






1、发展过程
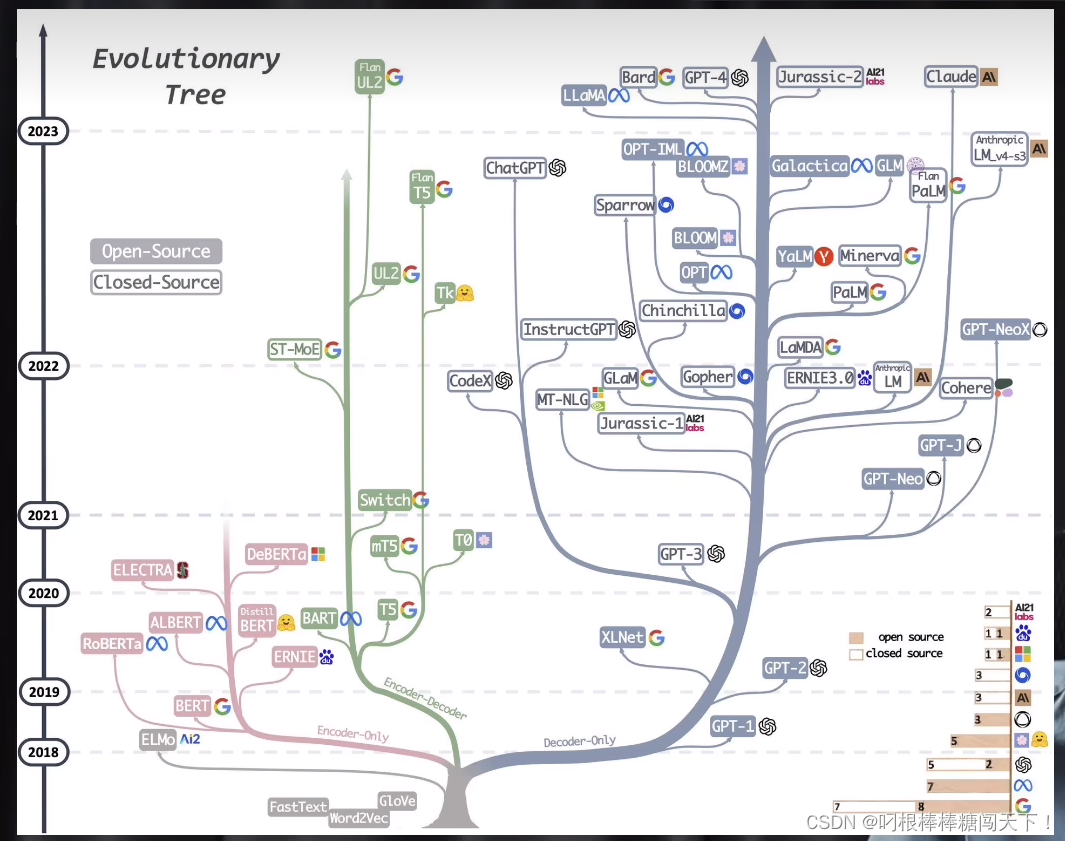
理解transformer的关键是这个编码和解码的结构,那么这个码 是什么码呢?这就要回到最基本的内容了。人工智能最典型的场景,一个是人工识别,一个是自然语言处理。神经网络靠的是CNN,最先在图像识别领域爆发出来的。在NLP领域,也有一个和CNN对应的模型,是RNN(循环神经网络)。


独热编码是对应的语义空间的维度太高了。信息密度过于稀疏。它可以很容易的表示出苹果和香蕉的组合语义。苹果是001,香蕉和010。苹果和香蕉是011.但是独热码的问题是所有的token都是独立的维度。所有的token都互相正交。就很难体现出token之间的语义联系。
向上面的例子中,假如001表示苹果,010表示香蕉,100表示华为。则这三个都是正交的。内交积都是0。相关度为0.用向量表示的话,他们都会分布在距离原点为1的高维球面上。独热编码的问题就体现出来了,各个token之间的关系全是靠维度表示出来的,并没有把空间的长度给利用起来。分词器呢,则是把所有的语义都变成了长度问题。完全没有利用维度信息去表示语义信息。2、
解决方法:
前面已经描述了,这两个问题就是两个相反的极端。那么我们可以想一想办法,来进行一个融合。找一个维度高,但是又没有那么高的空间,去协助完成编码和解码的任务。
这个空间也就是我们经常听到的潜空间。那么,具体应该找潜空间呢?有两个大的方向。一个是基于分词后的id去升维。 另一个是及与独热编码去降维
降维的话,就是线性代数里的矩阵运算。线性代数里的向量和一个矩阵相乘,就一种理解方式,它可以看作一种空间变化。
这里介绍一下为什么乘以一个矩阵就可以变成一个空间变换呢?
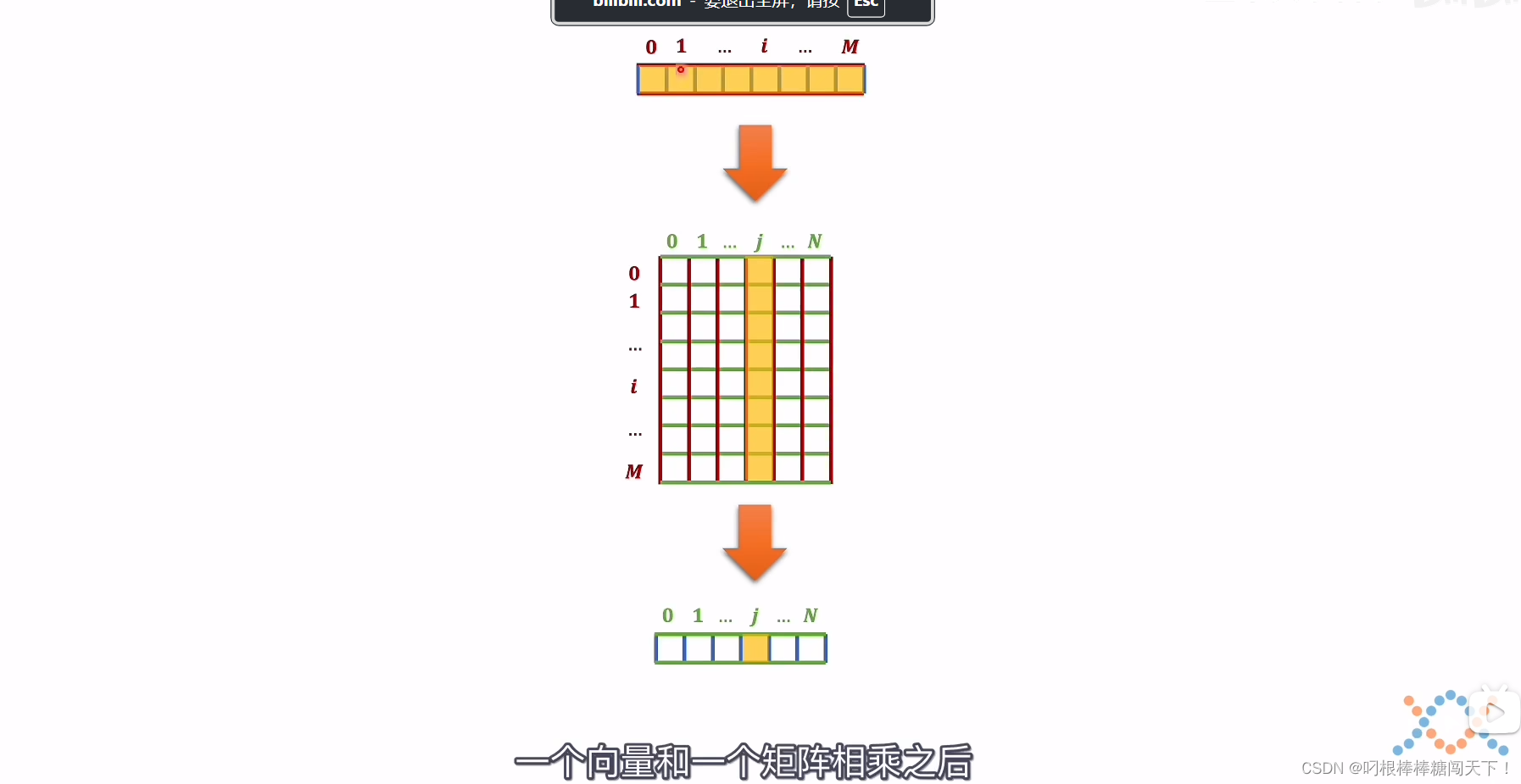
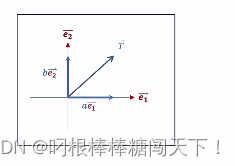
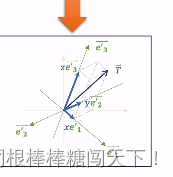
加入这个T向量就是要操作的向量,向量下的每一个数值就像是这个向量在对应的坐标系下的坐标值。也就是T在标准正交基上的e1,e2。
我们就是考虑如何从上面的二维的向量变换到三维的向量。具体的T是什么。在这个变换过程中不重要,重要的是坐标轴如何进行变化,坐标轴可以看成单位向量。
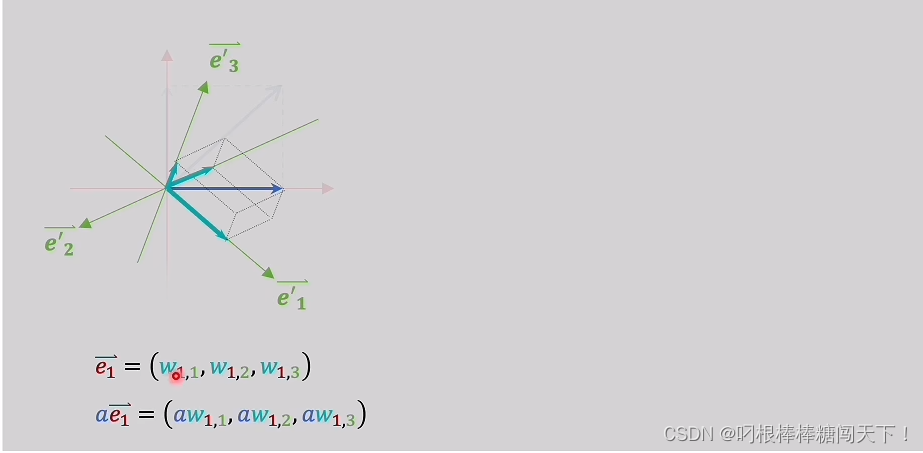
假设坐标轴单位向量e1在新的三维坐标轴上分别是w11,w12,w13。那么新的就可以表示为aw11,aw12,aw13
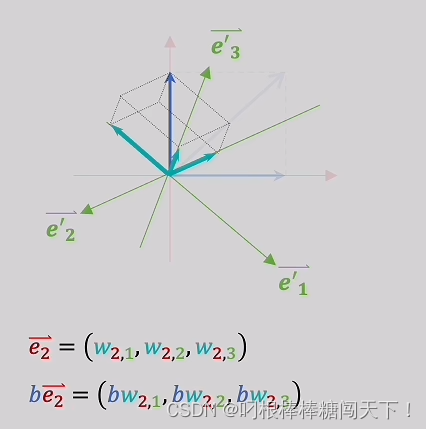
同理,这是二维中另一个向量的三维表示。
所以,二维中的T向量在三维坐标轴中无论什么样子都可以写成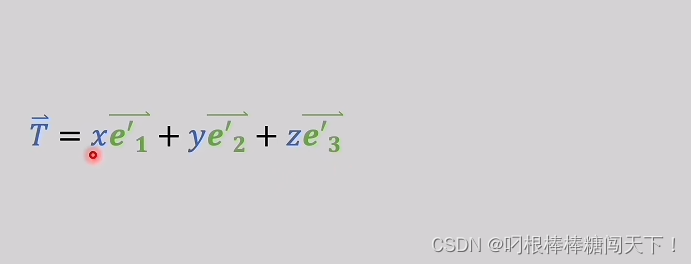
所以,x就是aw11+bw21,y就是aw12+bw22,z就是aw13+bw23。这个w就是表示的原来的坐标轴和新坐标轴之间的变化关系。而a和b体现的是向量的信息。如果用矩阵和向量相乘的信息去写的话,就如下。

矩阵代表的就是旧坐标系和新作坐标系之间的关系。
[
w
11
,
w
12
,
w
13
w
21
,
w
22
,
w
23
]
\begin{bmatrix} & w11,w12,w13 & \\ & w21,w22,w23 & \end{bmatrix}
[w11,w12,w13w21,w22,w23]
一个矩阵的行代表是旧坐标系有多少维度,列代表的就是新坐标系有多少维度。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









