







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎧 “告别卡顿!SepLLM 让大模型推理速度提升 50%,长文本处理不再是难题!”
大家好,我是蚝油菜花。你是否也遇到过——
- 👉 大模型推理速度慢,长文本处理卡顿严重
- 👉 内存占用高,资源消耗大,部署成本居高不下
- 👉 多轮对话和文档摘要任务中,上下文连贯性难以维持
今天揭秘的 SepLLM,用分隔符压缩技术彻底颠覆了大语言模型的推理效率!这个由香港大学和华为诺亚方舟实验室联合开发的高效框架,通过压缩段落信息并消除冗余标记,显著提升了模型的推理速度和计算效率。无论是处理 400 万标记的长序列,还是优化 KV 缓存使用量,SepLLM 都表现出色。接下来,我们将深入解析它的核心功能和技术原理,手把手教你如何部署和使用!
🚀 快速阅读
SepLLM 是一个用于加速大语言模型的高效框架,通过压缩段落信息并消除冗余标记,显著提高了模型的推理速度和计算效率。
- 核心功能:支持长文本处理、推理与内存效率提升、多场景部署灵活性。
- 技术原理:基于稀疏注意力机制和动态 KV 缓存管理,优化计算负担和内存使用。
SepLLM 是什么
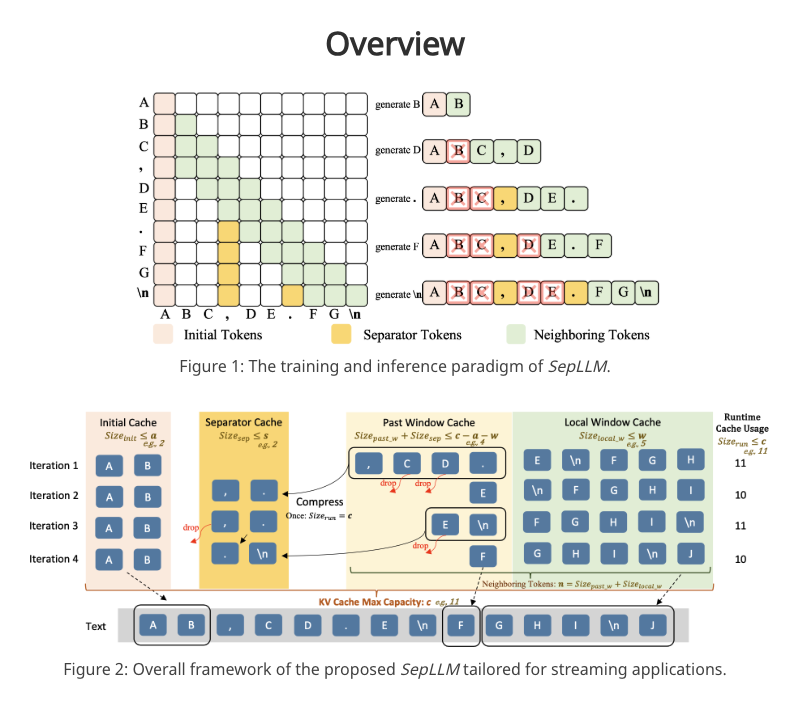
SepLLM 是香港大学、华为诺亚方舟实验室等机构联合提出的用于加速大语言模型(LLM)的高效框架。它通过压缩段落信息并消除冗余标记,显著提高了模型的推理速度和计算效率。SepLLM 的核心是利用分隔符(如标点符号)对注意力机制的贡献,将段落信息压缩到这些标记中,减少计算负担。
SepLLM 在处理长序列(如 400 万标记)时表现出色,保持了低困惑度和高效率。它支持多节点分布式训练,集成了多种加速操作(如 fused rope 和 fused layer norm),适用于文档摘要、长对话等需要维持上下文连贯性的任务。
SepLLM 的主要功能
- 长文本处理能力:SepLLM 能高效处理超过 400 万个标记的长序列,适用于文档摘要、长对话等需要维持上下文连贯性的任务。
- 推理与内存效率提升:在 GSM8K-CoT 基准测试中,SepLLM 将 KV 缓存使用量减少了 50% 以上,同时计算成本降低 28%,训练时间缩短 26%,推理速度显著提升。
- 多场景部署灵活性:SepLLM 支持从零训练、微调和流式应用等多种部署场景,能与预训练模型无缝集成。
- 支持多节点分布式训练:SepLLM 的代码库支持高效的多节点分布式训练,集成了多种加速训练的操作(如 fused rope、fused layer norm 等)。
SepLLM 的技术原理
- 稀疏注意力机制:SepLLM 主要关注三类标记:初始标记、邻近标记和分隔符标记。通过 mask 矩阵限制注意力计算范围,仅计算这些标记之间的注意力,实现稀疏化。
- 动态 KV 缓存管理:SepLLM 设计了专门的缓存块,包括初始缓存、分隔符缓存、历史窗口缓存和局部窗口缓存。通过周期性压缩和更新策略,SepLLM 能高效处理长序列,同时减少 KV 缓存的使用。
如何运行 SepLLM
1. 环境准备
首先,创建一个 Conda 环境并安装所需的依赖:
conda create -yn streaming-sepllm python=3.8
conda activate streaming-sepllm
pip install torch torchvision torchaudio # 我们使用 torch==2.1.0+cu121 进行流式测试。
pip install transformers==4.33.0 accelerate datasets evaluate wandb scikit-learn scipy sentencepiece
python setup.py develop
2. 评估 Streaming-SepLLM
运行以下命令来评估 Streaming-SepLLM:
CUDA_VISIBLE_DEVICES=0 python ./main/evaluate_streaming_inputs_perplexity.py \
--model_name_or_path meta-llama/Meta-Llama-3-8B\
--init_cache_size 4 \
--sep_cache_size 64 \
--local_size 256 \
--cache_size 800 \
--enable_kv_cache_manager True \
--enable_SepLLM True \
--enable_StreamingLLM False \
--enable_pos_shift True \
--num_samples 5000000 \
--num_eval_tokens 20480 \
--dataset_name pg19 \
--task default \
--split test\
--output_dir ./outputs/xxx 2>&1 | tee ./logs/demo/xxx.log
3. 训练 SepLLM
安装训练所需的依赖:
cd Training-SepLLM
pip install -r requirements/requirements.txt
python ./megatron/fused_kernels/setup.py install # 可选,如果不使用 fused kernels
启动训练:
python ./deepy.py train.py [path/to/config.yml]
资源
- 项目主页:https://sepllm.github.io/
- GitHub 仓库:https://github.com/HKUDS/SepLLM
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









