







 本文详细介绍了GBDT算法,从前向分布算法和负梯度拟合的原理,到损失函数的种类,再到回归问题、二分类、多分类的讨论,并探讨了正则化的角色和GBDT的优缺点。同时提到了GBDT在sklearn中的参数设置及应用场景,适合对机器学习感兴趣的读者深入理解GBDT。
本文详细介绍了GBDT算法,从前向分布算法和负梯度拟合的原理,到损失函数的种类,再到回归问题、二分类、多分类的讨论,并探讨了正则化的角色和GBDT的优缺点。同时提到了GBDT在sklearn中的参数设置及应用场景,适合对机器学习感兴趣的读者深入理解GBDT。
1、前向分布算法
统计学习方法

(假设为树模型)b(x;y)为基函数,使上棵树的预测值与真实值损失函数最小时得到的系数β和γ,其中γ是基函数中特征的权重向量,β为当前树的权重,向前累加基函数,得到当前模型的函数f(x),依次训练直到m的预设值。
2、负梯度拟合
用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。

利用(xi,rti)(i=1,2,..m)(xi,rti)(i=1,2,..m),我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域Rtj,j=1,2,...,JRtj,j=1,2,...,J。其中J为叶子节点的个数。
针对每一个叶子节点里的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的的输出值ctjctj如下(叶子区域最好的拟合值):

本轮的决策树拟合强学习器函数如下(其中I为使c最优的叶子节点集合,求和部分只有一个叶子节点被命中,即残差):
![]()
最终强学习器函数为:
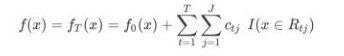
3、损失函数
损失函数(loss function)又叫做代价函数(cost function),是用来评估模型的预测值与真实值不一致的程度,也是神经网络中优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程,损失函数越小,说明模型的预测值就越接近真是值,模型的健壮性也就越好。
常见的损失函数有以下几种:
(1) 0-1损失函数(0-1 lossfunction):
0-1损失函数是最为简单的一种损失函数,多适用于分类问题中,如果预测值与目标值不相等,说明预测错误,输出值为1;如果预测值与目标值相同,说明预测正确,输出为0,言外之意没有损失。其数学公式可表示为:
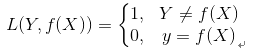
由于0-1损失函数过于理想化、严格化,且数学性质不是很好,难以优化,所以在实际问题中,我们经常会用以下的损失函数进行代替。
(2)感知损失函数(Perceptron Loss): 感知损失函数是对0-1损失函数的改进,它并不会像0-1损失函数那样严格,哪怕预测值为0.99,真实值为1,都会认为是错误的;而是给一个误差区间,只要在误差区间内,就认为是正确的。其数学公式可表示为:
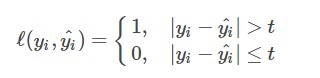
(3)平方损失函数(quadratic loss function):
顾名思义,平方损失函数是指预测值与真实值差值的平方。损失越大,说明预测值与真实值的差值越大。平方损失函数多用于线性回归任务中,其数学公式为:
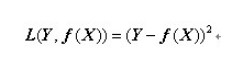
接下来,我们延伸到样本个数为N的情况,此时的平方损失函数为:
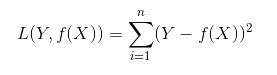
(4)Hinge损失函数(hinge loss function):
Hinge损失函数通常适用于二分类的场景中,可以用来解决间隔最大化的问题,常应用于著名的SVM算法中。其数学公式为:
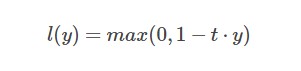
其中在上式中,t是目标值{-1,+1},y为预测值的输出,取值范围在(-1,1)之间。
(5)对数损失函数(Log Loss):
对数损失函数也是常见的一种损失函数,常用于逻辑回归问题中,其标准形式为:
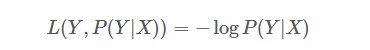
上式中,y为已知分类的类别,x为样本值,我们需要让概率p(y|x)达到最大值,也就是说我们要求一个参数值,使得输出的目前这组数据的概率值最大。因为概率P(Y|X)的取值范围为[0,1],log(x)函数在区间[0,1]的取值为负数,所以为了保证损失值为正数要在log函数前加负号。
(6)交叉熵损失函数(cross-entropy loss function):
交叉熵损失函数本质上也是一种对数损失函数,常用于多分类问题中。其数学公式为:
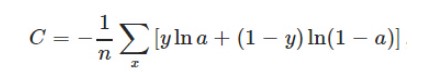
注意:公式中的x表示样本,y代表预测的输出,a为实际输出,n表示样本总数量。交叉熵损失函数常用于当sigmoid函数作为激活函数的情景,因为它可以完美解决平方损失函数权重更新过慢的问题。
本部分出自:http://tensornews.cn/loss_function/
4、回归问题
回归问题也属于监督学习中的一类。按照输入变量与输出变量之间关系的类型,可以分为线性回归和非线性回归。回归用于预测输入变量与输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生的变化。回归模型正是表示从输入变量到输出变量之间映射的函数。回归问题的学习等价于函数拟合:选择一条函数曲线,使其很好地拟合已知数据且很好地预测未知数据。回归问题按照输入变量的个数,可以分为一元回归和多元回归。
5、二分类、多分类
主要区别在于根据业务场景将标签分为两类或者多类。
6、正则化
正则化就是对最小化经验误差函数上加约束,这样的约束可以解释为先验知识(正则化参数等价于对参数引入先验分布)。约束有引导作用,在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识(如一般的l-norm先验,表示原问题更可能是比较简单的,这样的优化倾向于产生参数值量级小的解,一般对应于稀疏参数的平滑解)。有L1、L2正则,防止模型过拟合,也可以将贡献小的特征权重加大。
7、优缺点
优点:
(1)可以灵活处理各种类型的数据,包括连续值和离散值
(2)使用一些健壮的损失函数,对异常值的鲁棒性非常强
(3)在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的
缺点:
(1)当然由于它是Boosting,因此基学习器之前存在串行关系,难以并行训练数据
8、sklearn参数
n_estimators: 也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
learning_rate: 学习率,也称作步长
min_samples_split:生成子节点所需的最小样本数
min_samples_leaf:叶节点所需的最小样本数
max_features:在寻找最佳分割点要考虑的特征数量auto全选
9、应用场景
需要并行计算,数据量大的建模工作,分类回归问题都可以。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









