







 文章介绍了开源项目AnyText,阿里巴巴推出的可支持中英日韩多语言的图像文本生成与编辑工具,尤其解决了StableDiffusion和DALL·E3在非英文语言上的局限。项目使用扩散方法和特定的损失函数来保证文本生成的准确性与图像协调性。
文章介绍了开源项目AnyText,阿里巴巴推出的可支持中英日韩多语言的图像文本生成与编辑工具,尤其解决了StableDiffusion和DALL·E3在非英文语言上的局限。项目使用扩散方法和特定的损失函数来保证文本生成的准确性与图像协调性。
介绍
大家好,最近有个开源项目比较有意思,解决了图像中不支持带有中文的问题。
https://github.com/tyxsspa/AnyText。
为什么不能带有中文?
数据集局限
Stable Diffusion的训练数据集以英文数据为主,没有大量包含其他语言文本的图像数据。这导致模型对非英文语言的理解和生成能力比较弱。
DALL·E 3 也是类似情况,带有英文情况可以,带有其它语言效果不理想。
多语言处理能力有限
Stable Diffusion的底层语言模型是英文预训练的,没有经过中文细化。它对中文词汇、语法、语义的理解和生成能力有限。
文本渲染能力有限
将文本渲染成逼真图像方面存在局限性,较难生成自然、连贯的中文文本。

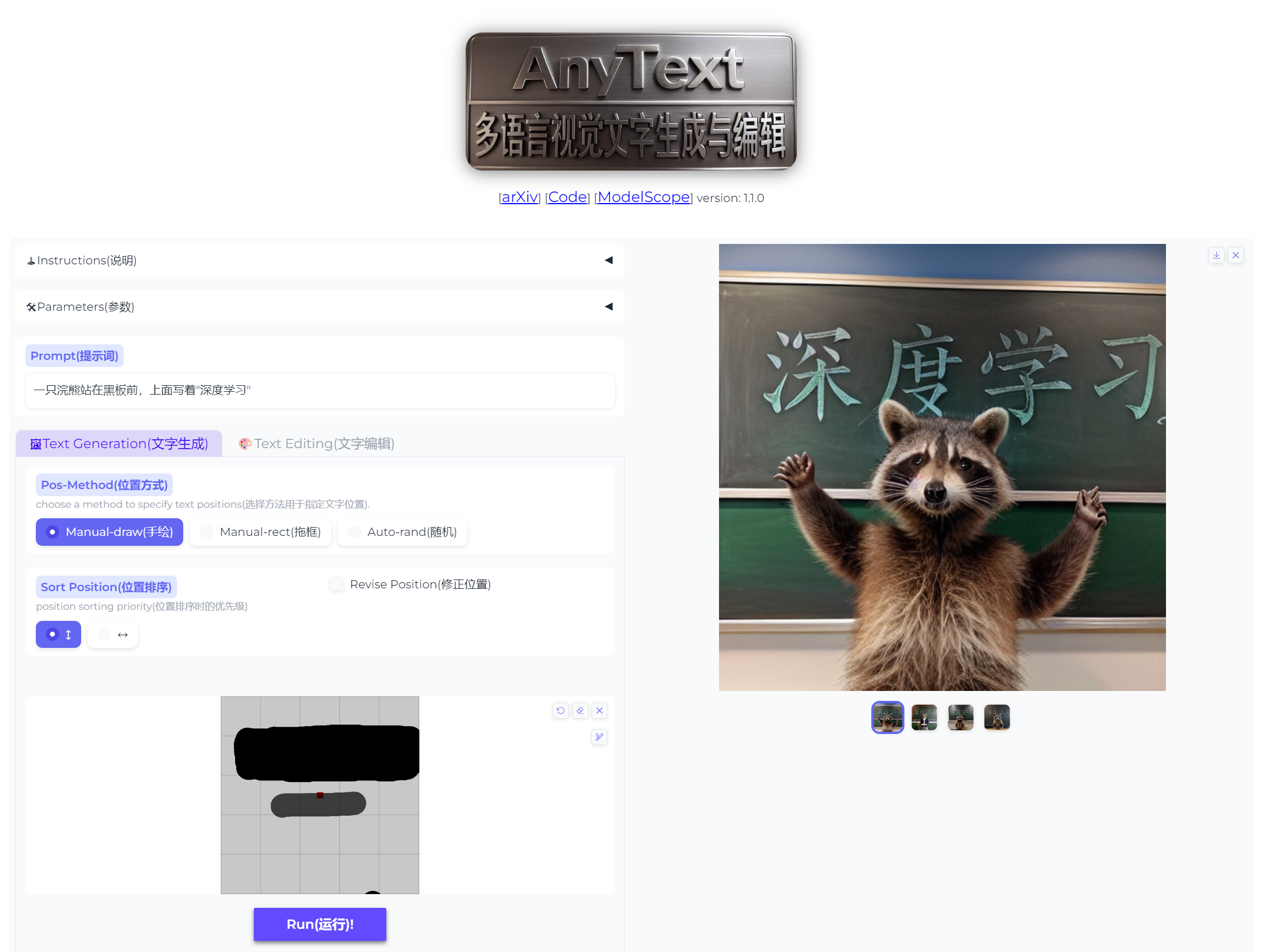
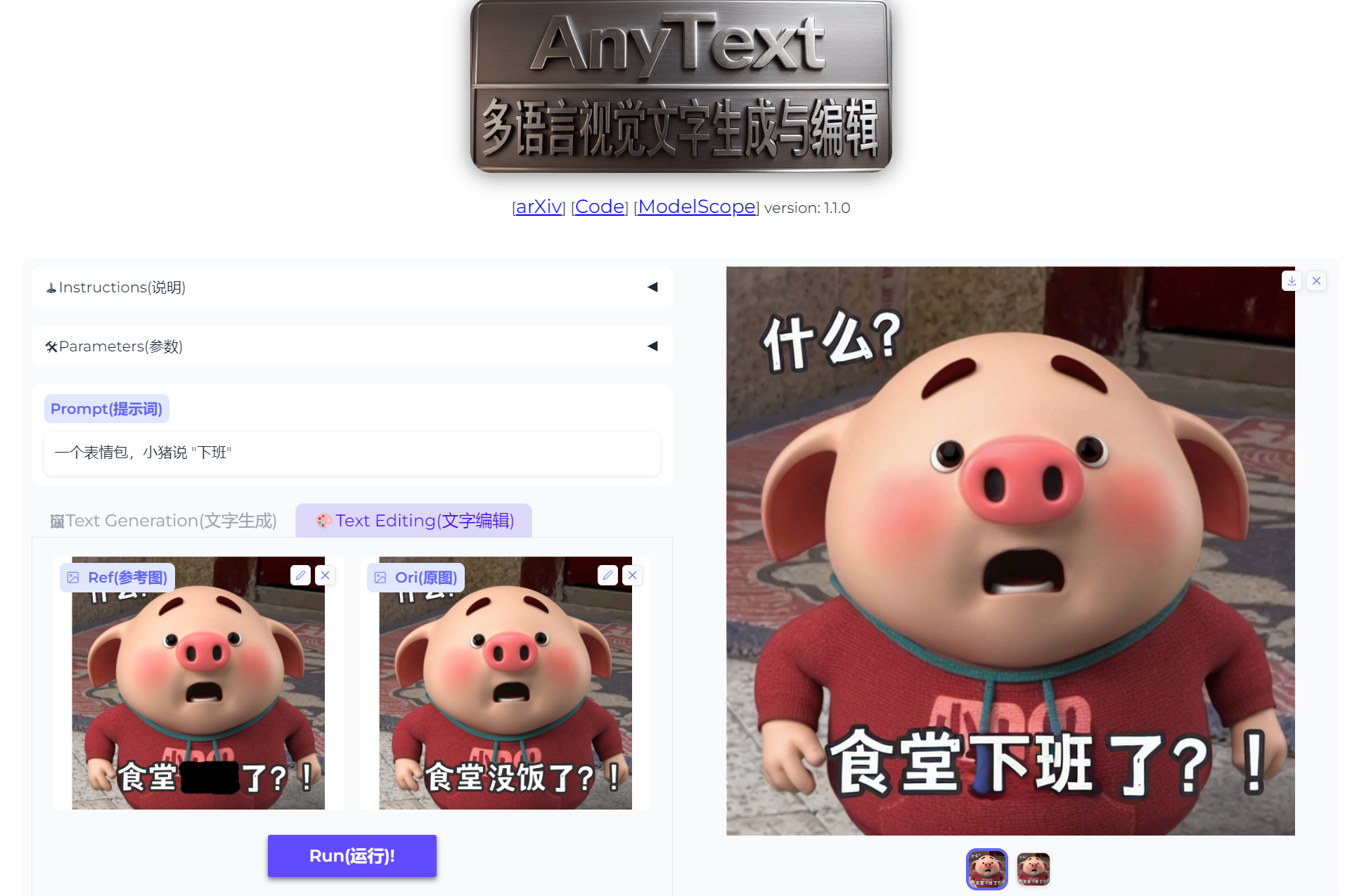
AnyText的绘图工具
阿里巴巴推出开源项目,指定位置精准地向图中加入文字。
项目支持中英日韩四种语言,如图。

快速使用
官网提供两个环境。
https://huggingface.co/spaces/modelscope/AnyText
https://modelscope.cn/studios/damo/studio_anytext/summary

架构
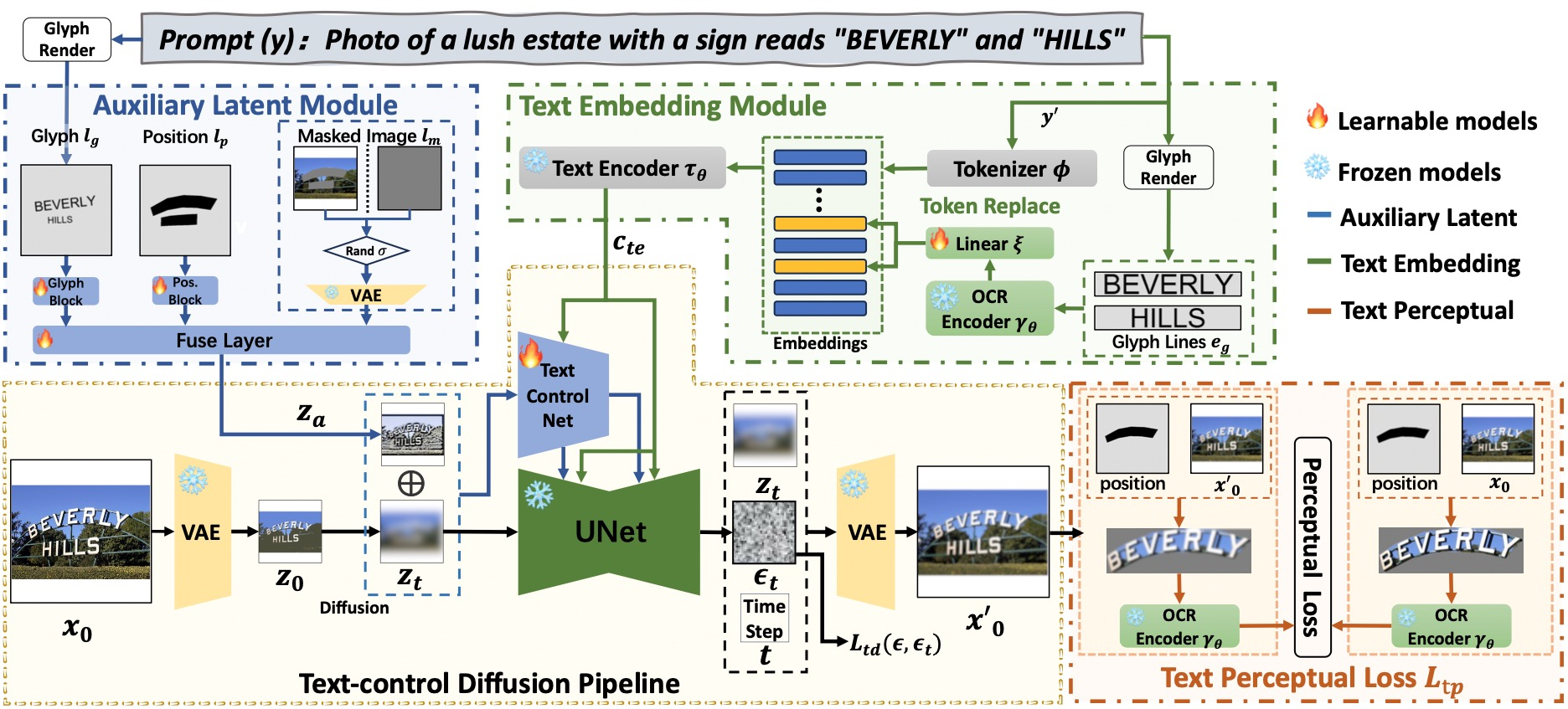
AnyText的架构,一个基于扩散方法设计的文本生成和编辑系统。
-
辅助潜在模块:
- 输入包括文本字形、位置和遮蔽图像。
- 生成有助于在图像中创建或修改文本的潜在特征。
-
文本嵌入模块:
- 利用光学字符识别(OCR)模型将笔画数据编码成嵌入。
- 这些嵌入与由分词器产生的图像标题嵌入相结合。
- 结果是与图像背景无缝融合的文本。
为了训练这个模型,使用了特定的损失函数:
- 文本控制扩散损失: 旨在确保生成的文本准确地遵循控制条件(如位置、风格)。
- 文本感知损失: 提高文本的感知精度,确保其与图像的视觉方面(如字体和比例)保持一致。
这个系统允许准确地生成文本,与图像内容的上下文和视觉效果协调一致。
总结
现在不支持stable diffusion webui 插件,使用只能在官方Demo或者写代码执行。
欢迎交流分享这方面问题,我也深入再尝试下。
朋友们帮忙点赞关注收藏!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











