






在EfficientML.ai上学了一下parallel computing的几种方式,来尝试一下效果吧!
整体尝试
基于项目GitHub - mit-han-lab/parallel-computing-tutorial
执行
make -j4
后,报错,找不到pthread相关的内容
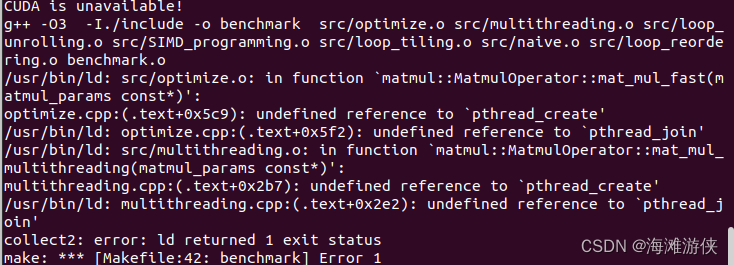
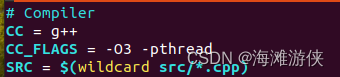
添加下面修改后解决问题,
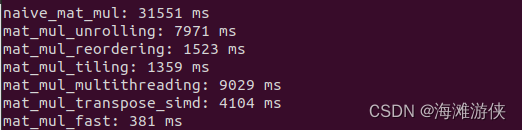
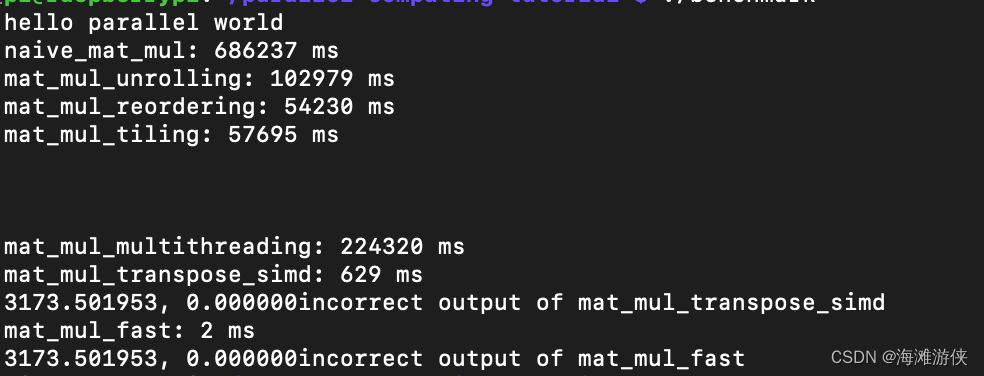
 在 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GH的笔记本上来看看执行benchmark后的效果,可以看到最后一种是上述集中的组合,所以加速效果最好,CUDA没有启用。
在 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GH的笔记本上来看看执行benchmark后的效果,可以看到最后一种是上述集中的组合,所以加速效果最好,CUDA没有启用。
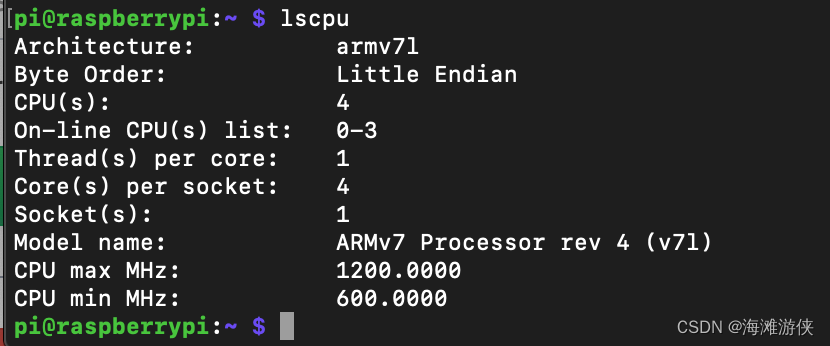
接下来又尝试基于树莓派查看一下加速效果,运行等待时间很长。。。
NEON加速调用
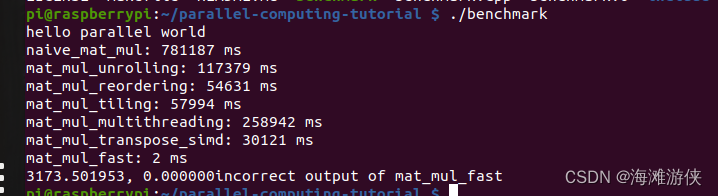
值得注意的是,后两个计算结果不正确,原因是arm上编译没有自动调用neon优化的宏。解决办法是修改cmakelists.添加 --mfpu=neon 可以调用neon加速。否则,将不再自动启动。
下面是计算结果,可看到,neon的计算结果正常,但是(只有)最后一行结果不正确。原因进一步分析中。
目前为止,确认了并行计算在x86和ARM两大算力平台的区别。
ARM由于架构不同,需要增加的编译选项也不一致。

在Nvidia TX2上进行调试后,进行分析,发现CPU算力确实明显强于Raspberry Pi3

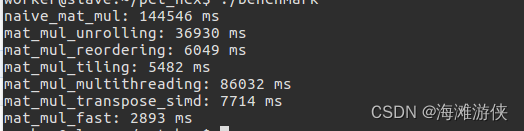
NEON加速方式分析
TODO
参考文献















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









