







Evolution-Guided Policy Gradients in Reinforcement Learning
文章来自Oregon State University,提出了一种结合 Evolution Algorithm(EA)的RL的算法 — Evolutionary Reinforcement Learning (ERL),该算法继承了前两者的优点。
RL的主要缺陷:
- temporal credit assignment problem;
- lack of effective exploration;
- brittle convergence properties.
EA的主要缺陷:
- high sample complexity;
- struggle to solve problems with a large number of parameters.
然而,RL的这三个缺陷在EA中是不存在的,反之,EA的缺陷在RL看来还有提升的空间。
Contribution:
1)提出了一种EA与RL(主要是off-policy算法)的结合算法 ---- ERL.
Code:
available at https://github.com/ShawK91/erl_paper_nips18
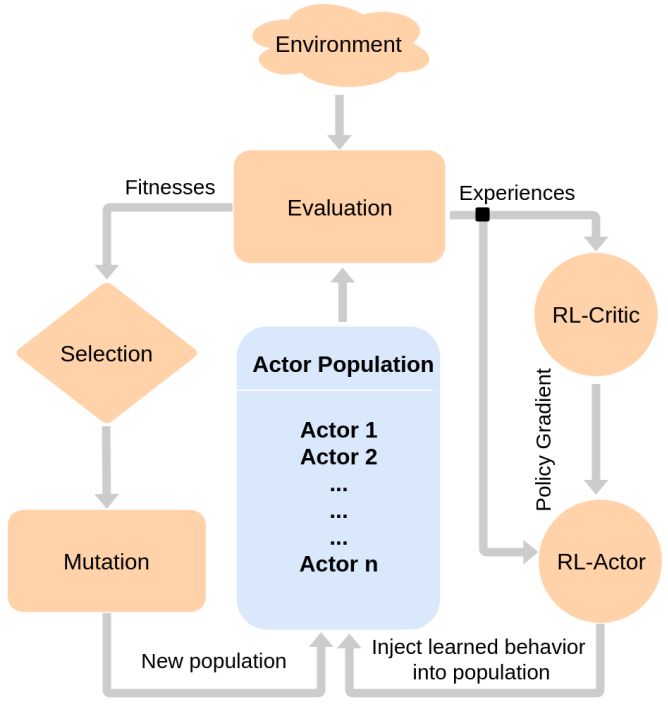
本文的做法是(如下图所示):用进化算法EA的一群执行者 a c t o r p o p actor_{pop} actorpop 去搜集agent与环境的互动轨迹(这期间 a c t o r p o p actor_{pop} actorpop 的参数是靠EA自身算法迭代进化的),然后RL使用这些轨迹进行梯度计算并更新策略。每隔一定次数的迭代,RL向EA传递梯度信息,即将最新的 a c t o r r l actor_{rl} actorrl 参数复制给EA的 a c t o r p o p actor_{pop} actorpop。其实主要是两股信息流的传递,EA到RL传递互动轨迹,RL到EA传递梯度信息( 以 a c t o r r l actor_{rl} actorrl 参数的形式 )。
以下是算法伪代码:这里本人有个疑问,即 Algorithm 1, line12什么时候会成立?符号 ∣ S ∣ |S| ∣S∣应该表示的是 S S S集合的元素个数,而从line11来看,好像表达的是 ∣ S ∣ = ( k − e ) |S|=(k-e) ∣S∣=(k−e),那么什么时候会出现 ∣ S ∣ < ( k − e ) |S|<(k-e) ∣S∣<(k−e)?


















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









