







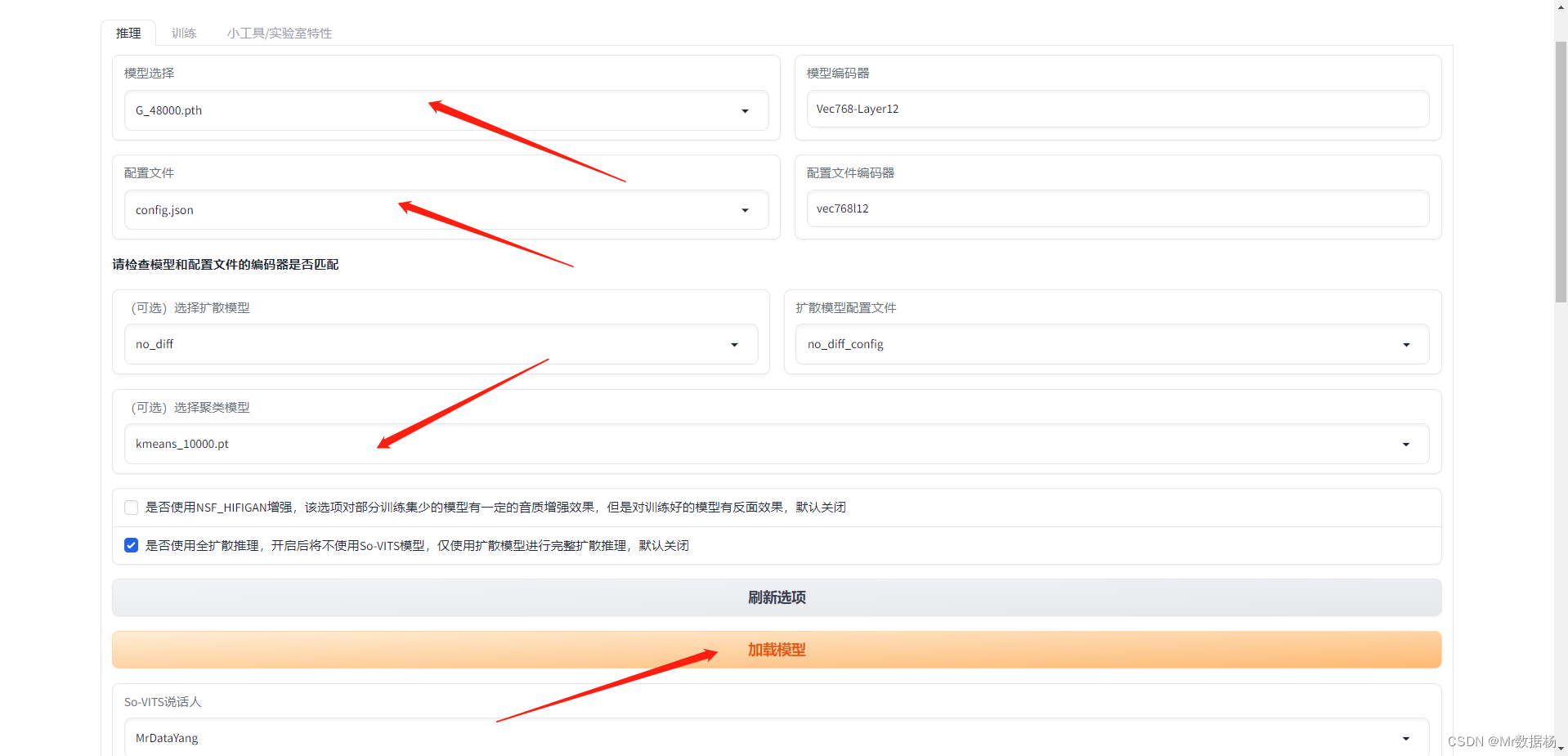
 在使用VITS进行声音克隆时遇到声音质量问题,可能是模型训练或参数设置不当。通过调整声音预测参数,参照图片设置获取模型,以及采用微软TTS分段文本转语音并克隆,可以有效解决音频异常。同时,注意文件目录的整理,批量上传预测音频文件,最后将音频合成或保持独立。
在使用VITS进行声音克隆时遇到声音质量问题,可能是模型训练或参数设置不当。通过调整声音预测参数,参照图片设置获取模型,以及采用微软TTS分段文本转语音并克隆,可以有效解决音频异常。同时,注意文件目录的整理,批量上传预测音频文件,最后将音频合成或保持独立。
在构建语音合成或文本转语音(TTS)系统的过程中,声音生成的自然度和流畅性成为一个关键难题。对于初次尝试模型合成声音时,常常会遇到输出音频沙哑、不自然等问题,这与模型的训练数据和参数设定密切相关。本文将从多个方面出发,探讨通过合理的参数设置与优化来提升生成音频的质量,并详细介绍如何借助微软TTS服务来处理文本转语音生成,分段生成语音,以实现高质量音频输出。
文章内容将涵盖从参数设定、代码实现到文件结构的细节介绍。首先,通过展示如何优化合成模型的参数,以避免生成声音中的沙哑和不自然腔调。随后,通过微软TTS服务的配置和调用方法,将文本按段生成音频,解决长音频生成过程中的可能异常。代码示例涵盖从获取API访问令牌、文本分段处理、音频生成与合并等完整流程,帮助读者更系统地掌握文本到音频生成的技术手段。
解决声音沙哑不在然
在合成过程中,声音沙哑或腔调不自然,通常与模型训练和参数设置有关。
为了最大化模型表现,可尝试以下通用参数设置。
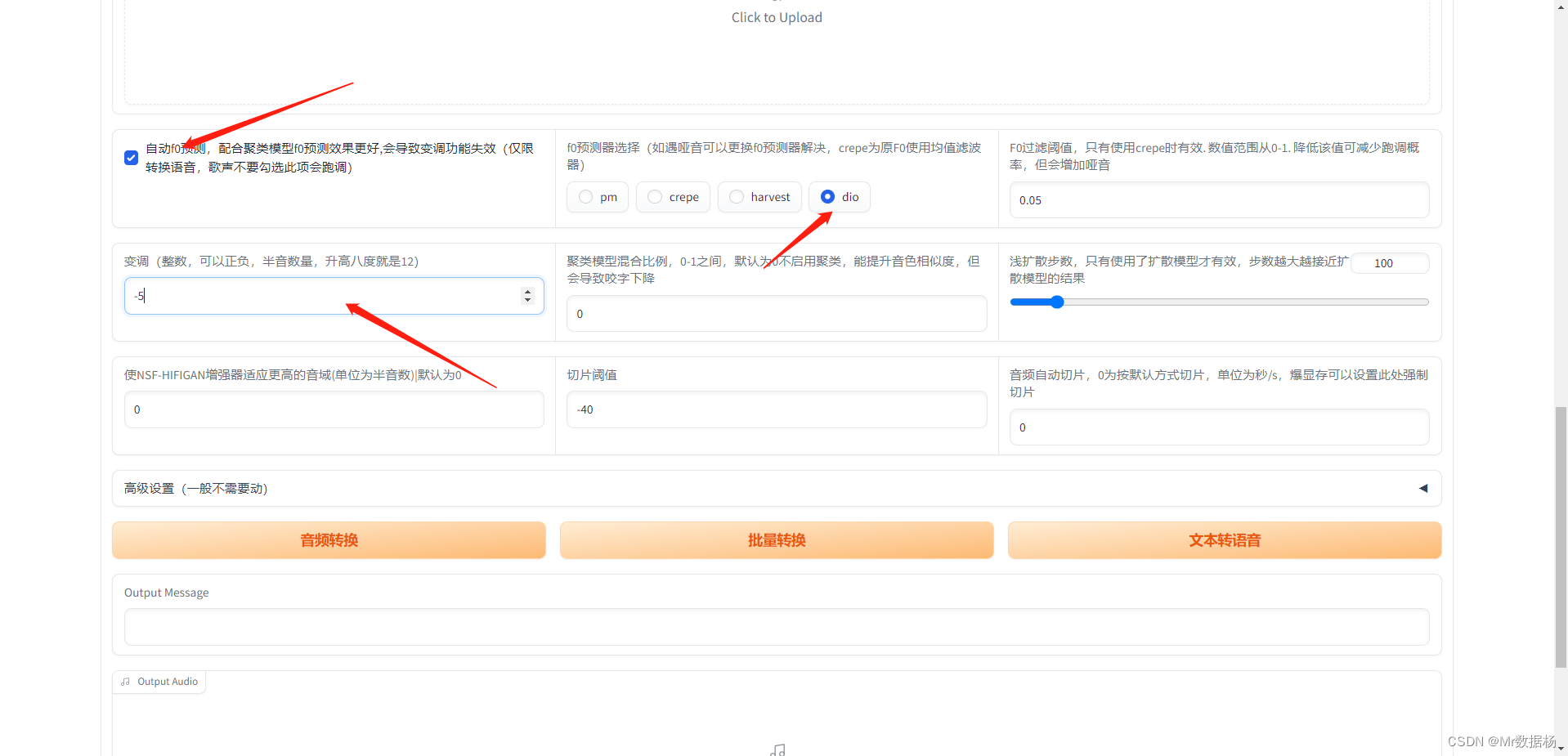
这里的重点其实就选择预测F0,以及语调调整成负数即可。其他的参数都参考模型中训练时候的对应上即可。我训练模型的时候选择过滤器是dio。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











