










测试链接:GitHub - NVlabs/stylegan2-ada-pytorch: StyleGAN2-ADA - Official PyTorch implementation
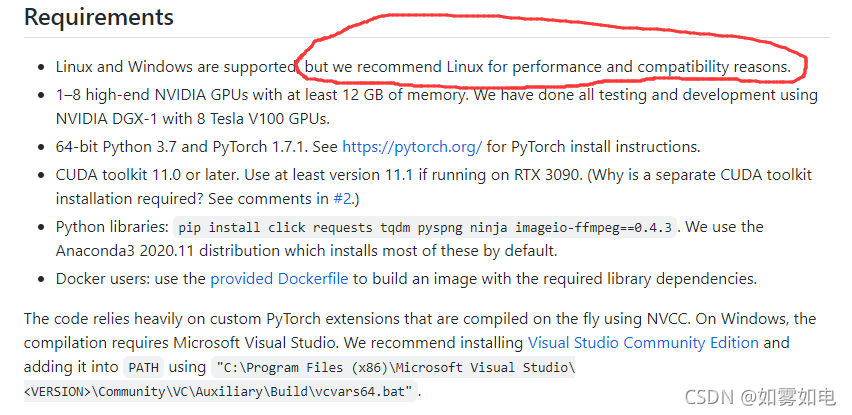
作者说了这个项目在Windows和Linux上都可以跑,但是我Windows遇到一个错误根本解决不了,只能在Linux上跑,如果你在Windows上遇到了很难解决的问题并且花了一段时间了,那千万不要头铁继续了,就到Linux上跑下,没有Linux就把电脑划出一点空间装双系统,环境配置好了,在Linux上跑基本没有什么问题,下面开始
0.环境
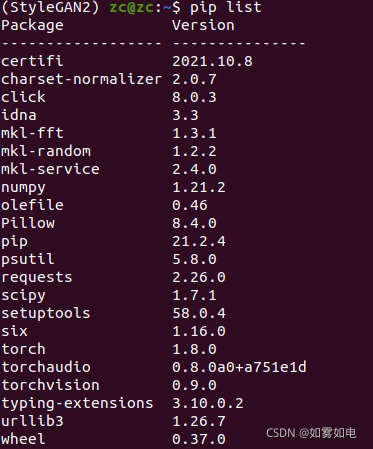
Ubuntu20,python3.8.12,cuda 11.1.1,一开始torch是1.9.0的时候报错,推荐torch1.8.0
1.数据准备
我得数据是人脸数据,1024*1024
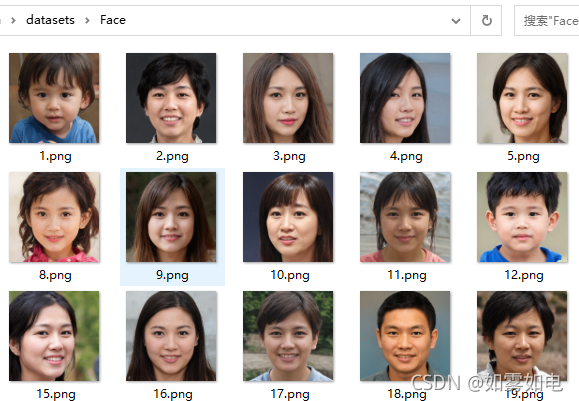
使用根目录下的dataset_tool.py打包训练数据
命令行:
python ./dataset_tool.py --source=./datasets/Face --dest=./datasets/Face.zip--souce参数给数据根目录,--dest参数给压缩数据存放位置
2.训练
python train.py --outdir=./runs/ --data=./datasets/face_ori.zip --gpus=1 --cfg=paper1024 --mirror=1 --resume=ffhq1024 --snap=10 --batch 4 --workers 1其实数据准备好基本就可以开始训练了,训练的速度和效果看官网就知道了,主要是显卡要多,不然特别废时间,我只有一张显卡,测试了1024大小的图像,其它的大小会报错,应该是参数没有对应修改,大家自己探索吧。
3.预测
python generate.py --outdir=result/ --trunc=1 --seeds=85,297,849 --network=./runs/00002-face_ori-mirror-paper1024-batch2-resumeffhq1024/network-snapshot-000600.pkl选择一个训练好的模型,seeds是随机给的,给多少个就会生成多少图像,这里有三个,会生成三张图,具体含义等我仔细看了代码再补,或者有谁知道,评论区说下

跑的次数太少了,有很明显的瑕疵,最后一张很完美,我配置太差了,这个网络玩不来 ,大家自己慢慢探索把


















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











