









都说学如逆水行舟,不进则退,最近工作遇到很多新的知识,需要看很多学习视频,虽说现在网络上很多学习视频能让我们快速去学习新技能,但对于需要工作的人来说,一个视频一个多小时,实在是没时间也看不下去呀,所以想着能不能把文稿提取出来然后结合着ppt看,这样估计一小时的课程,15分钟就能学习完了。然后,嗯,下面是使用python实现了这个功能。
设计思路如下:
1.提取文字
提取文稿是对音频的操作,也就是音频语音识别,自己写肯定是写不来的(估计写出来我学习视频都看完了),所以我百度了一下,发现腾讯/百度/讯飞都提供有这种语音转文字的API,那我就用百度的做了。具体可以去百度智能云查看https://login.bce.baidu.com/
然后找到语音识别API文档https://cloud.baidu.com/doc/SPEECH/index.html
看一下它的api怎么用,和对输入的音频有什么要求

百度语音识别api文档
那其实知道了怎么提取音频文稿,剩下的工作就是想着怎么把视频处理成对应的格式,由于百度的语音识别只能处理60以内的音频,所以还得对音频和提取的文稿进行剪接和拼接。
2.提取音频
把目标视频文件转换为百度API所支持的音频(对应的格式、参数)。
从视频中提取音频可以使用FFmpeg,在音频提取过程中还要对音频的采样率、声道数、码率进行设置,同时指定输出音频格式。除此之外,由于百度API最多只支持60秒长度的音频,而我们需要转换的视频长度通常要远高于这个时长,所以还需要使用pydub对音频文件进行切割,然后分段进行文字转换。所以从视频到音频的大概流程应该是这样的:
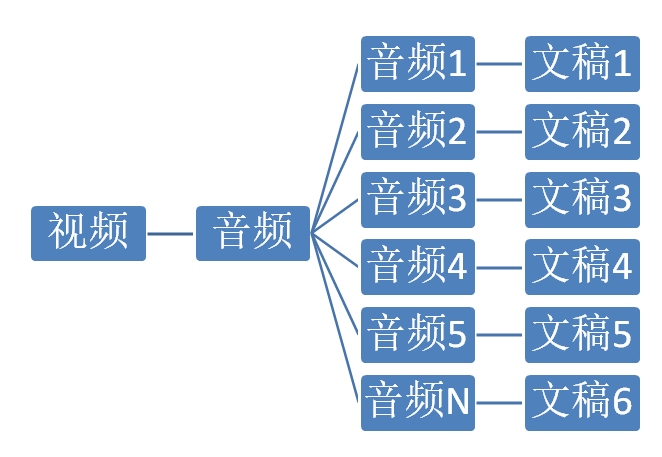
原理不难,但是在实现过程还是会有些小问题要解决的,具体看怎么做吧
第一步:视频转音频
将视频转成音频可以使用FFmpeg,它是一个非常快速的视频和音频转换器,在python中使用ffmpeg需要借助于ffmpy3这个库。
这里有很重要的一点是FFmpeg一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,所以得把这个程序下载下来
首先是FFmpeg的简介:https://baike.baidu.com/item/ffmpeg/2665727?fr=aladdin
其次是FFmpeg的基础使用:https://www.jianshu.com/p/ddafe46827b7
ffmpeg的下载地址:https://ffmpeg.zeranoe.com/builds/。
可以看到共有3个版本,Static,Shared,Dev。这个时候也有一些小问题,有两种使用方式。
使用Static方式,但是需要配置环境变量
使用Shared(我是使用这种),直接下载下来后,把bin里面的ffmpeg.exe文件,放到和你的代码文件同目录下就可以运行了,但是这种方式稍微麻烦了一些,还是建议用第一种。
回到正题:
下面定义了两个方法,一个是转成wav文件的,一个是转成pcm文件,并且指定声道数,采样率等等满足百度api的参数输入要求。
那为什么要转两次呢?为什么不直接转pcm处理就行,这个就是一些小问题了,pcm文件的属性里面,没有包括时长duration这个内容,也就是我没法判断音频时长并且对音频进行60秒切割。而wav文件里面有这个内容。
所以我是先将视频转成wav文件的音频,并切割处理后再转为pcm文件,最后调用语音识别api
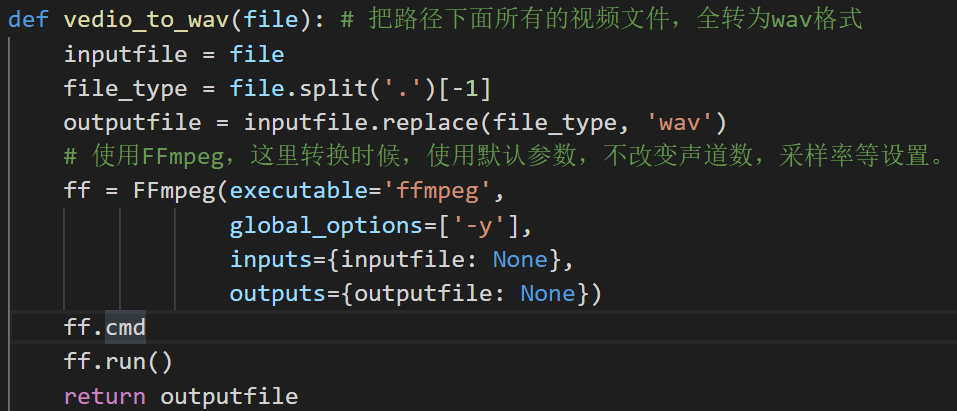
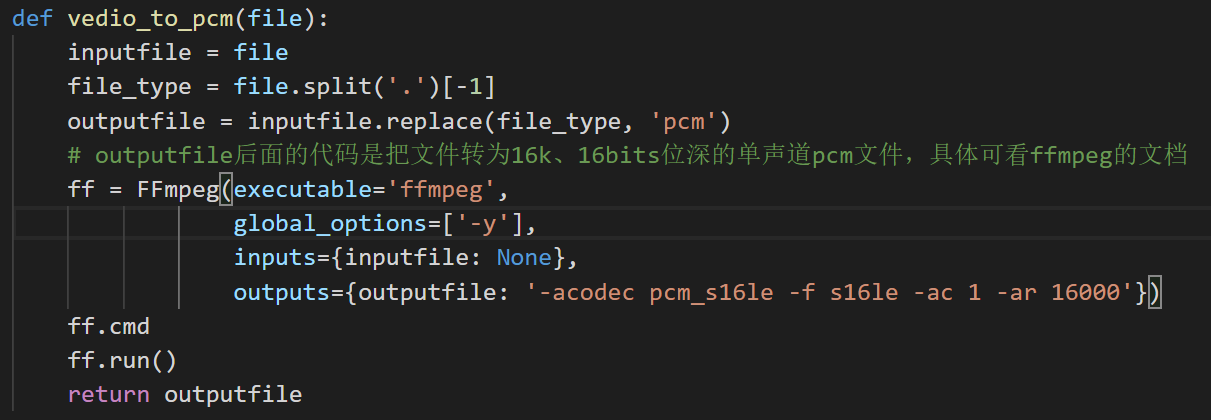
第二步:音频切割
这部分就是将音频切割成N个60秒短音频,最重要的就是第40行代码,读取wav音频文件中的时长信息。
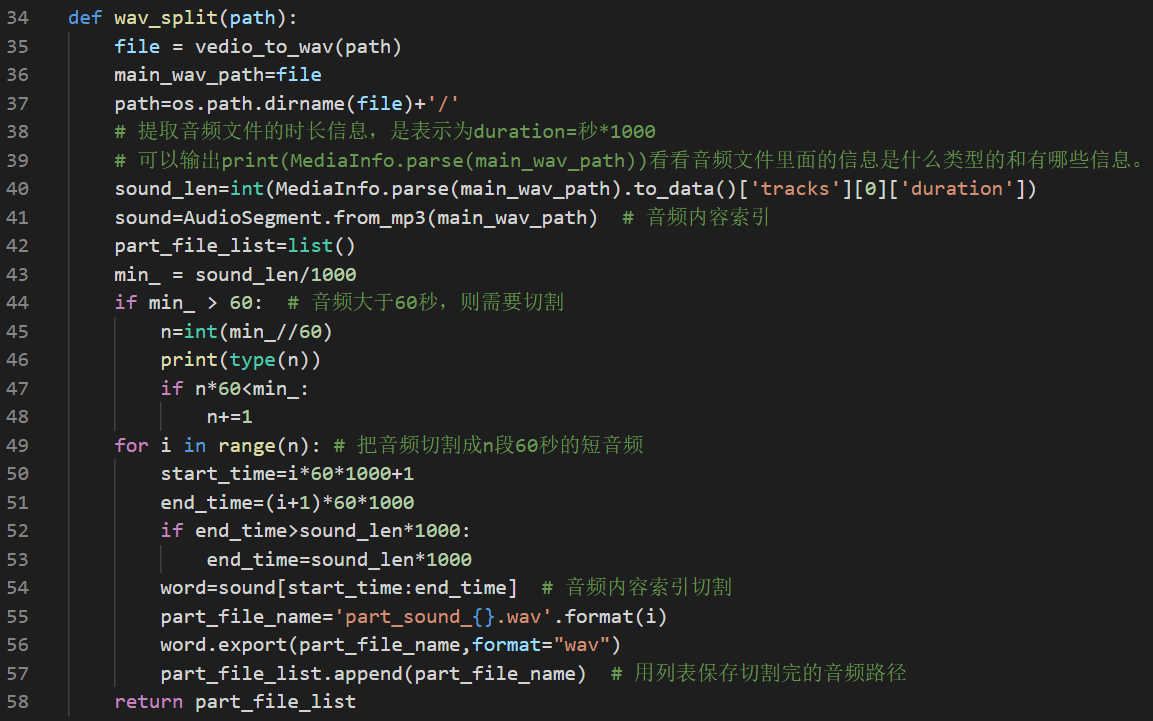
第三步:调用百度语音识别api
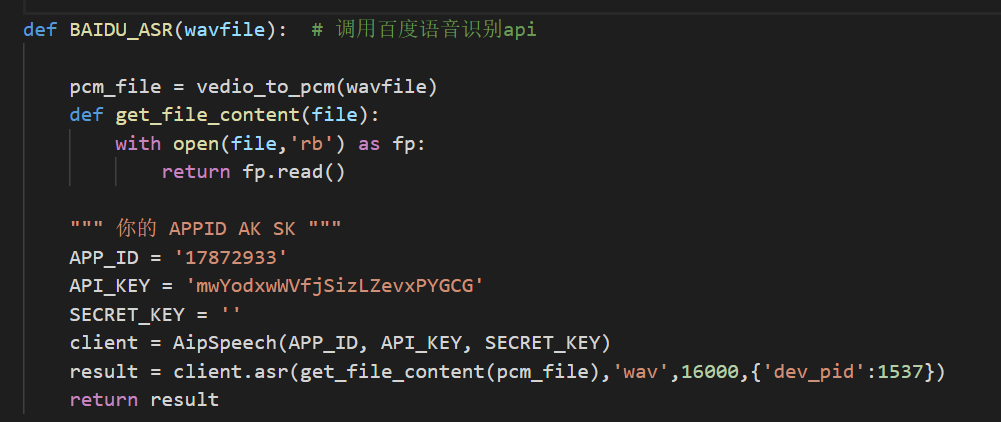
上面这段代码中,首先建立一个语音识别对象client,然后调用asr方法完成文字的提取,'dev_pid'参数用来指定音频中的语言类型,1537对应的是纯中文普通话。目前支持的语言类型有以下几种:
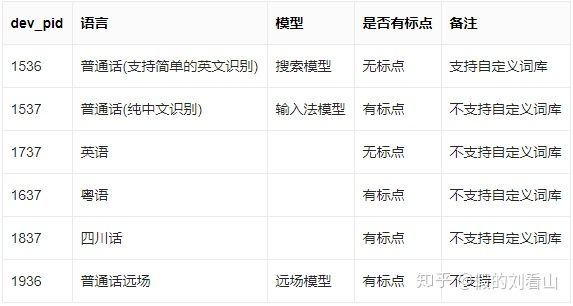
api文档:http://ai.baidu.com/docs#/ASR-Online-Python-SDK/b3e9a8da
这里讲一下api key怎么获取
1.打开百度智能云:https://cloud.baidu.com/
2.注册账号和登陆
3.在控制台里的用户中心,个人开发者实名认证
4.点击最左边的语音技术栏目,创建应用,这里随便填,创建成功后就可以在应用列表里找到看到AppID,API Key,和Secret Key等内容了
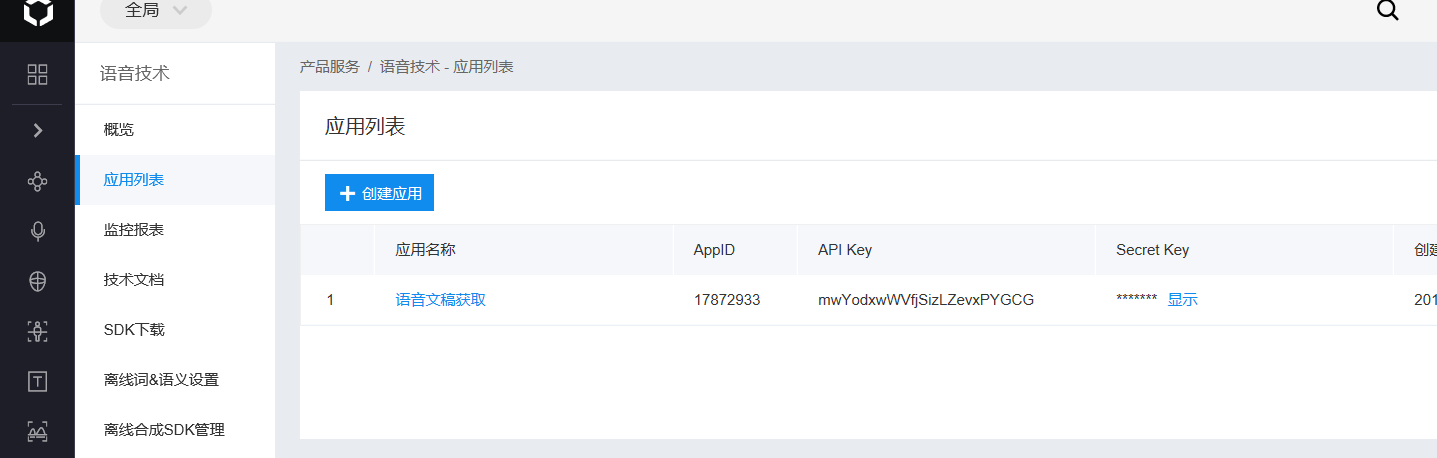
第四步:最后就是运行代码了
下面的perfect_path是把路径下的所有视频文件保存到列表里面,方便批量处理
其次,由于在转换音频时候,在文件夹里面都会出现新的wav,pcm文件,所以在最后还得把着一些全给他删除掉。
最后出来的结果如图:
运行过程产生很多pcm,wav文件,最后会自动清理掉
上面基本就是所有的代码和运行步骤了。下面再补充一些工具的安装
Python ffmpy3与FFmpeg的安装
(1)ffmpy3直接就 命令行,pip install ffmpy3
(2)官网下载FFmpeg,根据自身电脑版本下载相应安装包
使用示例:
from ffmpy3 import FFmpeg
# 最简单的用法是将媒体从一种格式转换为另一种格式(在本例中是从MP4转换为MPEG传输流),同时保留所有其他属性:
ff = FFmpeg(inputs={'test.mp4': None},
outputs={'output.ts': None})
print(ff.cmd)
ff.run()
在运行以上代码进行媒体文件格式转换时,会出现以下错误,这是因为ffmpy3中没有自带ffmpeg可执行文件
File "E:\Python\Python36\lib\site-packages\ffmpy3.py", line 124, in run
raise FFExecutableNotFoundError("Executable '{0}' not found".format(self.executable))
ffmpy3.FFExecutableNotFoundError: Executable 'ffmpeg' not found
解决方法:解压ffmpeg文件,将ffmpeg文件中的可执行文件ffmpeg.exe复制到当前项目文件目录下(也就是上面提到的方法二)
百度语音识别api工具包安装以及音频切割,音频数据读取的工具包,如下图,缺什么就pip install 就行

代码也可在github上获取

















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









