







1、requests入门
安装requests:pip install requests
1.1 用User-Agent字典写入headers处理反爬
import requests
# 1.get拼接方式
# query = input("please input ")
# url = f'https://www.sogou.com/web?query={query}'
url = 'https://www.sogou.com/web?query=周杰伦'
headersDic = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
} #字典
resp = requests.get(url,headers=headersDic) #headers为反爬处理
print(resp) #返回200表示成功
print(resp.text) #取页面源代码
1.2 post方式
#2.post拼接方式
url = "https://fanyi.baidu.com/sug"
s = input("please input ")
data = {"kw":s}
resp = requests.post(url,data=data)
print(resp.json())
1.3 设置param和userAgent处理反爬
#3.存在反爬机制的情况
# 解决:设置userAgent
url = "douban电影top的地址"
param = {
"type": "11",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
resp = requests.get(url=url,params=param,headers=header)
print(resp.json())
resp.close() #关掉resp,否则请求次数过多会报错
2、requests高阶
2.1 模拟浏览器登录(处理cookie)
Cookie,它是客户端浏览器用来保存服务端数据的一种机制。
当通过浏览器进行网页访问的时候,服务器可以把某一些状态数据以 key-value的方式写入到 Cookie 里面存储到客户端浏览器。然后客户端下一次再访问服务器的时候,就可以携带这些状态数据发送到服务器端,服务端可以根据 Cookie 里面携带的内容来识别使用者。
Session 表示一个会话,它是属于服务器端的容器对象。
默认情况下,针对每一个浏览器的请求,Servlet 容器都会分配一个 Session。Session 本质上是一个 ConcurrentHashMap,可以存储当前会话产生的一些状态数据。
Cookie与Session之前的联系:
Http 协议本身是一个无状态协议,也就是服务器并不知道客户端发送过来的多次请求是属于同一个用户。Session 是用来弥补 Http 无状态的不足,简单来说,服务器端可以利用session 来存储客户端在同一个会话里面的多次请求记录。基于服务端的 session 存储机制,再结合客户端的 Cookie 机制,就可以实现有状态的 Http 协议。
cookie存储是有效期,当客户端存储的cookie失效后,服务端的session不会立即销毁,会有一个延时,服务端会定期清理无效session,不会造成无效数据占用存储空间的问题。
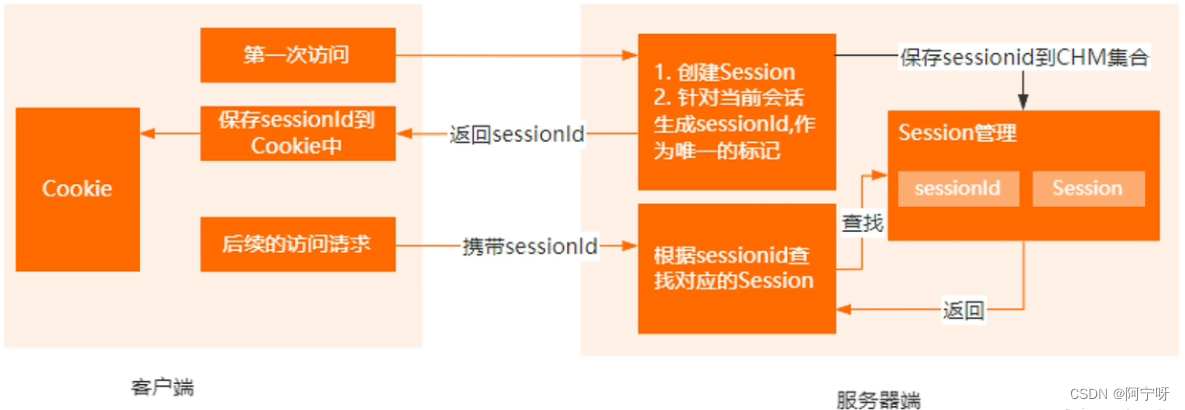
(1)客户端第一次访问服务端的时候,服务端会针对这次请求创建一个会话,并生成一个唯一的 sessionID 来标注这个会话。
(2)然后服务端把这个 sessionID 写入到客户端浏览器的 cookie 里面,用来实现客户端状态的保存。
(3)在后续的请求里面,每次都会携带sessionID,服务器端就可以根据这个sessionID 来识别当前的会话状态。
总的来说,Cookie 是客户端的存储机制,Session 是服务端的存储机制。
1.登录 -> 找cookie
2.带cookie去请求书架url -> 获得书架的内容
需要把上述两操作连起来
方法:使用session进行请求,session是会话,过程中cookie不会丢失
例子:爬取17K小说网的书架
import requests
#新建会话
session = requests.session()
# data = {
# "loginName":"自己的用户名",
# "password":"自己的密码"
# } #因为data被隐藏,所以直接用cookie登录去看书架
headers = {
"Cookie": "cookie里的内容"
}
# 登录+从书架上拿数据
url = "书架部分登录的url" #书架url
# resp = session.post(url,data=data)
resp = session.get(url,headers=headers)
resp.encoding = "utf-8"
print(resp.text)
2.2 防盗链处理
存在以下情况进行防盗链处理:
1.页面标签通过js写入。
2.标签中的src与抓包的XHR中的srcurl存在一部分不同。
3.有referer,进行溯源,找上一级(即找请求的上一级)。(防盗链的本质)
例子:下载视频
import requests
# 爬视频
# 处理防盗链:1->2->3,若2丢失则找不到3
# 所以1为videoStatusUrl,2为url也就是Referer,3为videoUrl也就是视频下载地址
# 对1的videoStatus的视频抓包地址进行拼接可以得到3
url = "视频打开的网页地址"
videoStatusUrl = "视频的Status地址"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Cookie": "cookie里的内容",
"Referer": url #防盗链,即videoStatusUrl的上一级
}
# resp = requests.get(url)
videoResp = requests.get(videoStatusUrl,headers=headers)
# 把爬取的videoStatus转为json再根据json对象取视频的url
videoUrl = videoResp.json()["videoInfo"]["videos"]["srcUrl"]
#替换字符
oldStr = videoResp.json()["systemTime"]
newStr = url.split("_")[1]
videoUrl = videoUrl.replace(oldStr,"cont-"+newStr)
videoResp.close()
#下载视频,写入文件
result = requests.get(videoUrl)
with open("attachment/%s.mp4"%newStr,"wb") as f:
f.write(result.content)
result.close()
f.close()















 8677
8677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









