







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
大家好,我是蚝油菜花,今天跟大家分享一下 Lumina-Video 这个由上海 AI Lab 和香港中文大学联合推出的高效视频生成框架。
🚀 快速阅读
Lumina-Video 是一款基于 Next-DiT 架构的视频生成框架,针对视频生成中的时空复杂性进行优化。
- 核心功能:支持高质量视频生成、动态程度控制和多分辨率生成。
- 技术原理:采用多尺度 Next-DiT 架构和运动分数作为条件输入,结合渐进式训练和多源训练策略。
Lumina-Video 是什么
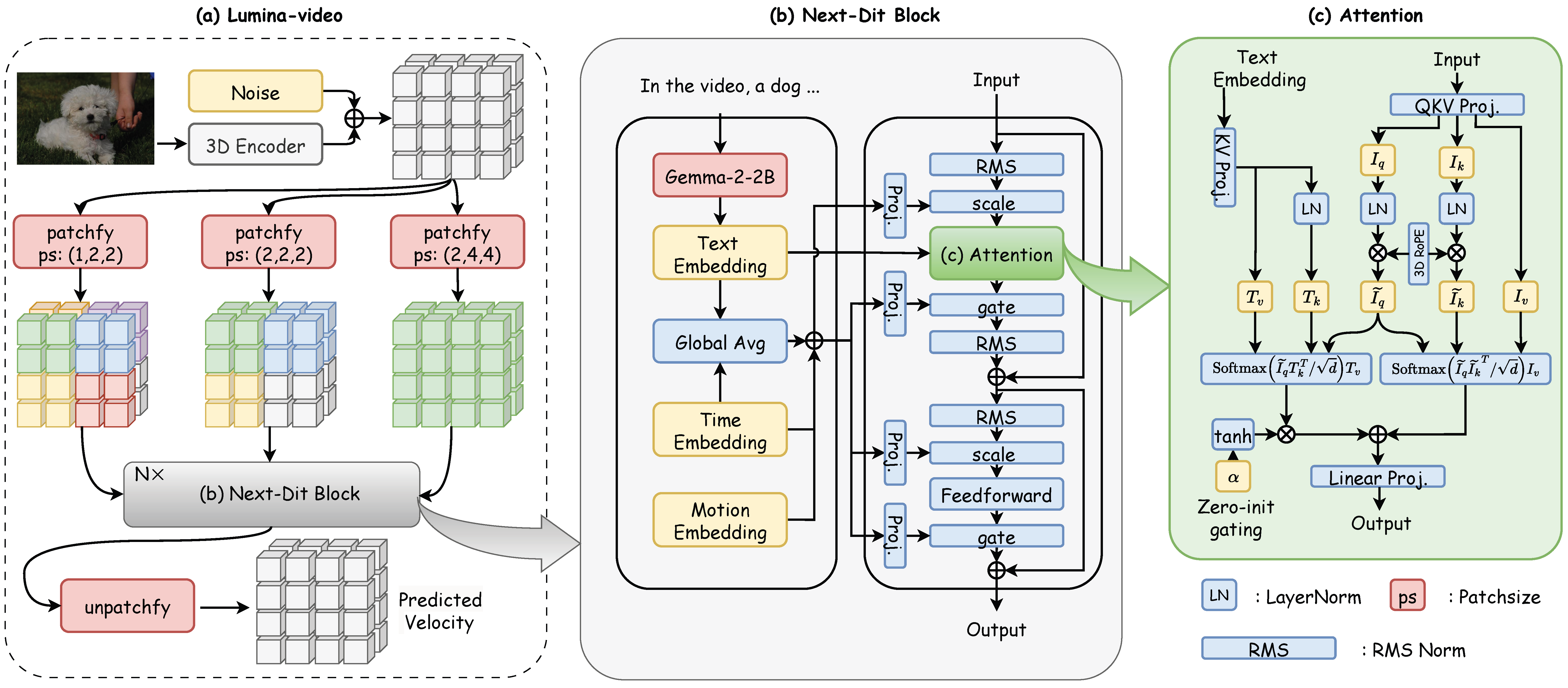
Lumina-Video 是由上海 AI Lab 和香港中文大学联合推出的一款视频生成框架。该框架基于 Next-DiT 架构,专门针对视频生成中的时空复杂性进行了优化。通过引入多尺度的 patchify 层,Lumina-Video 提升了生成效率和灵活性,并能够根据用户的需求灵活调整生成视频的动态程度。
Lumina-Video 还扩展了 Lumina-V2A 模型,为生成的视频添加同步声音,使视频更具现实感。这一创新使得 Lumina-Video 在内容创作、虚拟现实、教育和游戏开发等多个领域具有广泛的应用前景。
Lumina-Video 的主要功能
- 高质量视频生成:生成具有高分辨率、丰富细节和出色时空连贯性的视频内容。
- 动态程度控制:基于运动分数作为条件输入,用户可以灵活调整生成视频的动态程度,从静态到高度动态。
- 多尺度生成:支持不同分辨率和帧率的视频生成,适应多种应用场景。
- 视频到音频同步:基于 Lumina-V2A 模型,为生成的视频添加与视觉内容同步的声音,增强视频的现实感。
- 高效训练与推理:采用渐进式训练和多源训练策略,提高训练效率和模型性能,在推理阶段提供灵活的多阶段生成策略,平衡计算成本与生成质量。
Lumina-Video 的技术原理
- 多尺度 Next-DiT 架构:引入多个不同大小的 patchify 和 unpatchify 层,支持模型在不同计算预算下学习视频结构。通过动态调整 patch 大小,模型在推理阶段可以根据资源需求灵活调整计算成本,保持生成质量。
- 运动控制机制:基于计算光流的运动分数,将其作为条件输入到扩散模型中,直接控制生成视频的动态程度。调整正负样本的运动条件差异,实现对视频动态程度的精细控制。
- 渐进式训练:基于多阶段训练策略,逐步提高视频的分辨率和帧率,提高训练效率。结合图像-视频联合训练,利用高质量的图像数据提升模型对视觉概念的理解和帧级质量。
- 多源训练:使用自然和合成数据源进行训练,充分利用多样化数据,提升模型的泛化能力和生成质量。
- 视频到音频同步(Lumina-V2A):基于 Next-DiT 和流匹配技术,将视频和文本特征与音频潜表示融合,生成与视觉内容同步的声音。使用预训练的音频 VAE 和 HiFi-GAN vocoder 进行音频编码和解码,确保生成音频的质量和同步性。
如何运行 Lumina-Video
1. 安装依赖
请参考 INSTALL.md 获取详细的安装说明。
2. 下载模型检查点
在运行推理之前,需要先下载模型检查点。你可以使用以下命令将检查点下载到 ./ckpts 目录:
huggingface-cli download --resume-download Alpha-VLLM/Lumina-Video-f24R960 --local-dir ./ckpts/f24R960
3. 运行推理
你可以使用以下命令快速生成一段 4 秒的视频,分辨率为 1248x704,帧率为 24fps:
python -u generate.py \
--ckpt ./ckpts/f24R960 \
--resolution 1248x704 \
--fps 24 \
--frames 96 \
--prompt "your prompt here" \
--neg_prompt "" \
--sample_config f24F96R960 # set to "f24F96R960-MultiScale" for efficient multi-scale inference
4. 常见问题解答
Q1: 为什么使用 1248x704 分辨率?
A1: 该分辨率原本预期为 1280x720,但由于为了确保与最大 patch 大小(最小尺度)兼容,宽度和高度必须都能被 32 整除,因此调整为 1248x704。
Q2: 该模型是否支持灵活的宽高比?
A2: 是的,你可以使用以下代码查看所有可用的分辨率:
from imgproc import generate_crop_size_list
target_size = 960
patch_size = 32
max_num_patches = (target_size // patch_size) ** 2
crop_size_list = generate_crop_size_list(max_num_patches, patch_size)
print(crop_size_list)
资源
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









