







转载自: http://blog.csdn.net/bluishglc/article/details/80653801
Job
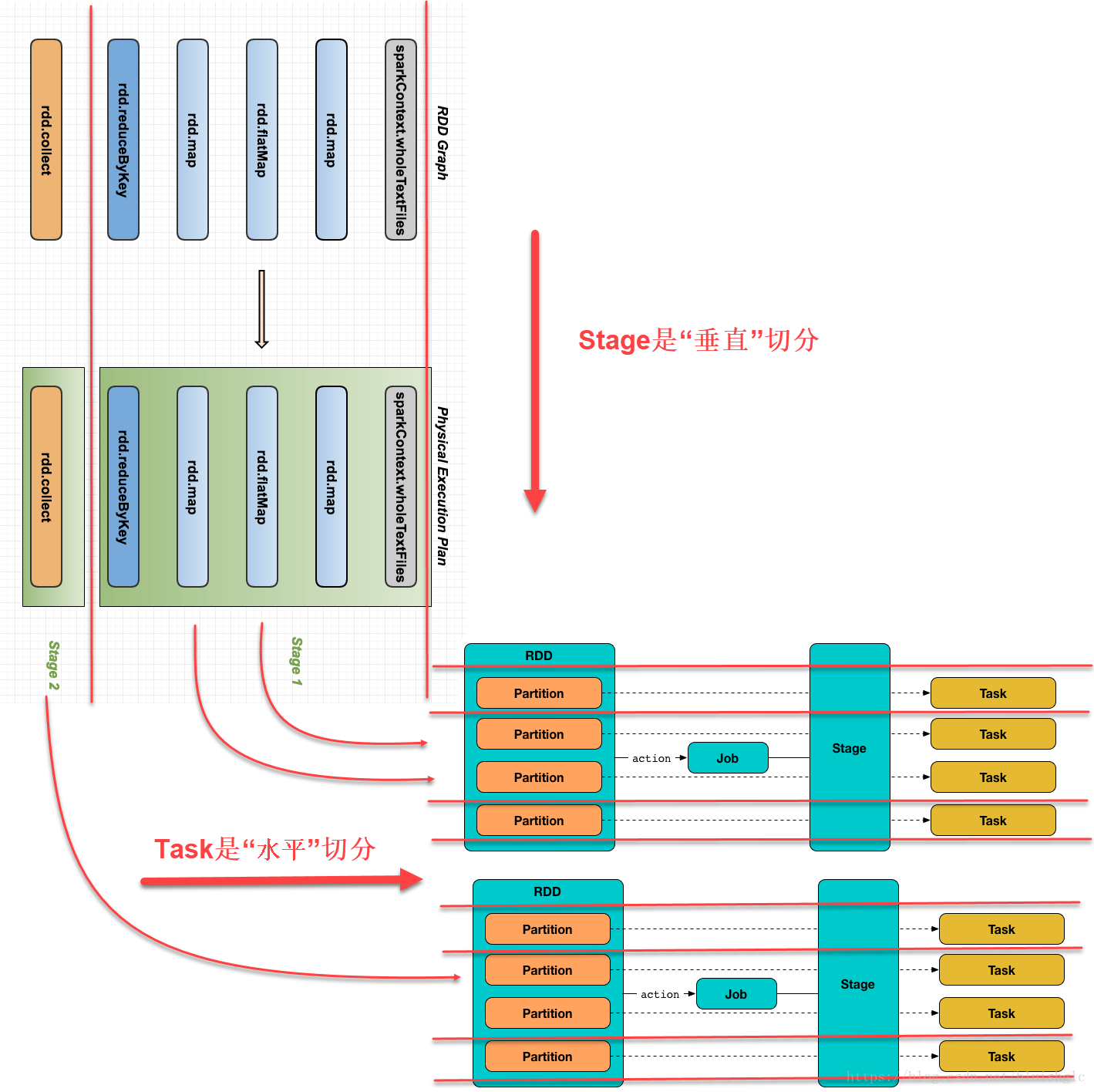
Spark的整个作业体系中,处于顶层的是Job,Job和Action是一一对应的,每一个Action都会触发一个Job的执行,这个Job包含的处理逻辑是Action以及Action之前的所有Transformation,所有这些逻辑会被转换成一张关于RDD的DAG(有向无环图),这个DAG也就是实际意义上的Job的执行计划。
Stage
Job的下一个层级是Stage,一个Stage是由一群task组成的。Stage对标的是shuffle,或者叫宽依赖的transformation,也就是每当在Job执行中遇到一个需要shuffle的transformation时,就将这个transformation和它之前的所有动作放到一个Stage里(当然,如果只action,自然也会触发一个stage),这样的安排是一种很自然的处理方式,究其本质,在一系列的分布式计算中,当遇到shuffle之前,所有的操作都可以在一个单一分区里独立完成,并不需要依赖到其他的分区(例如map,filter这类操作),这些操作可以放在一个流水线(pipline)中执行,这样有助于性能优化,而一但作业中遇到一个需要基于全体数据集(spark称之为all-to-all 操作)进行计算的操作(例如groupByKey, reduceByKey),就需要进行shuffle, shuffle会对全体数据重新洗牌并分区,所以后续的操作不可能和前面的操作放在同一个流水线上,所以每个stage是以一个shuffle来终结的。这里需要对前面提到的transformation的窄依赖和宽依赖进行一个说明:
- 窄依赖指的这个计算在每一个partition上都只依赖于partition自有的数据就可以完成,再直白地解释就是如果某种操作在每一个局部(each partition)做完就相当于全集做完,这就是窄依赖,例如map操作。
- 宽依赖指的这个计算只有在数据全集(all partitions)上执行才能得到结果,例如groupByKey等。
Task
Task是Spark执行作业的最小单位,一个Task对应一个Partition,有多少个partition就会对应生成多少个task,这些task执行的是完全一样的代码,分散到多个executor上执行。可通过配置参数spark.sql.shuffle.partitions 控制产生多少个task, 默认值是200,对于小集群来说,这个数值是比较大的,在性能调优时往往会调小。
Slot和batch
task是一个作业被切分成的最小粒度,也就是执行的最小单位,slot标识并行能力,即一个executor并行执行task的数。如果设置一个task执行时需要多个core,比如需要2个core,假如executor分配了4个core,那么一个executor同时可以执行的task数其实是4/2=2,也就是一个executor的并行能力是2,集群的并行能力再乘以分配的executor的个数。
执行一个task需要的核数通过参数 spark.task.cpus 控制(默认=1,见spark官网http://spark.apache.org/docs/latest/configuration.html)
类:ExecutorAllocationManager 中
// 每个executor的并行能力
private val tasksPerExecutorForFullParallelism =
conf.getInt("spark.executor.cores", 1) / conf.getInt("spark.task.cpus", 1)
// 并行能力不能为0
if (tasksPerExecutorForFullParallelism == 0) {
throw new SparkException("spark.executor.cores must not be < spark.task.cpus.")
}集群的并行能力=spark.num.executors * tasksPerExecutorForFullParallelism
= spark.num.executors * spark.executor.cores / spark.task.cpus并行能力越高,一个batch可执行的task就越多,需要的batch就越少。
batch = 向上取整(task总数/ 集群slot数)一个“立体”的视图
Job->Stage和Stage->Task的切分的维度是不太一样的,Stage是对作业的“垂直”切分,分解的依据就是遇到需要shuffle的transformaion或action就切一刀。而Stage->Task的切分则是一种“水平”切分,每一个task要执行的操作就是Stage圈定的所有的操作,只是一个task基于一个partition的数据去执行这些操作,如果Spark配置的是200个分区,则一个Stage就会被“水平”切分成200个Task去并行的执行!
如下图,垂直方向上是可以在单一partition上连续执行的操作,水平方向是可以并行处理的多个分区。















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









