






❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🚀 「你的多模态模型真的会思考吗?揭秘链式推理评测新标杆」
大家好,我是蚝油菜花。当所有AI厂商都在吹嘘模型参数时,你是否遇到过这些扎心问题——
- 🔍 测试模型时,总在「感知准确」和「逻辑合理」之间左右为难
- ⏳ 耗费大量时间标注数据,却得不到细粒度的推理过程分析
- 🧩 同一个模型,在OCR场景表现优异,遇到时空推理就漏洞百出…
今天带来的 MME-CoT 评测框架,正是破局的关键!这项由港中大、清华等顶级机构联合推出的技术,不仅涵盖数学/科学/OCR等6大领域,更通过独创的「三维评估体系」:
- ✅ 推理质量 - 像考官般审查每个逻辑步骤的合理性
- ✅ 鲁棒性 - 检测感知任务对推理的干扰程度
- ✅ 效率 - 揪出无效的「反思循环」和冗余推理
目前已暴露主流模型的致命缺陷:某些模型的反思机制反而降低23%的准确率!接下来我们将深度解析这个「AI大脑CT机」的技术原理。
🚀 快速阅读
MME-CoT 是一个用于评估大型多模态模型链式思维推理能力的基准测试框架。
- 核心功能:覆盖六大领域,提供细粒度的推理质量、鲁棒性和效率评估。
- 技术原理:基于高质量多模态数据集和 GPT-4o 等模型,解析并评估推理步骤。
MME-CoT 是什么
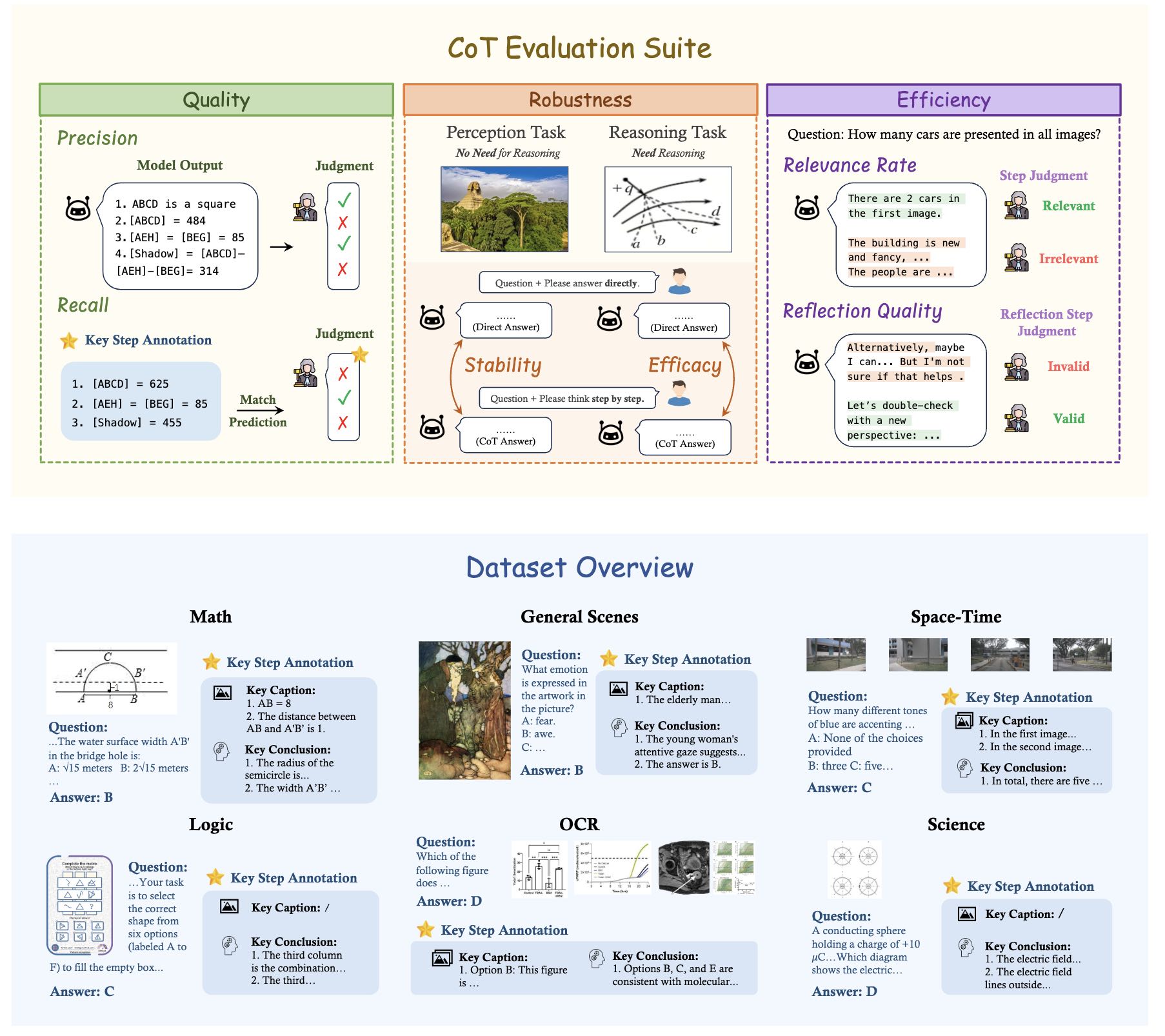
MME-CoT 是由香港中文大学(深圳)、香港中文大学、字节跳动、南京大学、上海人工智能实验室、宾夕法尼亚大学、清华大学等机构共同推出的基准测试框架,旨在评估大型多模态模型(LMMs)的链式思维(Chain-of-Thought, CoT)推理能力。该框架涵盖数学、科学、OCR、逻辑、时空和一般场景等六个领域,包含 1,130 个问题,每个问题都标注了关键推理步骤和参考图像描述。
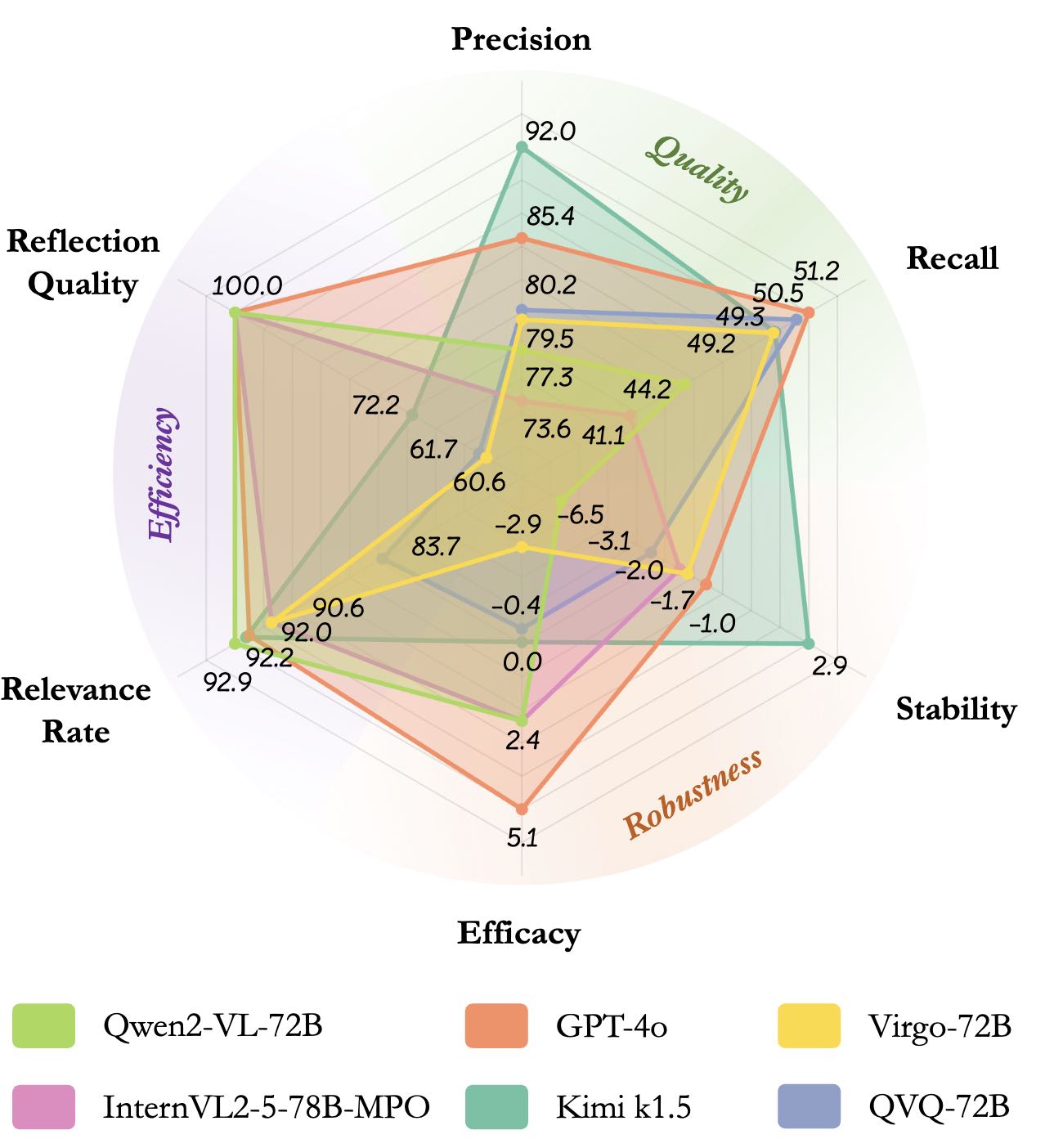
MME-CoT 基于三个新颖的评估指标——推理质量(逻辑合理性)、鲁棒性(对感知任务的干扰)和效率(推理步骤的相关性)——对模型的推理能力进行全面评估。实验结果揭示了当前多模态模型在 CoT 推理中存在的一些关键问题,例如反思机制的低效性和对感知任务的负面影响。
MME-CoT 的主要功能
- 多领域推理能力评估:覆盖六个主要领域(数学、科学、OCR、逻辑、时空和一般场景),全面评估模型在不同场景下的推理能力。
- 细粒度推理质量评估:基于标注关键推理步骤和参考图像描述,评估模型推理的逻辑合理性(质量)、鲁棒性(对感知任务的干扰)和效率(推理步骤的相关性)。
- 揭示模型推理问题:揭示当前多模态模型在 CoT 推理中存在的问题,例如反思机制的低效性和对感知任务的干扰。
- 为模型优化提供参考:提供的评估结果和分析为多模态模型的设计和优化提供重要的参考,帮助研究人员改进模型的推理能力。
MME-CoT 的技术原理
- 多模态数据集构建:构建高质量的多模态数据集,包含 1,130 个问题,覆盖六个领域和 17 个子类别。每个问题都标注关键推理步骤和参考图像描述,用于评估模型的推理过程。
- 细粒度评估指标:
- 推理质量:基于召回率(Recall)和精确率(Precision)评估推理步骤的逻辑合理性和准确性。
- 推理鲁棒性:基于稳定性(Stability)和效能(Efficacy)评估 CoT 对感知任务和推理任务的影响。
- 推理效率:基于相关性比例(Relevance Rate)和反思质量(Reflection Quality)评估推理步骤的相关性和反思的有效性。
- 推理步骤解析与评估:用 GPT-4o 等模型将模型输出解析为逻辑推理、图像描述和背景信息等步骤,逐一对步骤进行评估。

如何运行 MME-CoT
前置条件
在运行评估之前,请确保完成以下准备工作:
- 克隆或下载 MME-CoT 项目代码库。
- 安装所需的依赖包。
- 准备模型的预测文件,并按照指定格式存储。
使用 MME-CoT 进行模型评估
1. 安装依赖包
在运行评估脚本之前,需要安装项目所需的依赖包。可以通过以下命令完成安装:
pip install -r requirements.txt
2. 格式化模型预测文件
模型预测文件需要按照指定的 JSONL 格式存储。每行对应一个问题的回答,并保留数据集中问题的其他相关信息。
- 文件命名规则:
_cot.json:表示使用链式思维(CoT)提示的回答。_dir.json:表示使用直接提示的回答。
示例 JSONL 文件内容如下:
{"question_id": "001", "question": "What is 2+2?", "answer": "4", "model_answer": "2 + 2 equals 4.", "cot_prompt": true}
{"question_id": "002", "question": "What is the capital of France?", "answer": "Paris", "model_answer": "The capital of France is Paris.", "cot_prompt": false}
3. 运行评估脚本
MME-CoT 提供了多种评估脚本,用于计算不同指标。以下是运行评估的具体步骤:
3.1. 单独运行某个指标
例如,计算 recall(召回率) 指标:
bash scripts/recall.sh
3.2. 批量运行所有指标
可以通过以下命令对某个目录中的所有模型预测文件运行所有指标:
bash batch_scripts/run_all.py --result_dir results/json
4. 计算评估结果
评估脚本会将每个问题的评估结果缓存到指定目录中。接下来,可以通过以下命令计算最终指标值。
例如,计算 recall(召回率) 的最终分数:
python final_score/recall.py --cache_dir cache/recall --save_path final_results
脚本结构说明
以下是 scripts 目录中的主要脚本及其功能:
- scripts
- recall.sh # 评估 recall(召回率)
- precision.sh # 评估 precision(精确率)
- reflection_quality.sh # 评估 reflection quality(反思质量)
- relevance_rate.sh # 评估 relevance rate(相关性率)
- extract.sh # 直接评估的第一步:从模型回答中提取最终答案
- judge.sh # 直接评估的第二步:判断提取答案的正确性
资源
- 项目主页:https://mmecot.github.io/
- GitHub 仓库:https://github.com/CaraJ7/MME-CoT
- HuggingFace 仓库:https://huggingface.co/datasets/CaraJ/MME-CoT
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









