







 该博客介绍了NIPS2018深度学习会议的亮点,包括步长在神经网络训练中的关键影响、行动消除在强化学习中的应用,以及使用正则化GAN学习紧凑二值描述符的方法。文章探讨了步长如何决定局部最优解,AE-DQN如何加速训练并提高鲁棒性,以及BinGAN如何生成具有判别性的二值特征。
该博客介绍了NIPS2018深度学习会议的亮点,包括步长在神经网络训练中的关键影响、行动消除在强化学习中的应用,以及使用正则化GAN学习紧凑二值描述符的方法。文章探讨了步长如何决定局部最优解,AE-DQN如何加速训练并提高鲁棒性,以及BinGAN如何生成具有判别性的二值特征。
[1] Step Size Matters in Deep Learning
Kamil Nar, S. Shankar Sastry
University of California, Berkeley
https://papers.nips.cc/paper/7603-step-size-matters-in-deep-learning.pdf
利用梯度下降算法训练神经网络时,能够得到离散的非线性的动态系统。此时,在训练过程中网络会收敛到不定的点,而不是固定的点,而且还依赖于初始状态。
在这些现象中,步长起到非常重要的作用。步长决定了局部最优解的子集,如果算法收敛到一个轨道上,步幅决定了在该轨道震动的幅度。为解释步长对神经网络的影响,作者们将梯度下降算法当做离散的动态系统来研究,通过分析不同解的李雅普诺夫稳定性,给出了步长和相应的解之间的关系。
作者们发现,随深度的增加训练误差会恶化,对具有较大奇异值的线性映射进行估计比较困难,该文作者还发现深度残差网络具有显著不同的性能。
具有多个局部最优解的函数示例如下
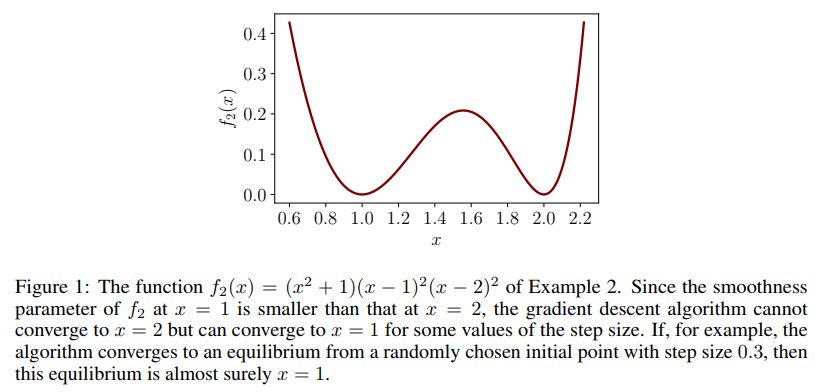
这篇文章的主要贡献如下

该文章跟先前工作的主要不同在于

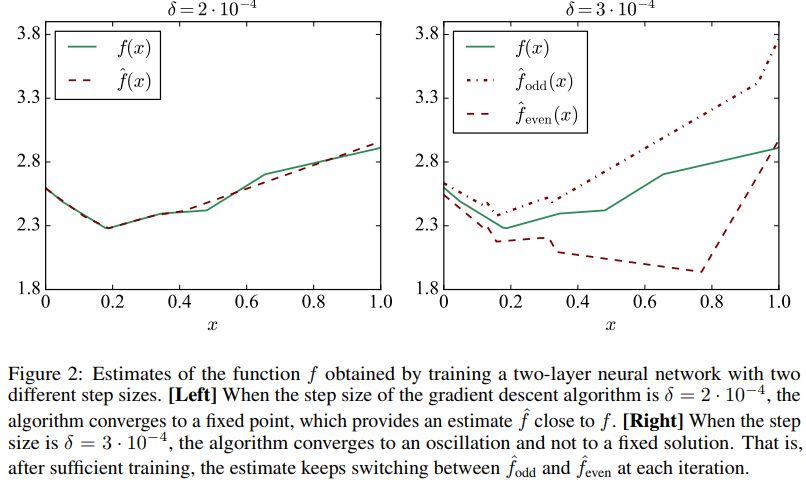
不同步幅的影响如下
代码地址
https://github.com/nar-k/NeurIPS-2018
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









