大概过程...
正向最大匹配原则:算法匹配速度很快,但准确度不高(长春市长春节快乐”用正向最大匹配分出的来得结果是“长春市,市长,节,快乐)
算法描述:
- S1为带切分字符串,S2为空,MaxLen为词典中的最大词长
- 判断S1是否为空,若是则输出S2
- 从S1左边开始,取出待处理字符串str(其中str的长度小于MaxLen)
- 查看str是否在词典中,若是则转5,若否则转6
- S2+=str+”/”,S1-=str,转2
- 将str最右边的一个字去掉
- 判断str是否为单字,若是则转5,若否则转4
算法举例:
比如说输入 “北京大学生前来应聘”,
- 第一轮:取子串 “北京大学生”,正向取词,如果匹配失败,每次去掉匹配字段最后面的一个字
- “北京大学生”,扫描 5 字词典,没有匹配,子串长度减 1 变为“北京大学”
- “北京大学”,扫描 4 字词典,有匹配,输出“北京大学”,输入变为“生前来应聘”
- 第二轮:取子串“生前来应聘”
- “生前来应聘”,扫描 5 字词典,没有匹配,子串长度减 1 变为“生前来应”
- “生前来应”,扫描 4 字词典,没有匹配,子串长度减 1 变为“生前来”
- “生前来”,扫描 3 字词典,没有匹配,子串长度减 1 变为“生前”
- “生前”,扫描 2 字词典,有匹配,输出“生前”,输入变为“来应聘””
- 第三轮:取子串“来应聘”
- “来应聘”,扫描 3 字词典,没有匹配,子串长度减 1 变为“来应”
- “来应”,扫描 2 字词典,没有匹配,子串长度减 1 变为“来”
- 颗粒度最小为 1,直接输出“来”,输入变为“应聘”
- 第四轮:取子串“应聘”
- “应聘”,扫描 2 字词典,有匹配,输出“应聘”,输入变为“”
- 输入长度为0,扫描终止
下面通过代码简单演示一下:
import java.util.ArrayList; import java.util.List; public class ZxiangSegment { /** * 设置模拟人工添加的词典 */ public void setDictionary() { dictionary.add("长春市"); dictionary.add("市长"); dictionary.add("长春"); dictionary.add("春节"); dictionary.add("市长"); dictionary.add("快乐"); } private List<String> dictionary = new ArrayList<String>(); static Integer MAX_LENGTH = 5; public List<String> leftMax(String str) { List<String> results = new ArrayList<String>(); String input = str; while( input.length() > 0 ) { String subSeq; // 每次取小于或者等于最大字典长度的子串进行匹配 if( input.length() < MAX_LENGTH) subSeq = input; else subSeq = input.substring(0, MAX_LENGTH); while( subSeq.length() > 0 ) { // 如果字典中含有该子串或者子串颗粒度为1,子串匹配成功 if( dictionary.contains(subSeq) || subSeq.length() == 1) { results.add(subSeq); // 输入中从前向后去掉已经匹配的子串 input = input.substring(subSeq.length()); break; // 退出循环,进行下一次匹配 } else { // 去掉匹配字段最后面的一个字 subSeq = subSeq.substring(0, subSeq.length() - 1); } } } return results; } public static void main(String[] args) { ZxiangSegment segment = new ZxiangSegment(); segment.setDictionary(); List<String> words = segment.leftMax("长春市长春节快乐"); for (String str:words){ System.out.println(str+" /"); } } }
看一下分词的效果,不是很理想,分出来的结果感觉很明显不符合人类语言的理解啊

逆向最大匹配原则:本算法是从后到前搜索字符串,然后找到最长的匹配结果输出,算法准确度比正向的高,下面通过代码演示一下
算法流程:同正向最大匹配原则一致,只不过顺序是相反的
算法举例:
比如说输入 “北京大学生前来应聘”,
- 第一轮:取子串 “生前来应聘”,逆向取词,如果匹配失败,每次去掉匹配字段最前面的一个字
- “生前来应聘”,扫描 5 字词典,没有匹配,字串长度减 1 变为“前来应聘”
- “前来应聘”,扫描 4 字词典,没有匹配,字串长度减 1 变为“来应聘”
- “来应聘”,扫描 3 字词典,没有匹配,字串长度减 1 变为“应聘”
- “应聘”,扫描 2 字词典,有匹配,输出“应聘”,输入变为“大学生前来”
- 第二轮:取子串“大学生前来”
- “大学生前来”,扫描 5 字词典,没有匹配,字串长度减 1 变为“学生前来”
- “学生前来”,扫描 4 字词典,没有匹配,字串长度减 1 变为“生前来”
- “生前来”,扫描 3 字词典,没有匹配,字串长度减 1 变为“前来”
- “前来”,扫描 2 字词典,有匹配,输出“前来”,输入变为“北京大学生”
- 第三轮:取子串“北京大学生”
- “北京大学生”,扫描 5 字词典,没有匹配,字串长度减 1 变为“京大学生”
- “京大学生”,扫描 4 字词典,没有匹配,字串长度减 1 变为“大学生”
- “大学生”,扫描 3 字词典,有匹配,输出“大学生”,输入变为“北京”
- 第四轮:取子串“北京”
- “北京”,扫描 2 字词典,有匹配,输出“北京”,输入变为“”
- 输入长度为0,扫描终止
import java.util.ArrayList; import java.util.List; /** * 简单演示一下逆行最大匹配正则 */ public class Segmentation1 { private List<String> dictionary = new ArrayList<String>(); //要分的词 private String request = "北京大学生前来应聘"; /** * 设置模拟人工添加的词典 */ public void setDictionary() { dictionary.add("北京"); dictionary.add("北京大学"); dictionary.add("大学"); dictionary.add("大学生"); dictionary.add("生前"); dictionary.add("前来"); dictionary.add("应聘"); } private boolean isIn(String s, List<String> list) { for(int i=0; i<list.size(); i++) { if(s.equals(list.get(i))) return true; } return false; } /** * 从右边到左边开始进行词的查找和切分 * @return */ public String rightMax() { String response = ""; String s = ""; for(int i=request.length()-1; i>=0; i--) { s = request.charAt(i) + s; if(isIn(s, dictionary) && tailCount(s, dictionary)==1) { response = (s + "/") + response; s = ""; } else if(tailCount(s, dictionary) > 0) { } else { response = (s + "/") + response; s = ""; } } return response; } /** * 词的总数量 * @param s * @param list * @return */ private int tailCount(String s, List<String> list) { int count = 0; for(int i=0; i<list.size(); i++) { if((s.length()<=list.get(i).length()) && (s.equals(list.get(i).substring(list.get(i).length()-s.length(), list.get(i).length())))) count ++; } return count; } public static void main(String[] args) { Segmentation1 seg = new Segmentation1(); seg.setDictionary(); String response2 = seg.rightMax(); System.out.println(response2); } }
看一下效果:

双向匹配原则:正向最大匹配算法和逆向最大匹配算法进行比较,从而确定正确的分词方法
算法流程:
- 比较正向最大匹配和逆向最大匹配结果
- 如果分词数量结果不同,那么取分词数量较少的那个
- 如果分词数量结果相同
- 分词结果相同,可以返回任何一个
- 分词结果不同,返回单字数比较少的那个
下面看一下简单的Java代码实现:
public List<String> segment() { List<String> fmm = this.leftMax(); List<String> bmm = this.rightMax(); // 如果分词的结果不同,返回长度较小的 if( fmm.size() != bmm.size()) { if ( fmm.size() > bmm.size()) return bmm; else return bmm; } // 如果分词的词数相同 else { int fmmSingle = 0, bmmSingle = 0; boolean isEqual = true; for( int i = 0; i < bmm.size(); i ++) { if( !fmm.get(i).equals(bmm.get(i))) { isEqual = false; } if( fmm.get(i).length() == 1) fmmSingle ++; if( bmm.get(i).length() == 1) bmmSingle ++; } // 如果正向、逆向匹配结果完全相等,返回任意结果 if ( isEqual ) { return fmm; // 否则,返回单字数少的匹配方式 } else if ( fmmSingle > bmmSingle) return bmm; else return fmm; } }
ok,分词常用的匹配原则就简单介绍完了,当然开源的一些分词器也都是基于这些原则来组合或者优化进行分词,只不过在存储结构上会做不同的优化调整,比如常用的就是Tire树结构,这个后面也是会介绍到的,下面开始介绍常用的分词算法.
HMM模型和VITERBI算法: 隐式马尔科夫模型和维特比算法(寻找最可能的隐藏状态序列)
HMM模型可以应用在很多领域,所以它的模型参数描述一般都比较抽象,以下篇幅针对HMM的模型参数介绍直接使用它在中文分词中的实际含义来讲:
HMM模型五元组:
- StatusSet: 状态值集合(比如今天的天气是 晴天,阴天,雨天)
- ObservedSet: 观察值集合(比如今天的气候是 干燥,湿润,凉爽)
- TransProbMatrix: 转移概率矩阵
- EmitProbMatrix: 发射概率矩阵
- InitStatus: 初始状态分布
HMM模型使用场景:
- 参数(StatusSet,TransProbMatrix,EmitRobMatrix,InitStatus)已知的情况下,求解观察值序列。(Forward-backward算法)
- 参数(ObservedSet,TransProbMatrix,EmitRobMatrix,InitStatus)已知的情况下,求解状态值序列。(viterbi算法)
- 参数(ObservedSet)已知的情况下,求解(TransProbMatrix,EmitRobMatrix,InitStatus)。(Baum-Welch算法)
上面三种应用场景,第二种是最常用的,比如'中文分词','词性识别','语言识别','新词发现','命名实体识别'等,而今天要介绍的就是使用HMM在中文分词中的使用:抛开算法底层的数学公式,直接通过列子来进行说明.对于HMM在分词中的使用,需要了解一下'BMES',如果看过jieba或者hanlp中都会看到这个影子的,那么这几个字母是啥意思呢?
B:代表该字是词语中的起始字
M:代表是词语中的中间字
E:代表是词语中的结束字
S:代表是单字成词,理解这个概念很重要,因为虽然说是分词,其实本质就是对于给定的一句话,输出对应BMES的切割组合,比如如果要对'去北京大学玩'分词的话,只需要输出对应S/BMME/S,其实分词结果就是'去/北京大学/玩',那么如何实现这个过程呢?下面就详细的分析一下:首先整个分词结果,看下面的图

很清楚对吧,好 全面进入HMM世界:
HMM模型作的两个基本假设:
1.齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其它时刻的状态及观测无关,也与时刻t无关;
P(states[t] | states[t-1],observed[t-1],...,states[1],observed[1]) = P(states[t] | states[t-1]) t = 1,2,...,T
2.观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其它观测和状态无关,
P(observed[t] | states[T],observed[T],...,states[1],observed[1]) = P(observed[t] | states[t]) t = 1,2,...,T
HMM模型有三个基本问题:
- 1.概率计算问题,给定模型 λ=(A,B,π)λ=(A,B,π) 和观测序列 O=(o1,o2,...,oT)O=(o1,o2,...,oT) ,怎样计算在模型 λλ 下观测序列O出现的概率 P(O|λ)P(O|λ) ,也就是Forward-backward算法;
- 2.学习问题,已知观测序列 O=(o1,o2,...,oT)O=(o1,o2,...,oT) ,估计模型 λ=(A,B,π)λ=(A,B,π) ,使得在该模型下观测序列的概率 P(O|λ)P(O|λ) 尽可能的大,即用极大似然估计的方法估计参数;
- 3.预测问题,也称为解码问题,已知模型 λ=(A,B,π)λ=(A,B,π) 和观测序列 O=(o1,o2,...,oT)O=(o1,o2,...,oT) ,求对给定观测序列条件概率 P(S|O)P(S|O) 最大的状态序列 I=(s1,s2,...,sT)I=(s1,s2,...,sT) ,即给定观测序列。求最有可能的对应的状态序列
仍然以“去北京大学玩”为例,那么“去北京大学玩”就是观测序列。
而“去北京大学玩”对应的“SBMMES”则是隐藏状态序列,我们将会注意到B后面只能接(M或者E),不可能接(B或者S);而M后面也只能接(M或者E),不可能接(B或者S)。
接下来具体阐述5元组,在分词中的含义
状态初始概率:每个词的初始概率
其中的概率值都是取对数之后的结果(可以让概率相乘转变为概率相加),其中-3.14e+100代表负无穷,对应的概率值就是0。这个概率表说明一个词中的第一个字属于{B、M、E、S}这四种状态的概率,如下可以看出,E和M的概率都是0,这也和实际相符合:开头的第一个字只可能是每个词的首字(B),或者单字成词(S)。这部分对应jieba/finaseg/prob_start.py,具体可以进入源码查看

状态转移概率:
马尔科夫链中很重要的一个知识点,一阶的马尔科夫链最大的特点就是当前时刻T = i的状态states(i),只和T = i时刻之前的n个状态有关,即{states(i-1),states(i-2),...,states(i-n)}。
再看jieba中的状态转移概率,其实就是一个嵌套的词典,数值是概率值求对数后的值,如下所示
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155},
'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937},
'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226},
'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}
P['B']['E']代表的含义就是从状态B转移到状态E的概率,由P['B']['E'] = -0.5897149736854513,表示当前状态是B,下一个状态是E的概率对数是-0.5897149736854513,对应的概率值是0.6,相应的,当前状态是B,下一个状态是M的概率是0.4,说明当我们处于一个词的开头时,下一个字是结尾的概率要远高于下一个字是中间字的概率
状态发射概率:根据假设可知,观测值只取决于当前状态值
简单公式表示:P(observed[i],states[j]) = P(states[j]) * P(observed[i] | states[j]),其中,P(observed[i] | states[j])就是从状态发射概率中获得的。


P['B']['一']代表的含义就是状态处于'B',而观测的字是‘一’的概率对数值为P['B']['一'] = -3.6544978750449433,有了这三个参数之后使用维特比算法串联起来就可以进行分词了..
维特比算法
维特比算法的基础可以概括成下面三点:
 数学之美维特比算法
数学之美维特比算法
输入样例:
去北京大学玩Viterbi算法计算过程如下:
定义变量
二维数组 weight[4][6],4是状态数(0:B,1:E,2:M,3:S),6是输入句子的字数。比如 weight[0][2] 代表 状态B的条件下,出现'北'这个字的可能性,比如 path[0][2] 代表 weight[0][2]取到最大时,前一个字的状态,比如 path[0][2] = 1, 则代表 weight[0][2]取到最大时,前一个字(也就是明)的状态是E。记录前一个字的状态是为了使用viterbi算法计算完整个 weight[4][6] 之后,能对输入句子从右向左地回溯回来,找出对应的状态序列。
使用InitStatus对weight二维数组进行初始化
已知InitStatus如下:
-
#B
-
-0.26268660809250016
-
#E
-
-3.14e+100
-
#M
-
-3.14e+100
-
#S
-
-1.4652633398537678
且由EmitProbMatrix可以得出
-
Status(B) -> Observed(北) : -5.79545
-
Status(E) -> Observed(北) : -7.36797
-
Status(M) -> Observed(北) : -5.09518
-
Status(S) -> Observed(北) : -6.2475
所以可以初始化 weight[i][0] 的值如下:
-
weight[0][0] = -0.26268660809250016 + -5.79545 = -6.05814
-
weight[1][0] = -3.14e+100 + -7.36797 = -3.14e+100
-
weight[2][0] = -3.14e+100 + -5.09518 = -3.14e+100
-
weight[3][0] = -1.4652633398537678 + -6.2475 = -7.71276
注意上式计算的时候是相加而不是相乘,因为之前取过对数的原因。
遍历句子计算整个weight二维数组
-
//遍历句子,下标i从1开始是因为刚才初始化的时候已经对0初始化结束了
-
for(size_t i = 1; i < 6; i++)
-
{
-
// 遍历可能的状态
-
for(size_t j = 0; j < 4; j++)
-
{
-
weight[j][i] = MIN_DOUBLE;
-
path[j][i] = - 1;
-
//遍历前一个字可能的状态
-
for(size_t k = 0; k < 4; k++)
-
{
-
double tmp = weight[k][i- 1] + _transProb[k][j] + _emitProb[j][sentence[i]];
-
if(tmp > weight[j][i]) // 找出最大的weight[j][i]值
-
{
-
weight[j][i] = tmp;
-
path[j][i] = k;
-
}
-
}
-
}
-
}
如此遍历下来,weight[4][6] 和 path[4][6] 就都计算完毕。
确定边界条件和路径回溯
边界条件如下:
对于每个句子,最后一个字的状态只可能是 E 或者 S,不可能是 M 或者 B。
所以在本文的例子中我们只需要比较 weight[1(E)][5] 和 weight[3(S)][5] 的大小即可。
在本例中:
-
weight[1][5] = -111.2;
-
weight[3][5] = -111.3;
所以 S > E,也就是对于路径回溯的起点是 path[3][5]。
回溯的路径是:
SEMMBS倒序一下就是:
S/BMME/S所以切词结果就是:
去/北京大学/玩至此HMM模型就讲解完了...
但是在这里说点其他的,就是因为HMM是基于3种假设的存在,且每种假设是独立的,这样就存在一个显然的缺点就是,它忽略了上下文的关系...,
所以在实际使用中,对HMM都会进行一些列的优化,比如常用MEMM来解决HMM的独立假设问题,但是它本身会存在标注偏移的问题,之后就有人提出了CRF(条件随机场),它的出现解决了HMM和MEMM存在的所有问题,对于未登录的新词,以及在词性标注和命名实体这种应用的情况下,表现都要比HMM好.下面来做一个详细对比
HMM-隐马尔科夫模型
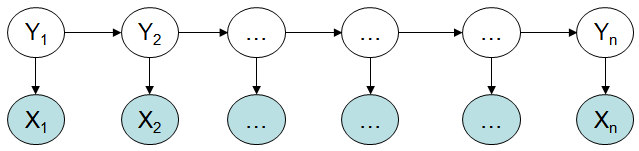
图1. 隐马尔科夫模型
隐马尔科夫模型的缺点:
1、HMM只依赖于每一个状态和它对应的观察对象:
序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
2、目标函数和预测目标函数不匹配:
HMM学到的是状态和观察序列的联合分布P(Y,X),而预测问题中,我们需要的是条件概率P(Y|X)。
MEMM-最大熵隐马尔可夫模型
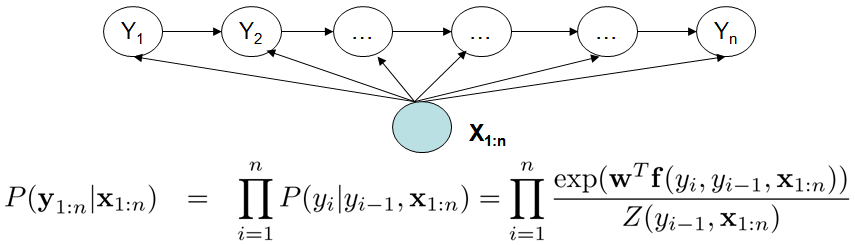
图2. 最大熵马尔科夫模型
MEMM考虑到相邻状态之间依赖关系,且考虑整个观察序列,因此MEMM的表达能力更强;MEMM不考虑P(X)减轻了建模的负担,同时学到的是目标函数是和预测函数一致。
MEMM位置标记问题
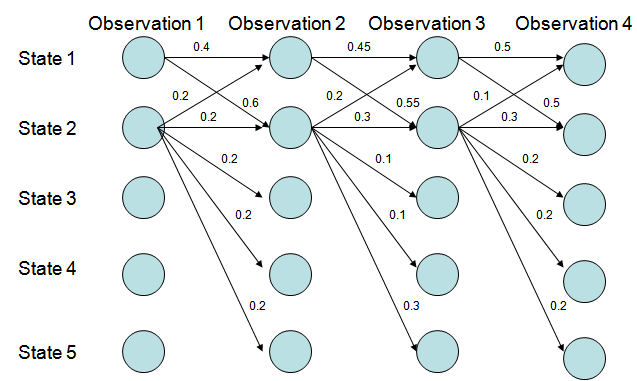
图3. Viterbi算法解码MEMM,状态1倾向于转换到状态2,同时状态2倾向于保留在状态2;
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066。
图3中状态1倾向于转换到状态2,同时状态2倾向于保留在状态2;但是得到的最优的状态转换路径是1->1->1->1,为什么呢?因为状态2可以转换的状态比状态1要多,从而使转移概率降低;即MEMM倾向于选择拥有更少转移的状态。这就是标记偏置问题。而CRF很好地解决了标记偏置问题。
条件随机场-CRF

MEMM是局部归一化,CRF是全局归一化
另一方面,MEMMs不可能找到相应的参数满足以下这种分布:
a b c --> a/A b/B c/C p(A B C | a b c) = 1
a b e --> a/A b/D e/E p(A D E | a b e) = 1
p(A|a)p(B|b,A)p(C|c,B) = 1
p(A|a)p(D|b,A)p(E|e,D) = 1
但是CRF可以找到模型满足这种分布。
1)生成式模型or判别式模型(假设 o 是观察值,m 是模型。)
a)生成式模型:无穷样本 -> 概率密度模型 = 产生式模型 -> 预测
如果对 P(o|m) 建模,就是生成式模型。其基本思想是首先建立样本的概率密度模型,再利用模型进行推理预测。要求已知样本无穷或尽可能的大限制。这种方法一般建立在统计力学和 Bayes 理论的基础之上。
HMM模型对转移概率和表现概率直接建模,统计共同出现的概率,是一种生成式模型。
b)判别式模型:有限样本 -> 判别函数 = 判别式模型 -> 预测
如果对条件概率 P(m|o) 建模,就是判别模型。其基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。代表性理论为统计学习理论。
CRF是一种判别式模型。MEMM不是一种生成式模型,它是一种基于下状态分类的有限状态模型。
2)拓扑结构
HMM和MEMM是一种有向图,CRF是一种无向图
3)全局最优or局部最优
HMM对转移概率和表现概率直接建模,统计共现概率。
MEMM是对转移概率和表现概率建立联合概率,统计时统计的是条件概率,由于其只在局部做归一化,所以容易陷入局部最优。
CRF是在全局范围内统计归一化的概率,而不像是MEMM在局部统计归一化概率。是全局最优的解。解决了MEMM中标注偏置的问题。
4)优缺点比较
优点:
a)与HMM比较。CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
b)与MEMM比较。由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
c)与ME比较。CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布。
缺点:
训练代价大、复杂度高
对于开源分词器Hanlp中就使用到了HMM和CRF两种分词模型,如果像看JAVA版本的CRF完整实现,建议去分析一下Hanlp的源码
好了关于分词相关的算法模型以及原则就讲解到这里了.















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









