






❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 功能:TITAN 能够生成病理报告,支持跨模态检索和罕见癌症检索。
- 技术:通过视觉自监督学习和视觉-语言对齐预训练,提取通用切片表示。
- 应用:适用于资源有限的临床场景,减少误诊和观察者间差异。
正文(附运行示例)
TITAN 是什么
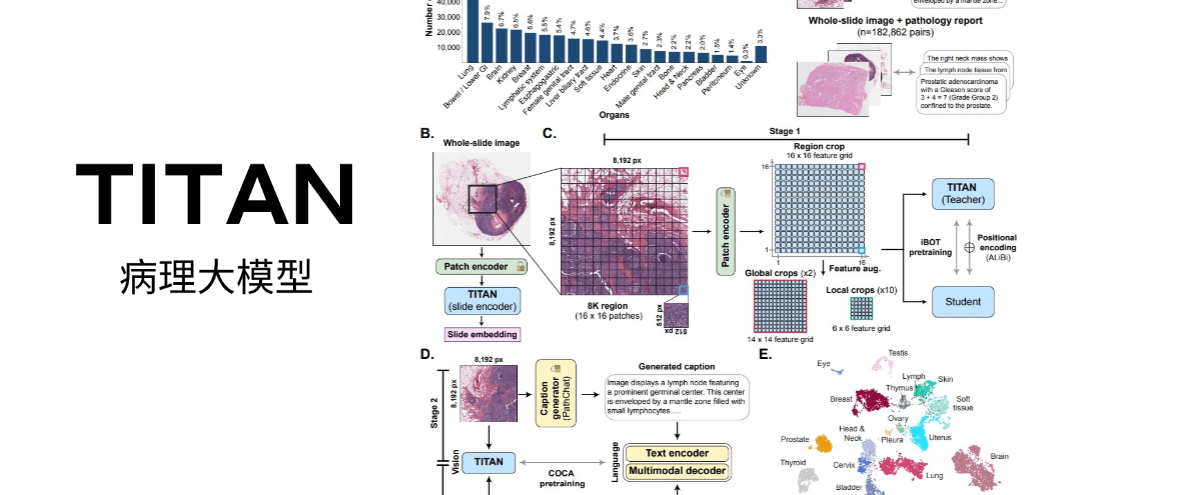
TITAN 是哈佛医学院研究团队开发的多模态全切片病理基础模型,通过视觉自监督学习和视觉-语言对齐预训练,能够在无需微调或临床标签的情况下提取通用的切片表示,生成病理报告。它使用了 335,645 张全切片图像(WSIs)以及相应的病理报告,结合了 423,122 个由多模态生成型 AI 协作者生成的合成字幕。
TITAN 在多种临床任务中表现出色,包括线性探测、少样本和零样本分类、罕见癌症检索、跨模态检索和病理报告生成。
TITAN 的主要功能
- 生成病理报告:TITAN 能够生成在资源有限的临床场景下,如罕见疾病检索和癌症预后,具有泛化能力的病理报告。
- 多任务性能:在多种临床任务上,如线性探测、少样本和零样本分类、罕见癌症检索和跨模态检索,以及病理报告生成等方面,TITAN 均展现出优越的性能。
- 提取通用切片表示:TITAN 能够提取适用于多种病理任务的通用切片表示,为病理学研究和临床诊断提供有力工具。
- 检索相似切片和报告:TITAN 在罕见癌症检索和交叉模态检索任务中表现出色,能有效检索相似切片和报告,辅助临床诊断决策。
- 减少误诊和观察者间差异:TITAN 在临床诊断工作流程中有重要潜力,可协助病理学家和肿瘤学家检索相似切片和报告,减少误诊和观察者间差异。
TITAN 的技术原理
- 自监督学习和视觉-语言对齐:TITAN 通过视觉自监督学习和视觉-语言对齐进行预训练,能无需任何微调或临床标签,提取通用目的的切片表示。
- 预训练策略:TITAN 的预训练包含三个不同的阶段,确保最终生成的切片层面表示能够借助视觉和语言监督信号,同时捕捉 ROI 层面以及 WSIs 层面的组织形态学语义。
- 模型设计:TITAN 基于视觉 Transformer(ViT)架构,切片编码器使用预先提取的图像块特征,按二维特征网格排列以保留空间上下文。通过将图像块尺寸增大,有效减少输入序列长度。在处理全切片图像尺寸和形状不规则问题上,采用区域裁剪和数据增强方法。
- 语言能力赋予:通过对比标题生成器(CoCa)在第二、三阶段的预训练,将切片表示分别与合成标题及病理报告对齐,微调切片编码器、文本编码器和多模态解码器,使模型具备语言能力,包括生成病理报告、零样本分类和跨模态检索等。
如何运行 TITAN
1. 获取访问权限
首先,从 Huggingface 模型页面请求访问模型权重(CONCHv1.5 和 TITAN-preview):https://huggingface.co/MahmoodLab/TITAN。
2. 下载权重并创建模型
通过 Huggingface Hub 进行身份验证后,可以自动下载 TITAN-preview 和 CONCH v1.5 的权重。
from huggingface_hub import login
from transformers import AutoModel
login() # 使用你的 User Access Token 登录
titan = AutoModel.from_pretrained('MahmoodLab/TITAN', trust_remote_code=True)
conch, eval_transform = titan.return_conch()
3. 运行推理
你可以直接使用 TITAN-preview 进行切片级别的特征提取。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 加载 TCGA 样本数据
from huggingface_hub import hf_hub_download
demo_h5_path = hf_hub_download(
"MahmoodLab/TITAN",
filename="TCGA_demo_features/TCGA-PC-A5DK-01Z-00-DX1.C2D3BC09-411F-46CF-811B-FDBA7C2A295B.h5",
)
file = h5py.File(demo_h5_path, 'r')
features = torch.from_numpy(file['features'][:])
coords = torch.from_numpy(file['coords'][:])
patch_size_lv0 = file['coords'].attrs['patch_size_level0']
# 提取切片嵌入
with torch.autocast('cuda', torch.float16), torch.inference_mode():
features = features.to(device)
coords = coords.to(device)
slide_embedding = model.encode_slide_from_patch_features(features, coords, patch_size_lv0)
资源
- 项目官网:https://mimictalk.github.io/
- GitHub 仓库:https://github.com/mahmoodlab/TITAN
- HuggingFace 模型库:https://huggingface.co/MahmoodLab/TITAN
- arXiv 技术论文:https://arxiv.org/pdf/2411.19666
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









