







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 高效生成:TangoFlux 能在3.7秒内生成30秒的高质量音频。
- 文本转换:支持将文本描述直接转换为音频输出。
- 偏好优化:通过CRPO框架优化音频输出,使其更符合用户偏好。
正文(附运行示例)
TangoFlux 是什么
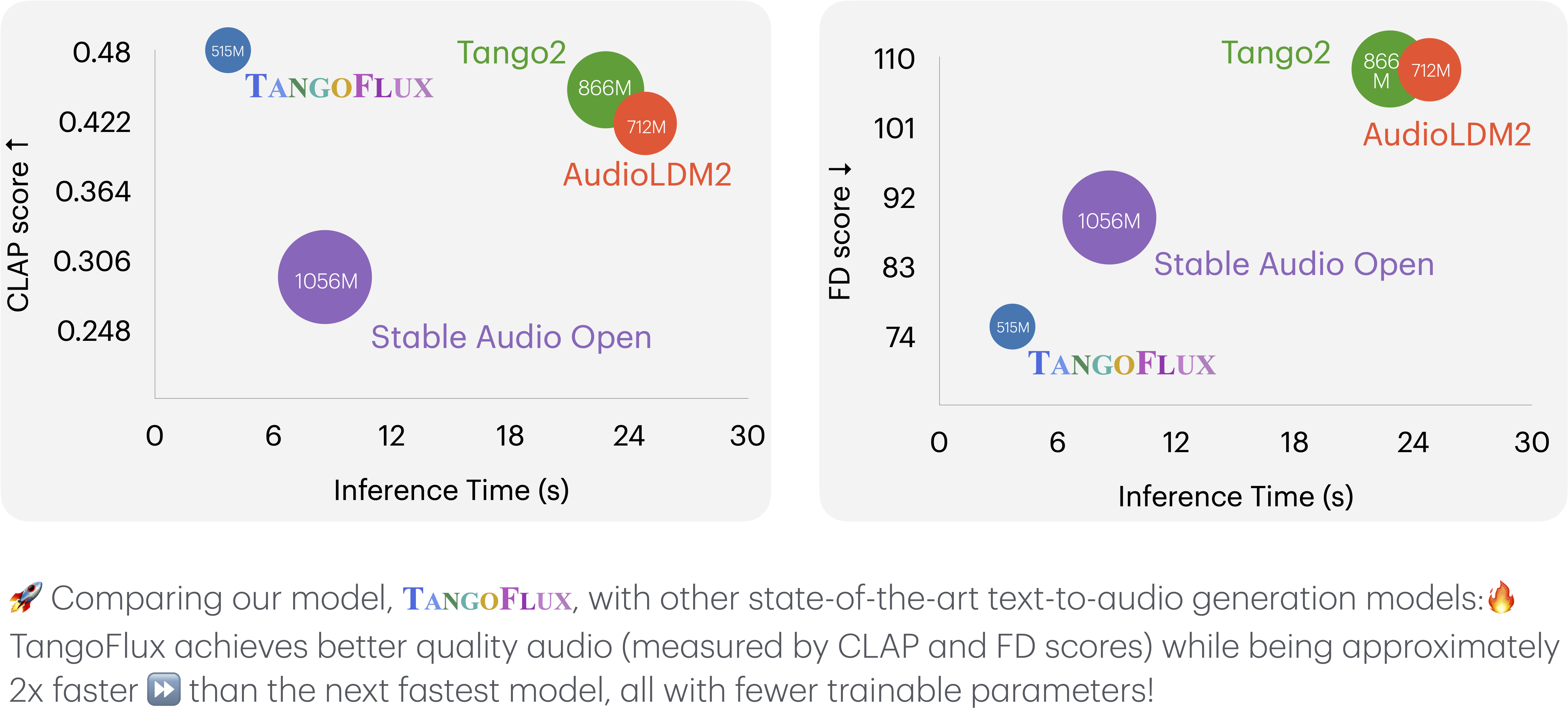
TangoFlux 是由新加坡科技设计大学(SUTD)和英伟达(NVIDIA)联合开发的高效文本到音频生成模型。该模型拥有约5.15亿参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。
TangoFlux 采用了CLAP-Ranked Preference Optimization(CRPO)框架,通过迭代生成和优化偏好数据来提升模型的音频对齐能力。在客观和主观基准测试中,TangoFlux 均展现出优异的性能,并在GitHub等平台开源了代码和模型,支持进一步的研究和开发。
TangoFlux 的主要功能
- 高效音频生成:TangoFlux 能快速生成高质量的音频内容,在3.7秒内生成长达30秒的44.1kHz音频。
- 文本到音频转换:模型直接将文本描述转换为相应的音频输出,实现文本到音频的直接转换。
- 偏好优化:TangoFlux 能优化音频输出,使其更好地符合用户的偏好和输入文本的意图。
- 非专有数据训练:基于非专有数据集进行训练,让模型更加开放和可访问。
TangoFlux 的技术原理
- 变分自编码器:用VAE将音频波形编码成潜在的表示,从潜在表示中重构原始音频。
- 文本和时长嵌入:模型基于文本编码和时长编码来控制生成音频的内容和时长,实现对音频的可控生成。
- FluxTransformer架构:基于FluxTransformer块构建,结合Diffusion Transformer (DiT) 和 Multimodal Diffusion Transformer (MMDiT),处理文本提示和生成音频。
- 流匹配(Flow Matching, FM):基于流匹配框架,学习从简单先验分布到复杂目标分布的映射,生成样本。
- CLAP-Ranked Preference Optimization (CRPO):CRPO框架基于迭代生成偏好数据对,优化音频对齐。用CLAP模型作为代理奖励模型,基于文本和音频的联合嵌入来评估音频输出的质量,并据此构建偏好数据集,进行偏好优化。
- 直接偏好优化:TangoFlux 将DPO应用于流匹配,比较获胜和失败的音频样本来优化模型,提高音频与文本描述的对齐度。
如何运行 TangoFlux
import torchaudio
from tangoflux import TangoFluxInference
from IPython.display import Audio
model = TangoFluxInference(name='declare-lab/TangoFlux')
audio = model.generate('Hammer slowly hitting the wooden table', steps=50, duration=10)
Audio(data=audio, rate=44100)
资源
- 项目官网:https://tangoflux.github.io/
- GitHub 仓库:https://github.com/declare-lab/TangoFlux
- HuggingFace 模型库:https://huggingface.co/declare-lab/TangoFlux
- arXiv 技术论文:https://arxiv.org/pdf/2412.21037
- 在线体验 Demo:https://huggingface.co/spaces/declare-lab/TangoFlux
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









