






神经网络其实就是线性层+激活函数,因为激活函数的非线性特性,才使得神经网络的多层有了意义,使得神经网络有更强的表现力。
激活函数选择或者优化的几个考虑点:
- 是否连续且可导,连续可导意味着导数存在,连续,没有断点,也就是说反向传播过程中梯度都是存在的,没有异常值,可以顺利的完成参数更新
- 是否导数几乎为0或者是很小的值,如果很长一段区域导数值非常小,随着神经网络层数增加会出现梯度消失的现象,同理,如果激活函数很陡,意味着导数值非常大,会出现梯度爆炸。
- 激活函数值是否有很长一段为0,激活函数值为0,即前面的线性层经过激活函数后输出为0,相当于神经元死亡
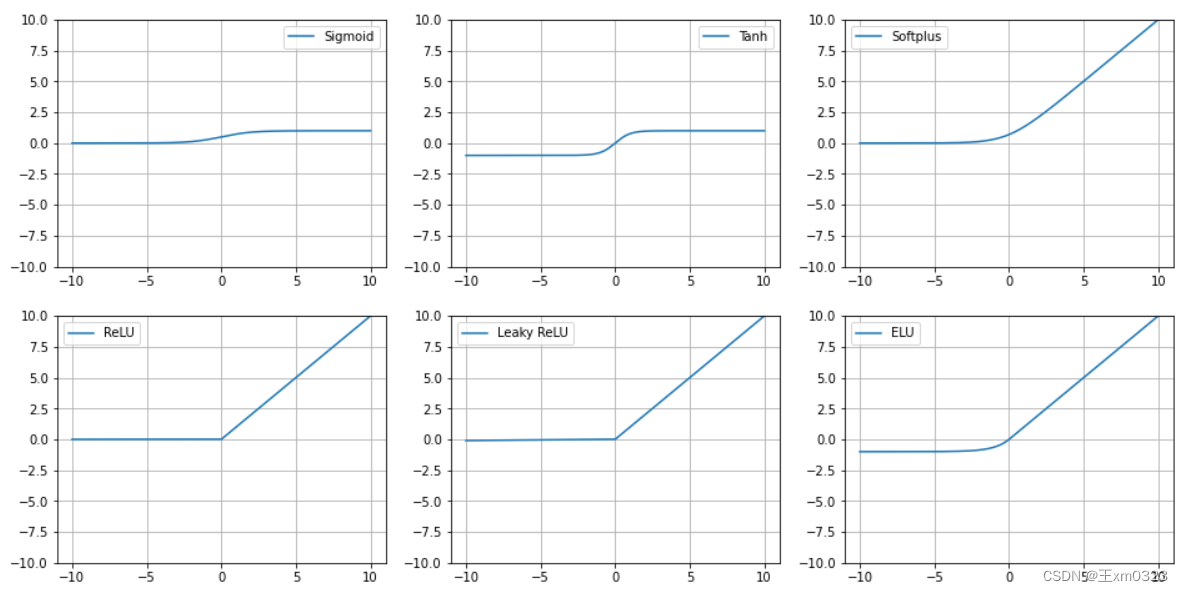
基础的激活函数
Sigmoid、Tanh、ReLu、Softplus、Leaky Relu、ELU
Sigmoid
- 缺点:在x很大或者很小的时候,导数很小几乎为0,会导致梯度消失
Tanh
- 缺点:也是x很小或者很大的时候,导数几乎为0,此时会导致梯度消
ReLu
- 优点:正数部分梯度恒为1,计算简单,也解决了梯度消失问题
- 缺点:负数部分激活函数值是0,会导致部分神经元无法激活,会导致这部分参数不被更新,即“神经元死亡”的情况。
Softplus
可以看作是Relu的平滑
- 优点:
- Softplus函数是ReLU函数的平滑版本,避免了在零点处不可导的问题。
- 具有较好的非线性特性,在一些深度神经网络中表现良好。
- 局限性:
- Softplus函数的计算较复杂,可能会增加模型的训练时间。
- 当x较大时,Softplus函数的输出接近线性关系,可能导致信息损失
LeakyReLu
,α一般取0.01,所以导数小于等于0时是α,大于0是1,都是常数
- 优点:
- 解决了ReLU函数在负数部分输出为零的问题,避免了“神经元死亡”的情况。
- 保留了ReLU函数的大部分优点,计算简单,不会出现梯度爆炸问题。
- 局限性:
- 需要额外的参数α,需要手动调整或者通过训练学习,增加了模型的复杂性。α的值选择不当时,可能会导致模型性能下降
ELU
2016年https://arxiv.org/pdf/1511.07289
- 优点:
- 在输入大于零时,ELU导数始终为1,避免梯度爆炸和消失。
- 在输入小于等于零时,ELU函数不会输出零,解决了ReLU函数的“神经元死亡”问题,增强了模型的稳定性。
- 局限性:
- ELU函数相对复杂,计算代价较高。
matplotlib绘图及代码如下:
import matplotlib.pyplot as plt
import numpy as np
# 定义一些常用的激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
def softplus(x):
return np.log(1 + np.exp(x))
def relu(x):
return np.maximum(0, x)
def leaky_relu(x):
return np.maximum(0.01 * x, x)
def elu(x):
return np.where(x > 0, x, np.exp(x) - 1)
# X轴的范围
x = np.linspace(-10, 10, 1000)
# 创建画布
fig, axes = plt.subplots(2, 3) # 表示画布分为2行3列
print(axes.shape)
fig.set_size_inches(16, 8) # 整个大小为10,高为6
# 设置图例
plt.legend()
reactions = {
"Sigmoid":sigmoid(x),
"Tanh": tanh(x),
"Softplus": softplus(x),
"ReLU": relu(x),
"Leaky ReLU": leaky_relu(x),
"ELU": elu(x)
}
i=0
j=0
for key in reactions:
axes[i][j].set_ylim(-10, 10)
axes[i][j].plot(x, reactions.get(key), label=key)
axes[i][j].grid()
axes[i][j].legend()
if j==2:
i += 1
j=0
else:
j += 1
# 显示图像
plt.show()LLM常用激活函数
GELU高斯误差线性函数
文章:https://arxiv.org/pdf/1606.08415.pdf
Bert、albert、roberta、GPT2、Bloom 都用的GELU
公式如下:
![]()
Φ是正态分布的累计分布函数,论文中提到之所以选择正态分布是因为神经元的输入往往遵循正态分布
可以用下面两种公式逼近:

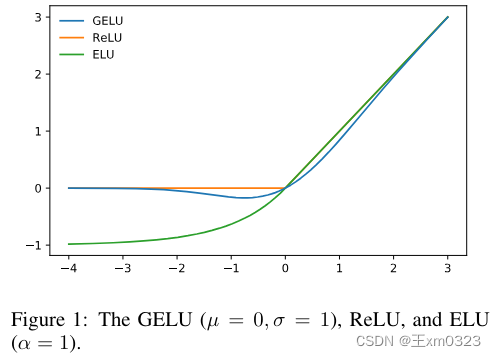
- 优点:
- GELU在整个实数域都是连续且光滑的,有助于训练过程中梯度的传播,进而提高模型训练效率和收敛速度
- GELU在x很大时也没有出现梯度趋近于0的情况,避免了梯度消失的问题
- 缺点:
- 计算复杂,实际应用中一般使用近似替代公式,可能会导致某种程度上精度的损失,尽管损失大多情况下没影响,但极端情况下会有影响
- 对模型参数初始化的值比较敏感,可能会因初始化参数导致训练初期梯度消失或者爆炸
- 由于GELU函数复杂,对于 用到GELU的地方 的理解和调参 可能更具挑战性。
SwichGLU
是switch激活函数在GLU门控线性单元的基础上改进得到的。
Swish 激活函数
《Searching for Activation Functions》是2017 google提出来的,论文中定义Switch是
Swish is defined as x · σ(βx), where σ(z) = (1 + exp(−z))−1 is the sigmoid function and β is either a constant or a trainable parameter.
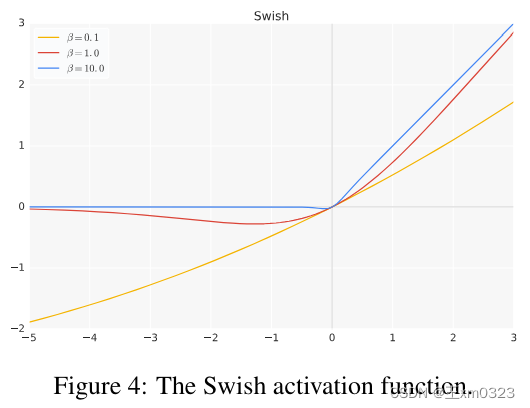
和ReLu一样,Switch在上界是无限的,下界是有限的,不过Switch是平滑且非单调的。
GLU门控线性单元
,其中
表示逐元素相乘,
是上一层通过全连接等得到的中间向量
![]()
其中是sigmoid函数,相当于门控单元。
SwitchGLU
后来2020年在《GLU Variants Improve Transformer》 中提出使用GLU的变种来改进Transformer的FFN层,就是将GLU中原始的Sigmoid激活函数替换为其他的激活函数,作者列举了替换为ReLU,GELU和SwiGLU的三种变体,公式如下:
![]()
去掉bias:

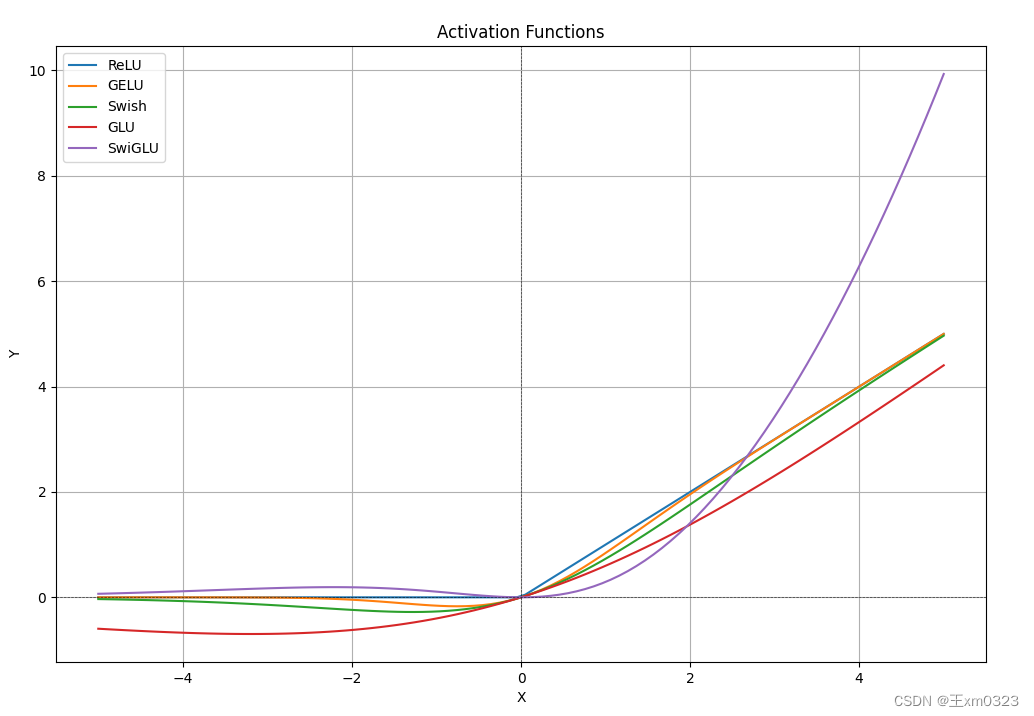
优点
- Swish对于负值的响应相对较小克服了 ReLU 某些神经元上输出始终为零的缺点
- GLU 的门控特性,这意味着它可以根据输入的情况决定哪些信息应该通过、哪些信息应该被过滤。这种机制可以使网络更有效地学习到有用的表示,有助于提高模型的泛化能力。在大语言模型中,这对于处理长序列、长距离依赖的文本特别有用。
- SwiGLU 中的参数 W1,W2,W3,b1,b2,b3W1,W2,W3,b1,b2,b3 可以通过训练学习,使得模型可以根据不同任务和数据集动态调整这些参数,增强了模型的灵活性和适应性。
- 计算效率相比某些较复杂的激活函数(如 GELU)更高,同时仍能保持较好的性能。这对于大规模语言模型的训练和推理是很重要的考量因素。
参考:
为什么大型语言模型都在使用 SwiGLU 作为激活函数?-腾讯云开发者社区-腾讯云
SwitchGLU在LLM的应用
LLama、Baichuan、Qwen、ChatGLM2 等用的都SwitchGLU
源码配置文件中配置的是使用SiLU,
,其中
是sigmoid函数,等于β=1的Switch,
实际FFN就是基于silu搭建的swiGLU
"""
baichuan MLP 源码
"""
hidden_act="silu" # 激活函数
self.act_fn = ACT2FN[hidden_act]
self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False) # 线性层
# swiglu就是self.act_fn(self.gate_proj(x)) * self.up_proj(x)
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))














 4733
4733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









