







Redis主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主,这样就可以减轻服务器的压力了。
redis主从复制之配置介绍
复制的原理介绍
slave启动成功连接到master后会发送一个sync命令,Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
case 1:一主N从
(在这里我只使用了一台Linux机器,但是通过配置同样可以达到Redis集群的需求,如果有多个服务器,配置是一样的)
首先从拷贝3个redis.conf文件(拷贝两个也是可以的,这里我是为了区分Master/Slave)

那么接下来就是修改配置了
1.主机配置介绍(为了说明在主从复制的时候访问的不是同一个数据库文件,将数据库文件名也相应的修改)
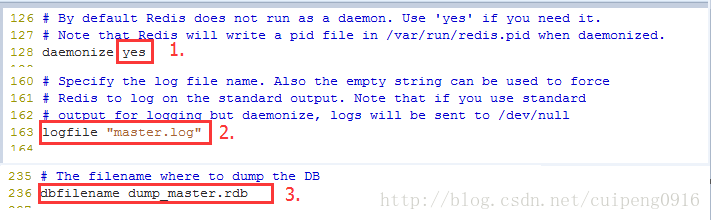
2.从机配置介绍
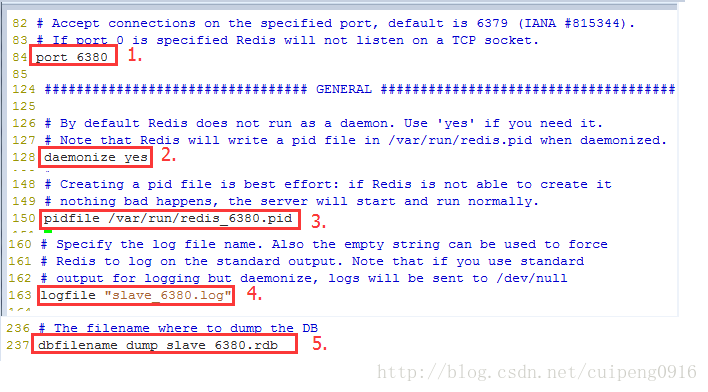
OK配置完成了,那么接下来就是启动redis服务并连接,查看配置是否有效
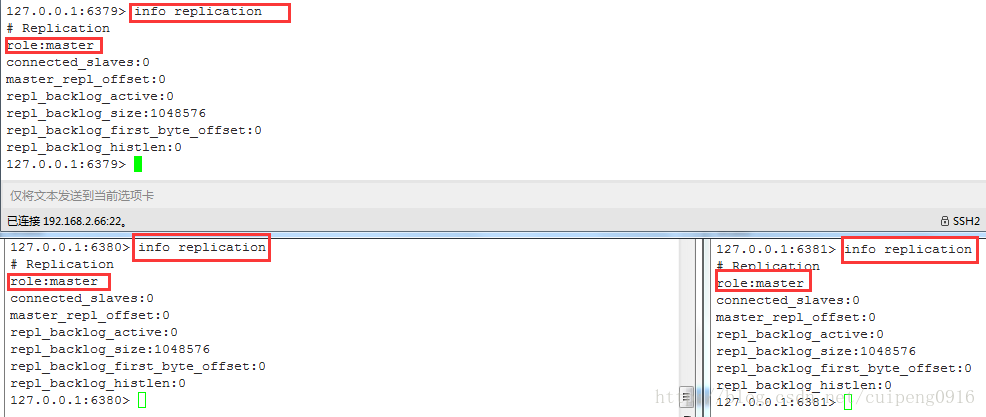
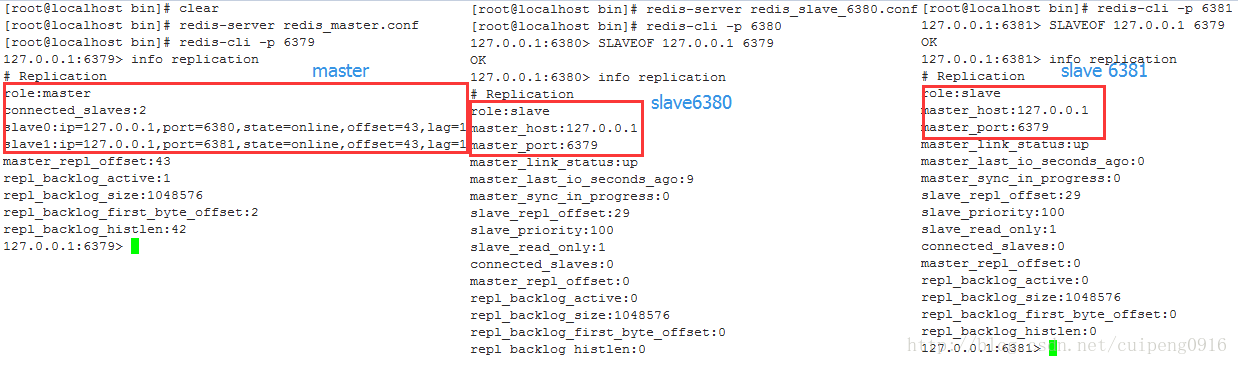
我们可以看到,3台服务器的redis服务成功启动,角色都是master,那么接下来就是要区分主从库了,通过命令slaveof 主机IP 主机redis端口
slaveof 127.0.0.1 6379
那么这个时候在主库中执行写的操作
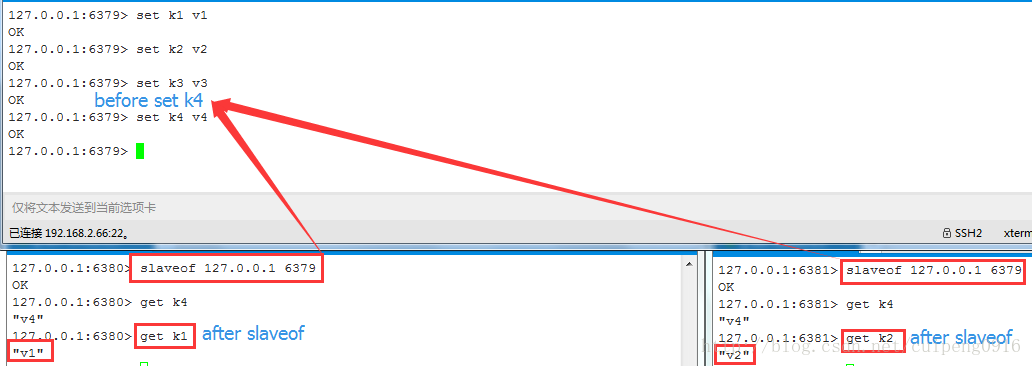
在set k4之前做了set k1,k2,k3操作,然后6380,6381作为从库连接主库,发现主库中所有的数据在从库中都有,而且每个从库都有数据库文件
那么在这个时候我们在从库执行write操作的时候,发现是无法正确执行的
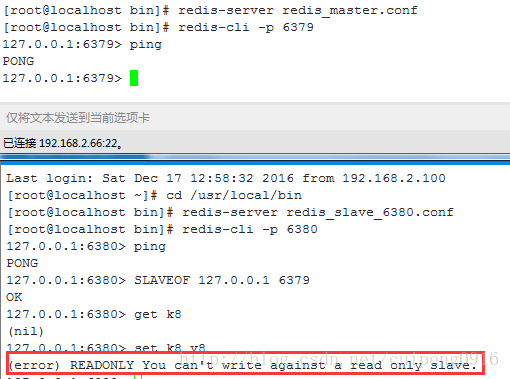
因为有了从库之后,读写就已经分离了,所以在从库中只能执行读的操作
上面呢我是通过命令的方式实现主从库的分离的,那么大家就会发现,这样子是很麻烦的,万一从库redis服务挂了之后,再次启动redis服务之后还要执行
slaveof 127.0.0.1 6369这样子是很不人性化的,而且也是非常的麻烦,那么接下来就通过配置文件的方式实现主从库的分离
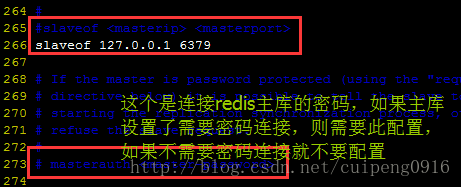
其他的从库也是这样配置,OK,配置已经好了,那么接下来就是启动redis服务了
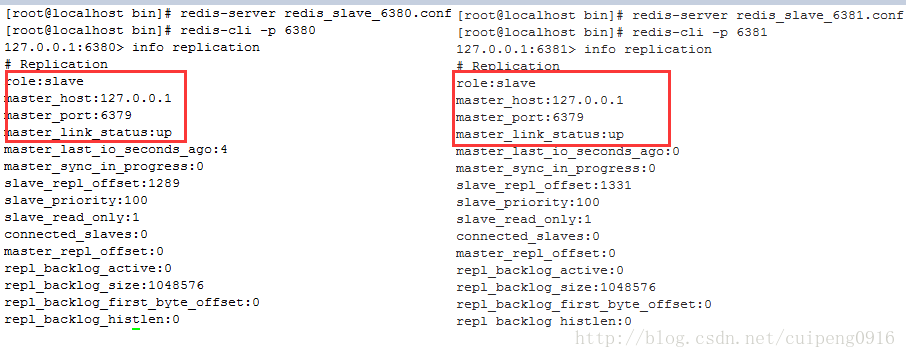
我们可以看到,当redis服务启动之后,角色立马变成从库了,而不要向我们之前的需要手动敲命令,这样也是挺方便的
上面的case 1呢讲到了一主N从得模式
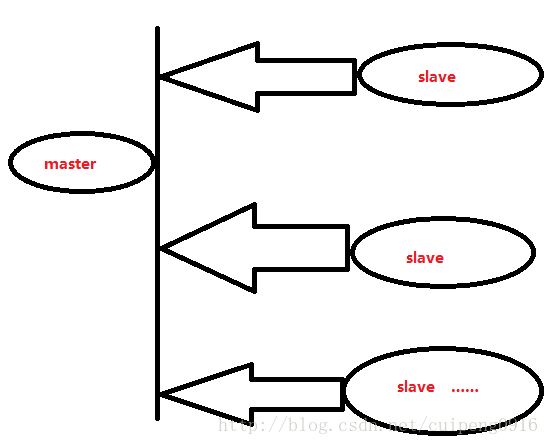
那么redis从库是否可以让其他的redis服务连接呢?
case 2:传宗接代
传宗接代的意思呢就是说一个主库下只有一个从库,而这个从库下又有其他的redis从库跟着。一个跟着一个,而不是一个主库下有跟着N个从库,这样子呢就可以去中心化,但是这样子呢会出现数据复制的延时,因为你是一个跟着一个,在主库中有数据的变化,那么下面的从库就会立即复制,但是这个时候只有一个从库,要等当前从库复制完成才可以再次向下复制

配置
将其中一台的配置修改

启动redis服务
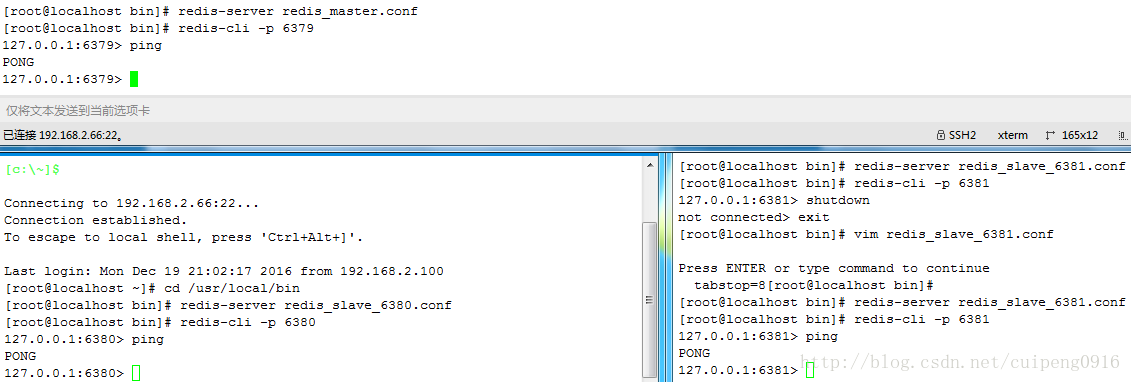
服务启动成功,那么中间那一台连着主库的那个redis(也就是直连主库然后下面又跟着从库的那台)是什么角色呢?
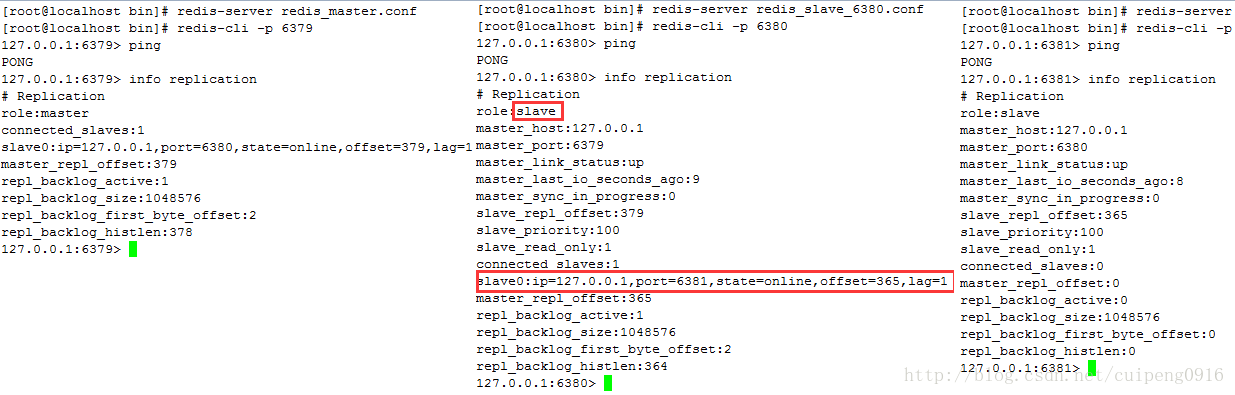
可以看到,中间的那个redis从库依然是从库的角色,但是下面又跟着小弟。但是呢这个时候还是无法执行write的操作,因为中间的那个依旧是从库的角色

ps:若主宕机了,从会一直等待(后面会用 哨兵解决这个问题)















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









