






可以去github直接下载完整代码
https://github.com/NatuselectroNic/-Scrapy-5i5j-MongoD
使用 Scrapy 爬取 5i5j 网站房产数据并存储到 MongoDB
在数据获取和处理方面,网络爬虫是一种强大的工具。本教程将向您展示如何使用 Python 的 Scrapy 网络爬虫框架从 5i5j 网站上提取房产数据,并将提取的信息存储到 MongoDB 数据库中。
当您开始使用Scrapy爬取数据时,确保您的环境设置正确非常重要。以下是一份更详细的环境设置说明:
一、环境设置
安装 Python
确保您的计算机上安装了 Python。您可以在Python官方网站上下载并安装最新版本的 Python。
安装 pip
在安装 Python 时,通常会一并安装 pip,它是 Python 包管理工具。但如果您的 Python 版本较旧或者没有安装 pip,请根据您的操作系统安装 pip。
安装 Scrapy
使用 pip 安装 Scrapy。在命令行中执行以下命令:
pip install scrapy
这将安装最新版本的 Scrapy 爬虫框架。
安装 pymongo
要将爬取到的数据存储到 MongoDB 中,需要安装 pymongo 这个 Python MongoDB 客户端库。在命令行中执行以下命令:
pip install pymongo
安装 MongoDB
如果您尚未安装 MongoDB 数据库,您可以从MongoDB官方网站下载适用于您操作系统的版本并进行安装。
创建 MongoDB 数据库和集合
确保您已经在本地启动了 MongoDB 服务。然后使用以下命令连接到 MongoDB,并创建一个数据库和集合来存储爬取到的数据:
mongo
use pachong # 创建名为 pachong 的数据库
db.createCollection("pachong") # 在 pachong 数据库中创建名为 pachong 的集合
创建Scrapy项目
scrapy startproject pachong2 #创建pachong2项目
cd pachong2 #移动到该pachong2目录下

这里以创建“pachong3”为例
创建爬虫文件
scrapy genspider woaiwojia bj.5i5j.com
#woaiwojia为爬虫文件名,后续一直使用该文件名
#bj.5i5j.com为网站domain(域名)
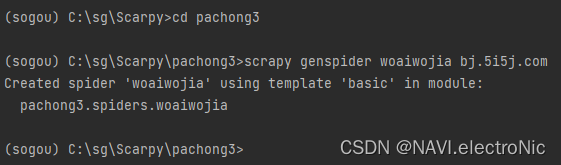
最终得到以下文件目录
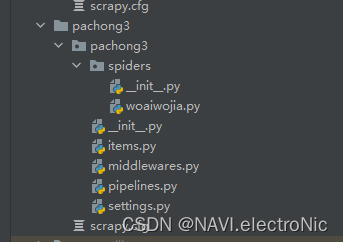
spiders下的woaiwojia.py即为主体爬虫文件
现在您已经设置好了 Python、Scrapy、pymongo 和 MongoDB,可以开始编写和运行 Scrapy Spider 来爬取数据并将其存储到 MongoDB 数据库中了。
二、观察要爬取的网站
网站首页: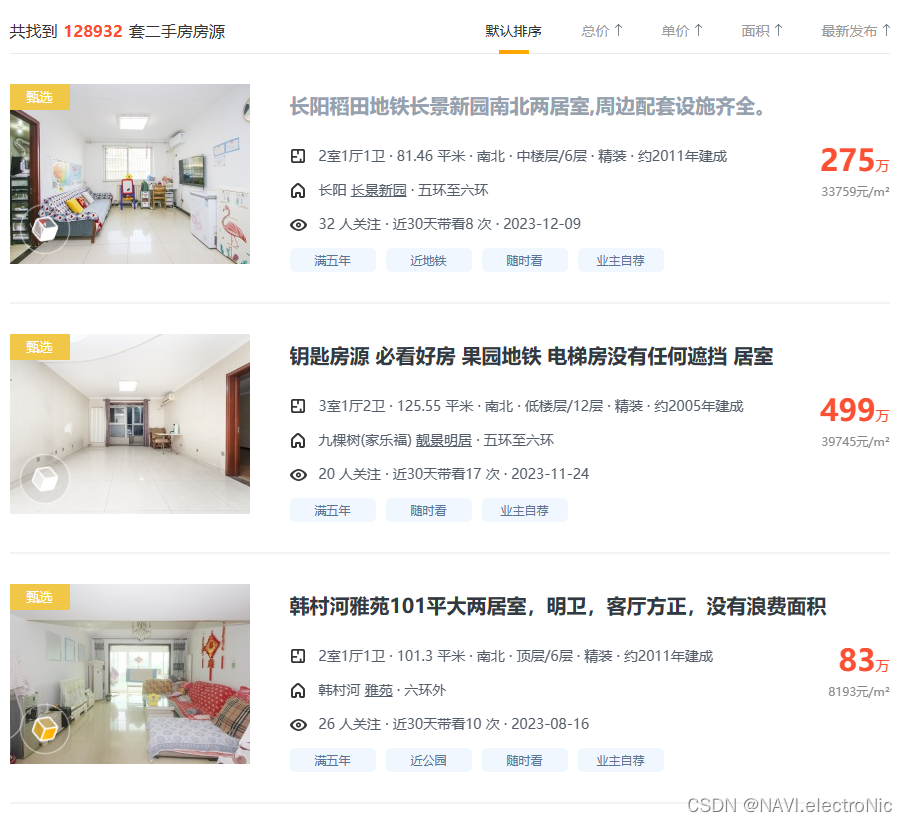
定位目标链接所在位置: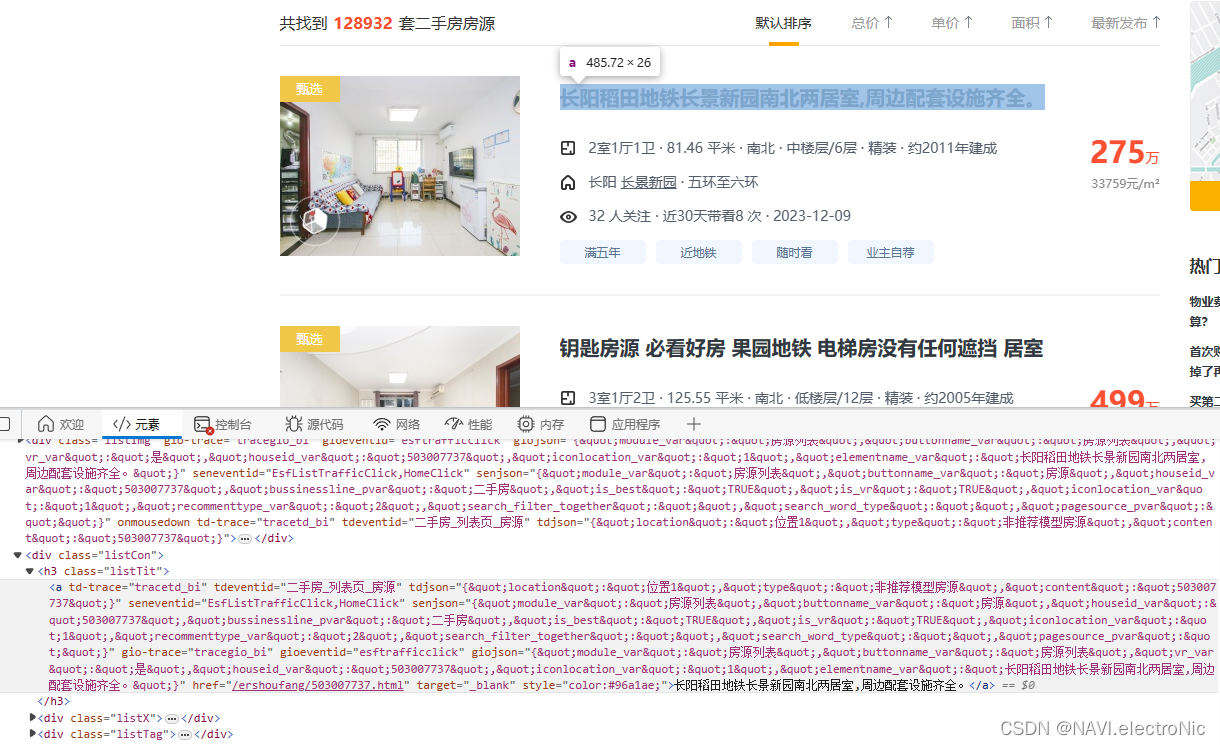
选择定位方式:
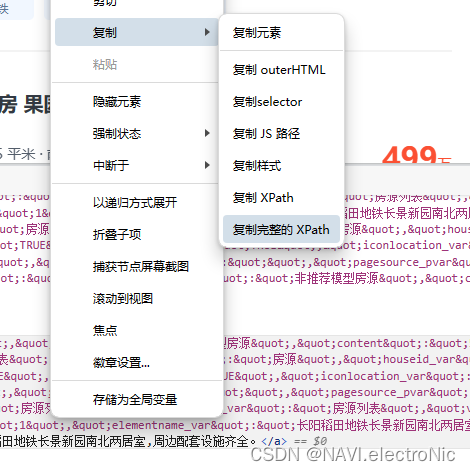
观察一下目标链接
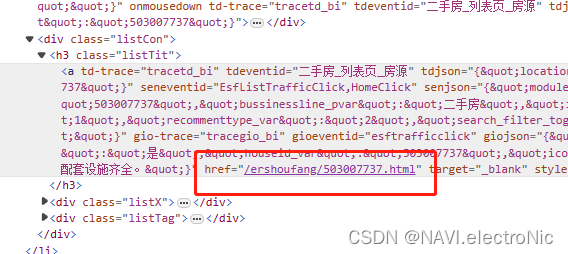
进入目标网站观察链接地址
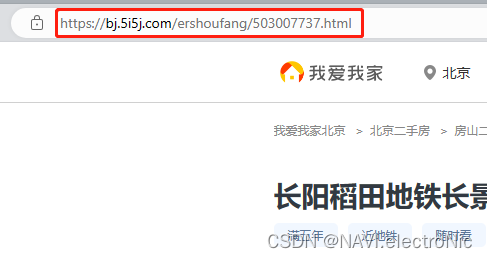
目标链接=“网站首页前缀”+“href中的内容”
即“https://bj.5i5j.com”+“/ershoufang/503007737.html”
得到规则后,可以开始编写代码。
可选择selector或者xpath进行定位
这里选择的是selector定位,
def parse(self, response):
base_url = 'https://bj.5i5j.com' # 基础URL
# 定位具有特定类名的元素并提取链接
for element in response.css('.listTit'):
relative_link = element.css('a::attr(href)').get()
if relative_link:
# 构建完整的链接
full_link = base_url + relative_link
yield scrapy.Request(full_link, callback=self.parse_house)
# 获取下一页链接
next_page = response.css('a.cPage::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)将两个链接进行拼接,得到最终链接。
三、观察目标链接内要爬取的信息
价格:
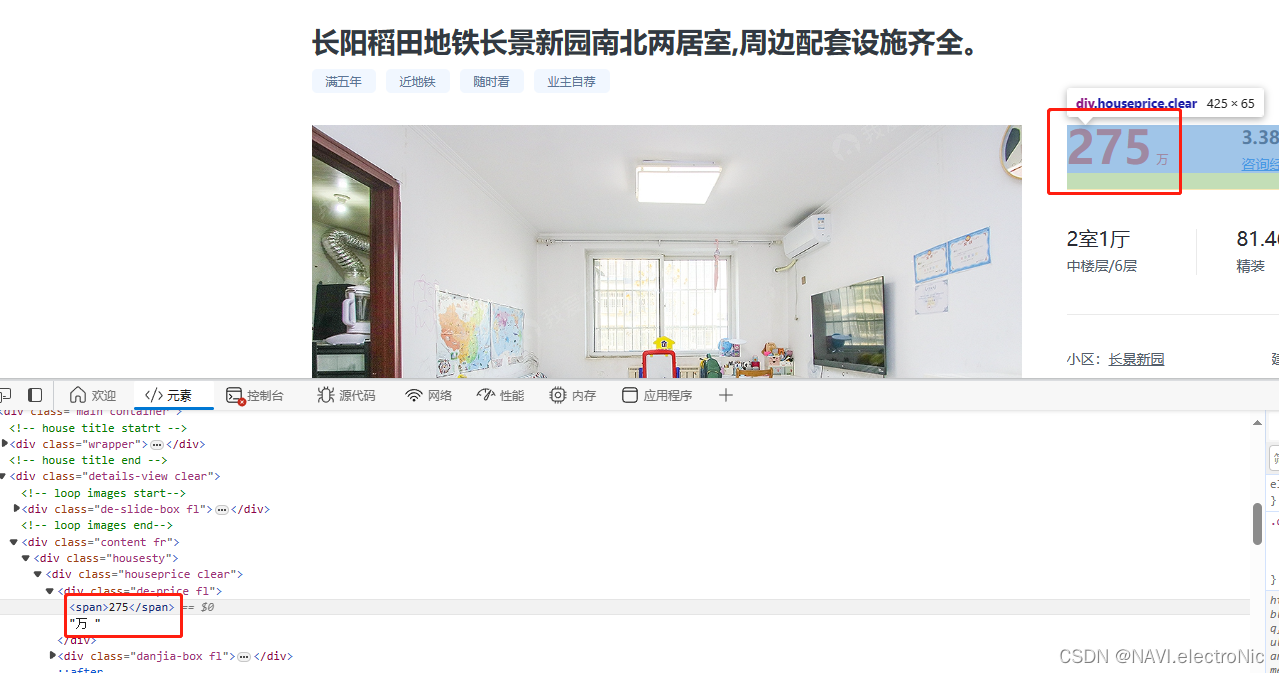
这里使用xpath定位

经纪人姓名,以及房源信息和名称均使用xpath进行定位,方法同上,如有其他需要爬取的信息,采取的方法类似,不再赘述。
具体实现代码:
def parse_house(self, response):
house_name = response.xpath('/html/body/div[6]/div[1]/div[1]/h1/text()').get()
price = response.xpath('/html/body/div[6]/div[2]/div[2]/div[1]/div[1]/div[1]/span/text()').get()
agent_name = response.xpath('/html/body/div[6]/div[2]/div[2]/div[3]/ul/li[2]/h3/a/text()').get()
house_link = response.url # 获取当前页面的链接
# 提取基础属性信息和交易属性信息...
# 提取基础属性信息
basic_attributes = {
'房屋户型': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房屋户型"]/span/text()').get(),
'所在楼层': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="所在楼层"]/span/text()').get(),
'建筑面积': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑面积"]/span/text()').get(),
'户型结构': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="户型结构"]/span/text()').get(),
'套内面积': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="套内面积"]/span/text()').get(),
'建筑类型': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑类型"]/span/text()').get(),
'房屋朝向': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房屋朝向"]/span/text()').get(),
'建筑结构': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑结构"]/span/text()').get(),
'装修情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="装修情况"]/span/text()').get(),
'供暖方式': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="供暖方式"]/span/text()').get(),
'配备电梯': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="配备电梯"]/span/text()').get()
}
# 提取交易属性信息
transaction_attributes = {
'发布时间': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="发布时间"]/span/text()').get(),
'建成年代': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建成年代"]/span[1]/text()').get(),
'产权性质': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="产权性质"]/span/text()').get(),
'规划用途': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="规划用途"]/span/text()').get(),
'上次交易': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="上次交易"]/span/text()').get(),
'购房年限': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="购房年限"]/span/text()').get(),
'共有情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="共有情况"]/span/text()').get(),
'抵押情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="抵押情况"]/span/text()').get(),
'房本备件': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房本备件"]/span/text()').get()
}
四、将信息存入json文件以及mongodb数据库
mongodb配置信息
# 添加MongoDB配置
mongo_uri = 'mongodb://localhost:27017/' # MongoDB URI
mongo_db = 'pachong' # MongoDB数据库名称
mongo_collection = 'pachong' # MongoDB集合名称写入json与数据库
# 将数据存储到json文件
yield {
'房屋名称': house_name.strip() if house_name else None,
'价格': price.strip() if price else None,
'经纪人姓名': agent_name.strip() if agent_name else None,
'房屋链接': house_link, # 将房屋链接包含在输出中
'基础属性信息': basic_attributes,
'交易属性信息': transaction_attributes
}
# 将数据存储到MongoDB
data_to_insert = {
'房屋名称': house_name.strip() if house_name else None,
'价格': price.strip() if price else None,
'经纪人姓名': agent_name.strip() if agent_name else None,
'房屋链接': house_link, # 保留房屋链接在输出中
'基础属性信息': basic_attributes,
'交易属性信息': transaction_attributes
# 根据需要添加其他字段
}
# 插入数据到MongoDB集合中
self.collection.insert_one(data_to_insert)
yield data_to_insert
五、请求头配置
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
'Referer': 'https://bj.5i5j.com/'
},
'FEEDS': {
'items.json': {
'format': 'json',
'overwrite': True,
'indent': 4,
'fields': None,
'include_links': True,
}
}
}六、pipelines配置文件,settings配置文件
pipelines.py
import pymongo
from scrapy.exceptions import DropItem
class MongoDBPipeline:
collection_name = 'pachong' # 更新为您的MongoDB集合名称
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 转换价格字段为实际的数字
if '价格' in item:
price = item['价格']
try:
# 判断价格是否包含"万"单位
if '万' in price:
# 去除价格中的"万"并转换为实际数字
price_value = float(price.replace('万', ''))
# 将价格乘以一万,得到实际的价格
item['价格'] = int(price_value * 10000)
else:
# 如果价格没有单位"万",将其转换为整数
item['价格'] = int(float(price))
except ValueError:
raise DropItem("Invalid price format in %s" % item)
if item.get('价格') is None:
raise DropItem("Missing price in %s" % item)
# 插入数据到 MongoDB
self.db[self.collection_name].insert_one(dict(item))
return item
settings.py
BOT_NAME = "pachong2"
SPIDER_MODULES = ["pachong2.spiders"]
NEWSPIDER_MODULE = "pachong2.spiders"
ROBOTSTXT_OBEY = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
MONGO_URI = 'mongodb://localhost:27017/' # 更新为您的MongoDB URI
MONGO_DATABASE = 'pachong' # 更新为您的MongoDB数据库名称
七、主体文件完整代码
具体代码实现
以下是完整代码,让我们看一下示例代码,它展示了如何创建一个 Scrapy Spider 来爬取 5i5j 网站上的房产数据,并将数据存储到 MongoDB 中。
import scrapy
import pymongo
class Fivei5jSpider(scrapy.Spider):
name = 'woaiwojia'
allowed_domains = ['bj.5i5j.com']
start_urls = ['https://bj.5i5j.com/ershoufang/']
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
'Referer': 'https://bj.5i5j.com/'
},
'FEEDS': {
'items.json': {
'format': 'json',
'overwrite': True,
'indent': 4,
'fields': None,
'include_links': True,
}
}
}
# 添加MongoDB配置
mongo_uri = 'mongodb://localhost:27017/' # MongoDB URI
mongo_db = 'pachong' # MongoDB数据库名称
mongo_collection = 'pachong' # MongoDB集合名称
def __init__(self, *args, **kwargs):
super(Fivei5jSpider, self).__init__(*args, **kwargs)
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.collection = self.db[self.mongo_collection]
def close(self, reason):
self.client.close()
super(Fivei5jSpider, self).close(self, reason)
def parse(self, response):
base_url = 'https://bj.5i5j.com' # 基础URL
# 定位具有特定类名的元素并提取链接
for element in response.css('.listTit'):
relative_link = element.css('a::attr(href)').get()
if relative_link:
# 构建完整的链接
full_link = base_url + relative_link
yield scrapy.Request(full_link, callback=self.parse_house)
# 获取下一页链接
next_page = response.css('a.cPage::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
def parse_house(self, response):
house_name = response.xpath('/html/body/div[6]/div[1]/div[1]/h1/text()').get()
price = response.xpath('/html/body/div[6]/div[2]/div[2]/div[1]/div[1]/div[1]/span/text()').get()
agent_name = response.xpath('/html/body/div[6]/div[2]/div[2]/div[3]/ul/li[2]/h3/a/text()').get()
house_link = response.url # 获取当前页面的链接
# 提取基础属性信息和交易属性信息...
# 提取基础属性信息
basic_attributes = {
'房屋户型': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房屋户型"]/span/text()').get(),
'所在楼层': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="所在楼层"]/span/text()').get(),
'建筑面积': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑面积"]/span/text()').get(),
'户型结构': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="户型结构"]/span/text()').get(),
'套内面积': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="套内面积"]/span/text()').get(),
'建筑类型': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑类型"]/span/text()').get(),
'房屋朝向': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房屋朝向"]/span/text()').get(),
'建筑结构': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建筑结构"]/span/text()').get(),
'装修情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="装修情况"]/span/text()').get(),
'供暖方式': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="供暖方式"]/span/text()').get(),
'配备电梯': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="配备电梯"]/span/text()').get()
}
# 提取交易属性信息
transaction_attributes = {
'发布时间': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="发布时间"]/span/text()').get(),
'建成年代': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="建成年代"]/span[1]/text()').get(),
'产权性质': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="产权性质"]/span/text()').get(),
'规划用途': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="规划用途"]/span/text()').get(),
'上次交易': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="上次交易"]/span/text()').get(),
'购房年限': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="购房年限"]/span/text()').get(),
'共有情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="共有情况"]/span/text()').get(),
'抵押情况': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="抵押情况"]/span/text()').get(),
'房本备件': response.xpath(
'/html/body/div[6]/div[3]/div[3]//ul/li[label/text()="房本备件"]/span/text()').get()
}
yield {
'房屋名称': house_name.strip() if house_name else None,
'价格': price.strip() if price else None,
'经纪人姓名': agent_name.strip() if agent_name else None,
'房屋链接': house_link, # 将房屋链接包含在输出中
'基础属性信息': basic_attributes,
'交易属性信息': transaction_attributes
}
# 将数据存储到MongoDB
data_to_insert = {
'房屋名称': house_name.strip() if house_name else None,
'价格': price.strip() if price else None,
'经纪人姓名': agent_name.strip() if agent_name else None,
'房屋链接': house_link, # 保留房屋链接在输出中
'基础属性信息': basic_attributes,
'交易属性信息': transaction_attributes
# 根据需要添加其他字段
}
# 插入数据到MongoDB集合中
self.collection.insert_one(data_to_insert)
yield data_to_insert
# 运行Spider
# scrapy crawl woaiwojia -o output.json # 您也可以将爬取的数据输出到文件中
八、运行 Spider
要运行这个 Spider 并获取房产数据,您可以在命令行中执行以下命令:
scrapy crawl woaiwojia -o output.json
请将 woaiwojia 替换为您所创建的 Spider 的名称,output.json 是存储数据的输出文件名。
请确保mongodb数据库中已创建好数据表
运行成功后会生成一个json文件,里面包含了爬取到的信息
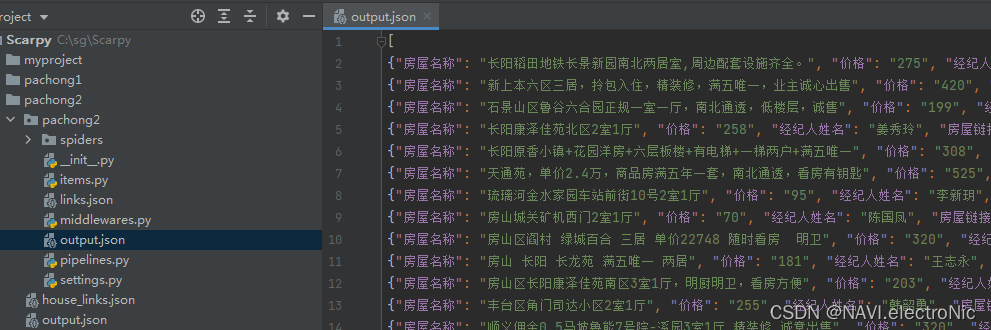
同时会将数据存入mongodb数据库,可以打开mongodb数据库查看,如果安装的是图形化界面,那么不再需要输入额外的命令,直接打开在表下就可以查看到,如果不是图形化界面,则需要使用命令进行查看,mongodb的安装本文不再做说明。
九、在数据库中查看
在mongodb安装文件目录下运行mongo
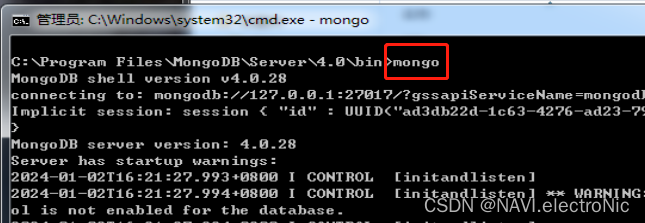
使用show dbs 命令查看已创建的数据库
show dbs使用use exam命令切换到目标数据库,这里以“exam”数据库为例
use exam使用db.exam.find()命令展示数据库中的内容
db.exam.find()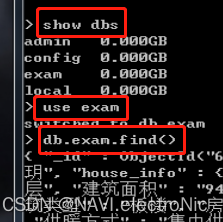
如果你的数据库名称不叫exam,请更改成你的数据库名称。
如果是图形化界面,直接打开就可以看到内容,不再演示。
免责声明与版权声明
免责声明
本教程仅供教育和学习目的使用。作者力求提供准确和实用的信息,但不对信息的准确性、完整性和实时性作任何保证。读者在使用本教程中的任何信息、工具或代码时,须自行承担风险,并对其行为负全部责任。
作者对因使用本教程的信息、工具或代码所导致的任何直接或间接损失不承担责任。本教程中提供的代码示例仅供参考,读者应审慎检查代码并根据自身需求进行修改。
版权声明
本教程中的所有内容,包括但不限于文本、图像、代码示例,版权均归作者所有。未经作者许可,禁止未经授权转载、复制或修改本教程中的任何内容。
读者可将本教程用于个人学习和研究目的,但不得用于商业目的或未经授权的传播。任何未经许可的使用可能构成侵权行为,作者保留采取法律行动的权利。
附加信息
在任何情况下,本教程的信息均不构成任何形式的建议、担保或合同。作者保留随时更改或更新本教程内容的权利,无需提前通知。


















 2528
2528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









