







 本文介绍了模型融合的重要性,特别是集成学习中的Voting/Averaging、Boosting、Bagging和Stacking方法。Voting/Averaging通过投票或平均提高分类或回归的准确性;Boosting通过弱分类器的串联降低误差,如Adaboost、GBDT、XGBOOST;Bagging通过随机抽样减少过拟合,如随机森林;Stacking利用多层模型预测结果作为新特征,进一步提升模型性能。Blending作为Stacking的变种,使用HoldOut集而非交叉验证。
本文介绍了模型融合的重要性,特别是集成学习中的Voting/Averaging、Boosting、Bagging和Stacking方法。Voting/Averaging通过投票或平均提高分类或回归的准确性;Boosting通过弱分类器的串联降低误差,如Adaboost、GBDT、XGBOOST;Bagging通过随机抽样减少过拟合,如随机森林;Stacking利用多层模型预测结果作为新特征,进一步提升模型性能。Blending作为Stacking的变种,使用HoldOut集而非交叉验证。
一般来说,通过融合多个不同的模型,可能提升机器学习的性能,这一方法在各种机器学习比赛中广泛应用,比如在kaggle上的otto产品分类挑战赛①中取得冠军和亚军成绩的模型都是融合了1000+模型的“庞然大物”。
常见的集成学习&模型融合方法包括:简单的Voting/Averaging(分别对于分类和回归问题)、Stacking、Boosting和Bagging。
-->Voting/Averaging
在不改变模型的情况下,直接对各个不同的模型预测的结果,进行投票或者平均,这是一种简单却行之有效的融合方式。
比如对于分类问题,假设有三个相互独立的模型,每个正确率都是70%,采用少数服从多数的方式进行投票。那么最终的正确率将是:
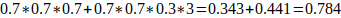
即结果经过简单的投票,使得正确率提升了8%。这是一个简单的概率学问题——如果进行投票的模型越多,那么显然其结果将会更好。但是其前提条件是模型之间相互独立,结果之间没有相关性。越相近的模型进行融合,融合效果也会越差。
模型之间差异越大,融合所得的结果将会更好。//这种特性不会受融合方式的影响。注意这里所指模型之间的差异,并不是指正确率的差异,而是指模型之间相关性的差异。
对于回归问题,对各种模型的预测结果进行平均,所得到的结果通过能够减少过拟合,并使得边界更加平滑,单个模型的边界可能很粗糙。这是很直观的性质,随便放张图②就不另外详细举例了。
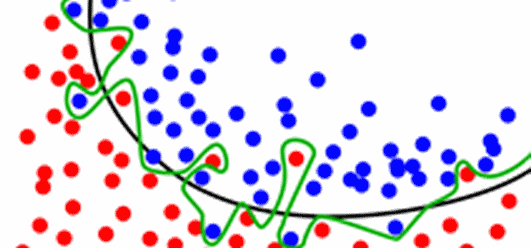
在上述融合方法的基础上,一个进行改良的方式是对各个投票者/平均者分配不同的权重以改变其对最终结果影响的大小。对于正确率低的模型给予更低的权重,而正确率更高的模型给予更高的权重。这也是可以直观理解的——想要推翻专家模型(高正确率模型)的唯一方式,就是臭皮匠模型(低正确率模型)同时投出相同选项的反对票。具体的对于权重的赋值,可以用正确率排名的正则化等。
这种方法看似简单,但是却是下面各种“高级”方法的基础。
-->Boosting
Boosting是一种将各种弱分类器串联起来的集成学习方式,每一个分类器的训练都依赖于前一个分类器的结果,顺序运行的方式导致了运行速度慢。和所有融合方式一样,它不会考虑各个弱分类器模型本身结构为何,而是对训练数据(样本集)和连接方式进行操纵以获得更小的误差。但是为了将最终的强分类器的误差均衡,之前所选取的分类器一般都是相对比较弱的分类器,因为一旦某个分类器较强将使得后续结果受
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









