







Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning
文章来自 The Technion - Israel Institute of Technology(以色利理工学院),提出了一种适用于大型离散动作空间任务的方法 — AE-DQN (Action-Elimination Deep Q-Network)。
Contribution:
1)提出了一种在大型离散动作空间任务中,能够消除非最优动作的框架。
2)由于在某一状态下,非最优动作会被算法消除,因此提升了算法的学习速度。
Code: https://github.com/TomZahavy/CB_AE_DQN
先来看拥有大型离散动作空间的系统都有哪些:
- 个人助理 Agent
- 旅行规划器
- 餐厅/酒店登记器
- 聊天机器人
- 基于文字游戏的 Agent (文中采用的环境)
它们都是拥有大型离散动作空间的系统,但又区别于连续连续动作空间系统。比如聊天机器人,在某个场景/状态下,选择什么样的语句就是一个动作。然而由于语言的多样性,可选择的语句很可能有几百上千个,所以在这个状态下,就有几百上千个动作可选,因此这属于一个大型离散动作空间任务。
对于大型离散动作空间任务,如果直接训练一个 RL Agent 去完成任务的话,估计会相当慢。目前的解决方法是:
- 将动作空间分解成为多个 binary subspaces.
- 将离散动作空间变成连续动作空间,然后用连续动作空间的算法(如DDPG)输出动作,然后取离这个连续动作值最近的离散动作来执行。
- 将状态中某些多余的离散动作消除。(文中采用的方法)
方法框架
这篇文章选用的环境是文字游戏(Zork),游戏界面如下图(a),其中环境给出的 Feedback 信息将被用作动作消除信号。
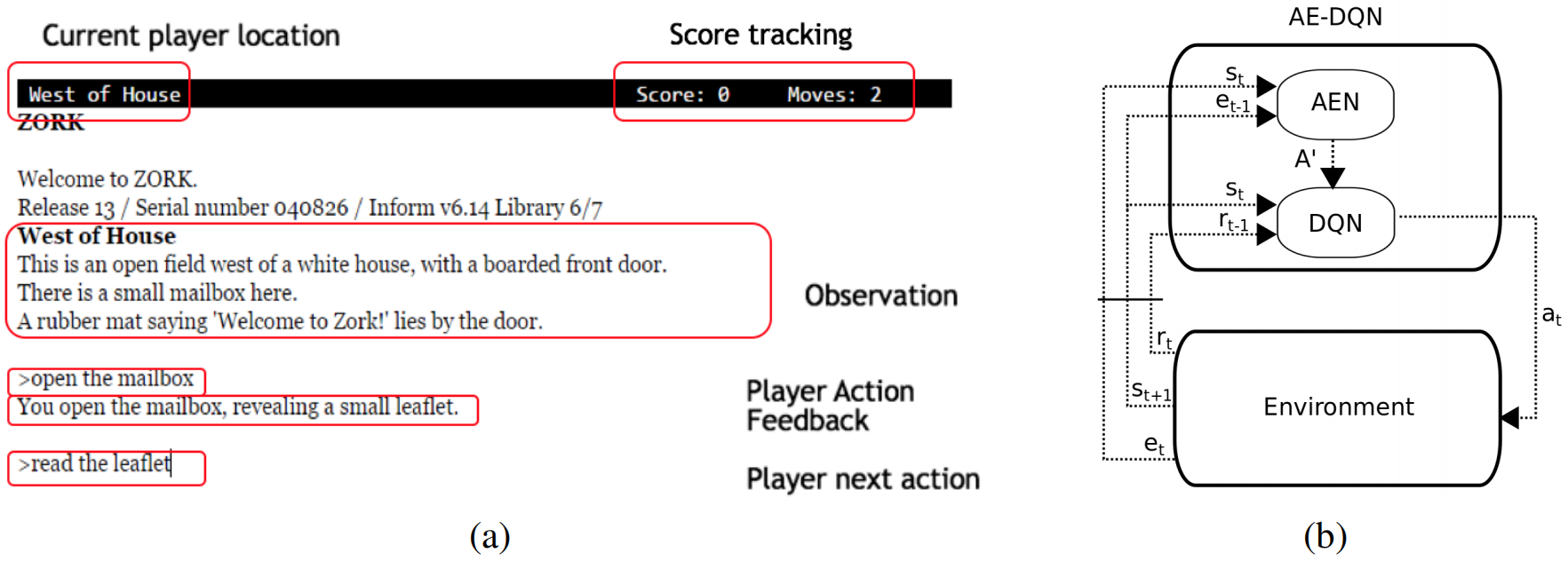
图(b)就是这篇文章提出的框架 AE-DQN,包含两个部分,DQN 网络和 AEN( Action Elimination Network) 网络。由于 Env 的状态和动作都是文字,因此这两个网络都采用了用于处理 NPL 任务的 CNN 结构。
其中,AEN 的作用就是在 DQN 训练动作值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a) 和采取动作之前,给 DQN 一个有效的动作集合
A
′
A'
A′,告诉 DQN 只能在这个集合中选择动作。AEN 相当于是动作过滤网。
那怎么知道在状态 s t s_t st 下,哪些动作应该被去除呢?事实上,只要满足下式的动作,就会被剔除:
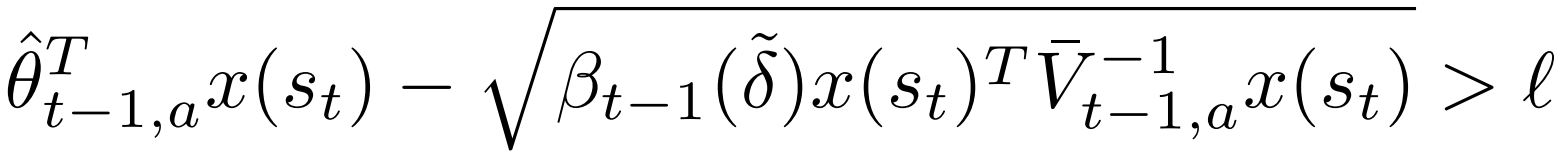
其中,
x
(
s
t
)
x(s_t)
x(st) 是
s
t
s_t
st 的特征表示;
l
≈
0.5
l \approx 0.5
l≈0.5;
δ
~
=
δ
/
k
\tilde \delta = \delta / k
δ~=δ/k;
θ
^
t
,
a
=
V
ˉ
t
,
a
−
1
X
t
,
a
T
E
t
,
a
\hat \theta_{t,a} = \bar V_{t,a}^{-1} X_{t,a}^T E_{t,a}
θ^t,a=Vˉt,a−1Xt,aTEt,a;
X
t
,
a
X_{t,a}
Xt,a 是一个矩阵,它的每一行代表的是状态表示向量,并且在这个状态下采取动作
a
a
a,一直到时间
t
t
t。例如,第
i
i
i 行表示的是采取动作
a
a
a 的第
i
i
i 个状态的状态表示。
E
t
,
a
E_{t,a}
Et,a 是一个向量,它的每一个元素代表的是动作消除信号,并且在这个信号下采取动作
a
a
a,一直到时间
t
t
t。
V
ˉ
t
,
a
=
λ
I
+
X
t
,
a
T
X
t
,
a
\bar V_{t,a} = \lambda I + X_{t,a}^TX_{t,a}
Vˉt,a=λI+Xt,aTXt,a;
λ
>
0
\lambda >0
λ>0;
β
t
(
δ
)
=
R
2
log
(
d
e
t
(
V
ˉ
t
,
a
)
1
/
2
d
e
t
(
λ
I
)
−
1
/
2
δ
)
+
λ
1
2
S
\sqrt {\beta_t(\delta)} = R \sqrt {2 \log( \frac {det(\bar V_{t,a})^{1/2} det(\lambda I)^{-1/2}} {\delta}) + \lambda^{\frac 12} S}
βt(δ)=R2log(δdet(Vˉt,a)1/2det(λI)−1/2)+λ21S.
这个式子的推导是比较复杂的,若有兴趣,可以参考该论文的补充材料。
最后来看下伪代码:
可以看到 function ACT 和 function TARGETS 使用上面的公式来获得可执行的动作集合和可更新Q值函数的动作集合,除此之外,这两个函数的其他功能与 DQN 的一样。
















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









