





前言
注意力机制一直是一个比较热的话题,其实在很早之前就提出了,我们在学习图像分类时在SENet就见到过(直通车:经典神经网络论文超详细解读(七)——SENet(注意力机制)学习笔记(翻译+精读+代码复现))自从谷歌发表了《Attention Is All You Need》这篇论文后,注意力机制就真正火起来了,这篇论文本来是NLP领域的,不过在CV领域也有越来越多人开始引入注意力机制。
本来这部分想放在论文里讲的,但最近学习过程中发现还挺多拓展的内容,所以这篇我们就来详细看一下这些注意力机制吧!

 🍀本人Transformer相关文章导航:
🍀本人Transformer相关文章导航:
【Transformer系列(1)】encoder(编码器)和decoder(解码器)
【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解
【Transformer系列(3)】 《Attention Is All You Need》论文超详细解读(翻译+精读)
【Transformer系列(4)】Transformer模型结构超详细解读
目录
🌟三、多头注意力机制:Multi-Head Self-Attention

🌟一、注意力机制:Attention
1.1 什么是注意力机制?
我们先来看一张图片,这个是前几天微博之夜的

那大家的目光更多停留在是在五个美女身上,还是在张大大身上呢 ?(大大老师骚瑞~ORZ)
同样的,不同的粉丝更加关注的对象也是不同的。
再举几个栗子:
- 看人-->看脸
- 看文章-->看标题
- 看段落-->看开头
这时候大家应该大致知道注意力机制是个什么东西了吧~
注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
我用通俗的大白话解释一下:注意力呢,对于我们人来说可以理解为“关注度”,对于没有感情的机器来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方就赋予越高的权重。
1.2 如何运用注意力机制?
1.2.1 Query&Key&Value
首先我们来认识几个概念:
- 查询(Query): 指的是查询的范围,自主提示,即主观意识的特征向量
- 键(Key): 指的是被比对的项,非自主提示,即物体的突出特征信息向量
- 值(Value) : 则是代表物体本身的特征向量,通常和Key成对出现
注意力机制是通过Query与Key的注意力汇聚(给定一个 Query,计算Query与 Key的相关性,然后根据Query与Key的相关性去找到最合适的 Value)实现对Value的注意力权重分配,生成最终的输出结果。

有点抽象吧,我们举个栗子好了:
- 当你用上淘宝购物时,你会敲入一句关键词(比如:显瘦),这个就是Query。
- 搜索系统会根据关键词这个去查找一系列相关的Key(商品名称、图片)。
- 最后系统会将相应的 Value (具体的衣服)返回给你。
在这个栗子中,Query, Key 和 Value 的每个属性虽然在不同的空间,其实他们是有一定的潜在关系的,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
1.2.2 注意力机制计算过程
输入Query、Key、Value:
- 阶段一:根据Query和Key计算两者之间的相关性或相似性(常见方法点积、余弦相似度,MLP网络),得到注意力得分;

- 阶段二:对注意力得分进行缩放scale(除以维度的根号),再softmax函数,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重。一般采用如下公式计算:

- 阶段三:根据权重系数对Value值进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了);
这三个阶段可以用下图表示:

🌟二、自注意力机制:Self-Attention
2.1 什么是自注意力机制?
自注意力机制实际上是注意力机制中的一种,也是一种网络的构型,它想要解决的问题是神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译(序列到序列的问题,机器自己决定多少个标签),词性标注(Pos tagging一个向量对应一个标签),语义分析(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。不是输入语句和输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制。
注意力机制和自注意力机制的区别:
(1)注意力机制的Q和K是不同来源的,例如,在Encoder-Decoder模型中,K是Encoder中的元素,而Q是Decoder中的元素。在中译英模型中,中文句子通过编码器被转化为一组特征表示K,这些特征表示包含了输入中文句子的语义信息。解码器在生成英文句子时,会使用这些特征表示K以及当前生成的英文单词特征Q来决定下一个英文单词是什么。
(2)自注意力机制的Q和K则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,Q和K都是Encoder中的元素,即Q和K都是中文特征,相互之间做注意力汇聚。也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此,自注意力机制(self-attention)也被称为内部注意力机制(intra-attention)。
2.2 如何运用自注意力机制?
其实步骤和注意力机制是一样的。
第1步:得到Q,K,V的值
对于每一个向量x,分别乘上三个系数  ,
,  ,
,
,得到的Q,K和V分别表示query,key和value
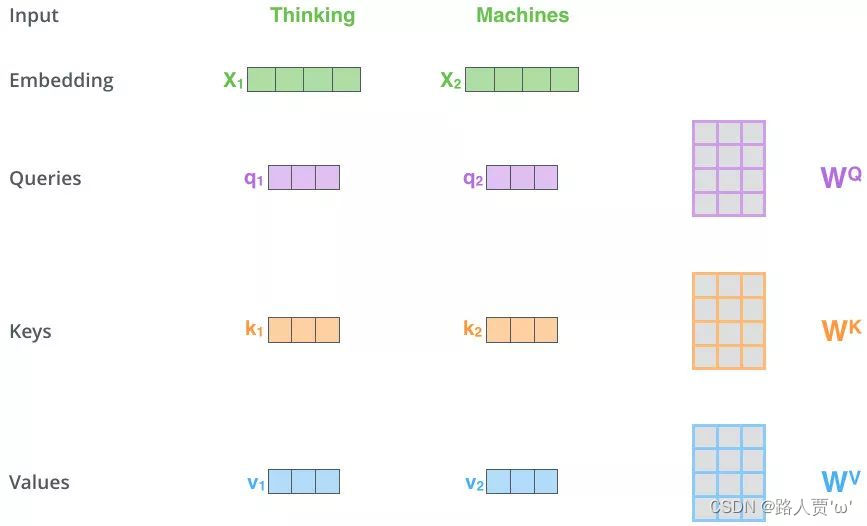
【注意】三个W就是我们需要学习的参数。
第2步:Matmul
利用得到的Q和K计算每两个输入向量之间的相关性,一般采用点积计算,为每个向量计算一个score:score =q · k
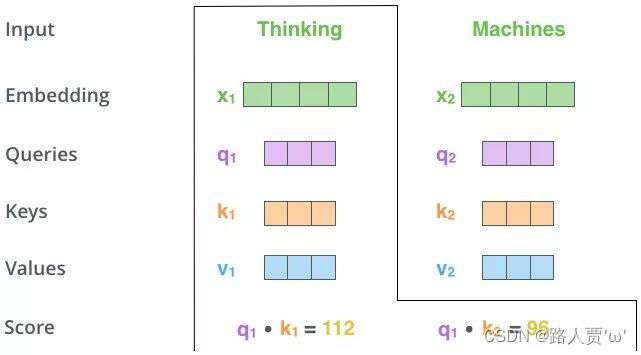
第3步:Scale+Softmax
将刚得到的相似度除以,再进行Softmax。经过Softmax的归一化后,每个值是一个大于0且小于1的权重系数,且总和为1,这个结果可以被理解成一个权重矩阵。
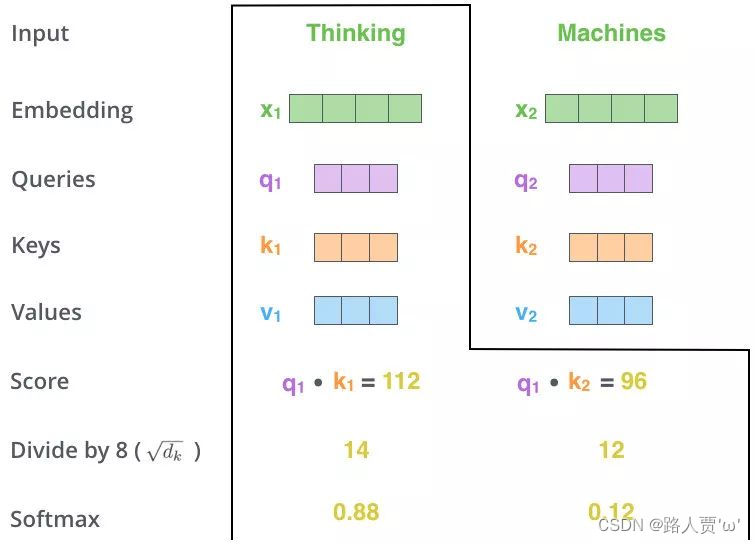
第4步:Matmul
使用刚得到的权重矩阵,与V相乘,计算加权求和。

以上是对Thinking Machines这句话进行自注意力的全过程,最终得到z1和z2两个新向量。
其中z1表示的是thinking这个词向量的新的向量表示(通过thinking这个词向量,去查询和thinking machine这句话里面每个单词和thinking之间的相似度)。
也就是说新的z1依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息。
2.3 自注意力机制的问题
自注意力机制的原理是筛选重要信息,过滤不重要信息,这就导致其有效信息的抓取能力会比CNN小一些。这是因为自注意力机制相比CNN,无法利用图像本身具有的尺度,平移不变性,以及图像的特征局部性(图片上相邻的区域有相似的特征,即同一物体的信息往往都集中在局部)这些先验知识,只能通过大量数据进行学习。这就导致自注意力机制只有在大数据的基础上才能有效地建立准确的全局关系,而在小数据的情况下,其效果不如CNN。
另外,自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。在实际的文字处理问题中,可能在不同位置词语具有不同的性质,比如动词往往较低频率出现在句首。
要唠这个这就唠到位置编码(Positional Encoding) 了,这个我们下篇论文里面再讲,先大致说一下吧:对每一个输入向量加上一个位置向量e,位置向量的生成方式有多种,通过e来表示位置信息带入self-attention层进行计算。
具体原理吧,感兴趣的话可以看一下:
[2003.09229] Learning to Encode Position for Transformer with Continuous Dynamical Model (arxiv.org)
🌟三、多头注意力机制:Multi-Head Self-Attention
通过刚才的学习,我们了解到自注意力机制的缺陷就是,模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,有效信息抓取能力就差一些。 因此就有大佬提出了通过多头注意力机制来解决这一问题。这个也是实际中用的比较多的。
3.1 什么是多头注意力机制?
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组(一般h=8)不同的线性投影(linear projections)来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention)。

3.2 如何运用多头注意力机制?
第1步:定义多组W,生成多组Q、K、V
刚才我们已经理解了,Q、K、V是输入向量X分别乘上三个系数 , ,分别相乘得到的,
, ,是可训练的参数矩阵。
现在,对于同样的输入X,我们定义多组不同的 , , ,比如
、
、
,
、
、
每组分别计算生成不同的Q、K、V,最后学习到不同的参数。
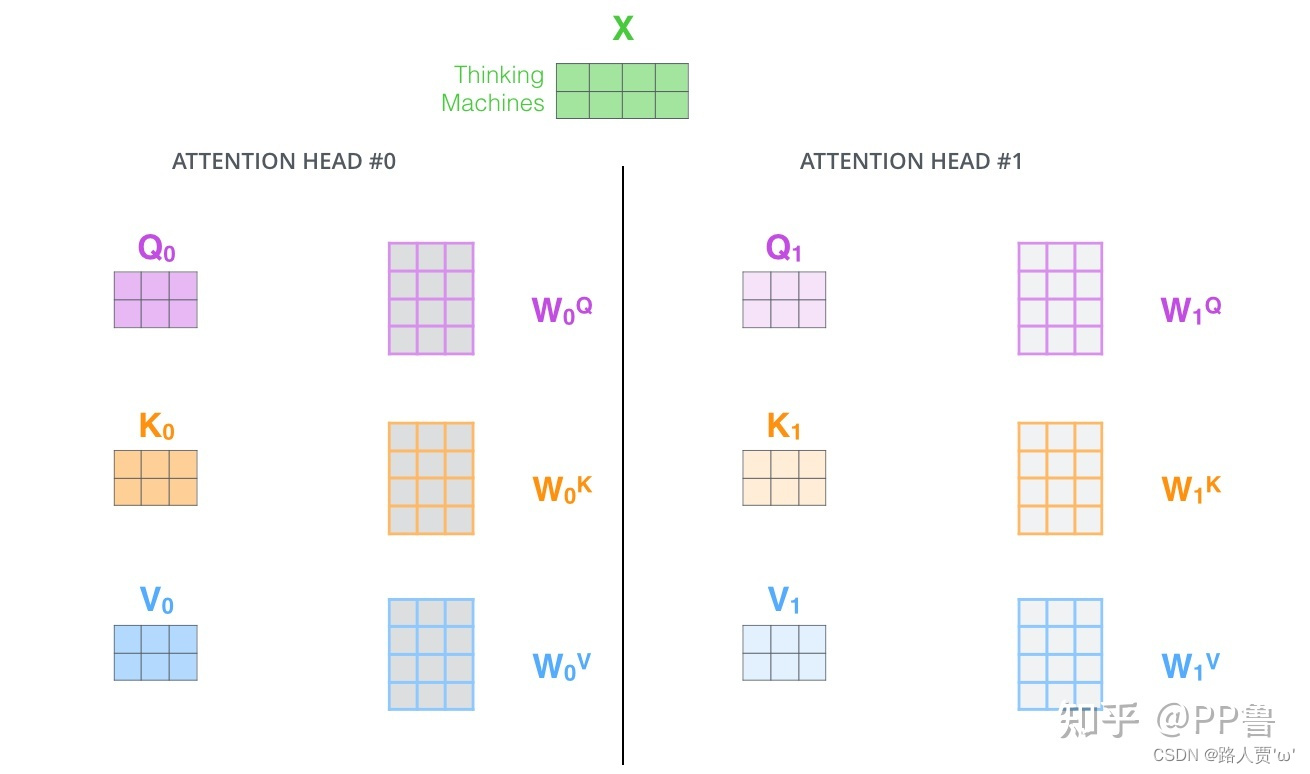
第2步:定义8组参数
对应8个single head,对应8组 , , ,再分别进行self-attention,就得到了
-
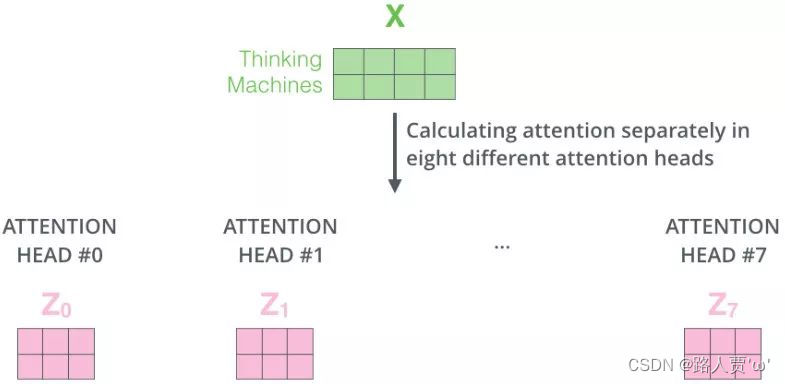
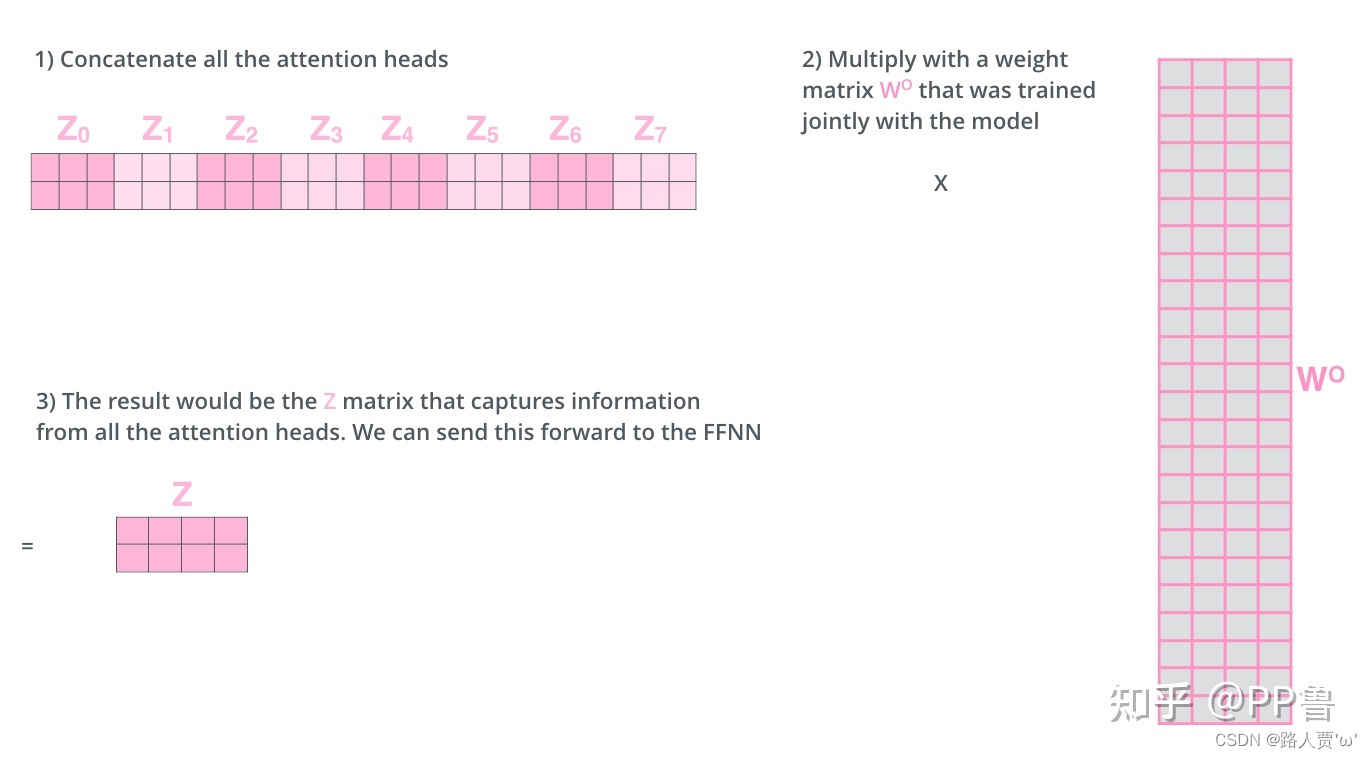
第3步:将多组输出拼接后乘以矩阵以降低维度
首先在输出到下一层前,我们需要将-
concat到一起,乘以矩阵
做一次线性变换降维,得到Z。
完整流程图如下:(感谢翻译的大佬!)
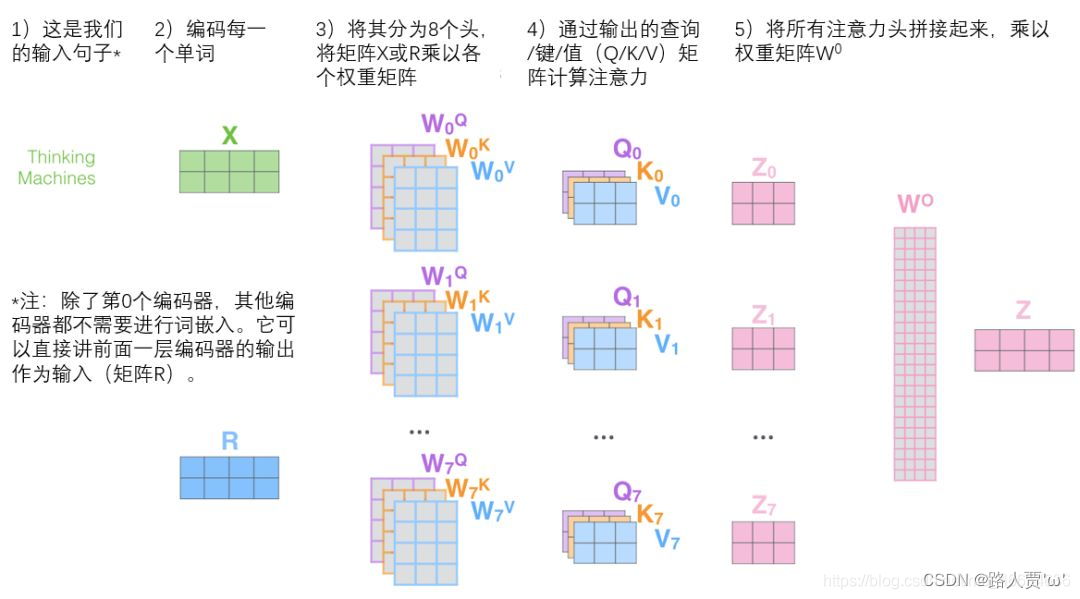
【注意】对于上图中的第2)步,当前为第一层时,直接对输入词进行编码,生成词向量X;当前为后续层时,直接使用上一层输出。
🌟四、通道注意力机制:Channel Attention
(恭喜你已经翻越了3座大山看到这里 (๑•̀ㅂ•́)و✧)
4.1 什么是通道注意力机制?
对于输入2维图像的CNN来说,一个维度是图像的尺度空间,即长宽,另一个维度就是通道,因此通道注意力机制也是很常用的机制。通道注意力旨在显示的建模出不同通道之间的相关性,通过网络学习的方式来自动获取到每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而来强化重要的特征抑制非重要的特征。
使用通道注意力机制的目的:为了让输入的图像更有意义,大概理解就是,通过网络计算出输入图像各个通道的重要性(权重),也就是哪些通道包含关键信息就多加关注,少关注没什么重要信息的通道,从而达到提高特征表示能力的目的。
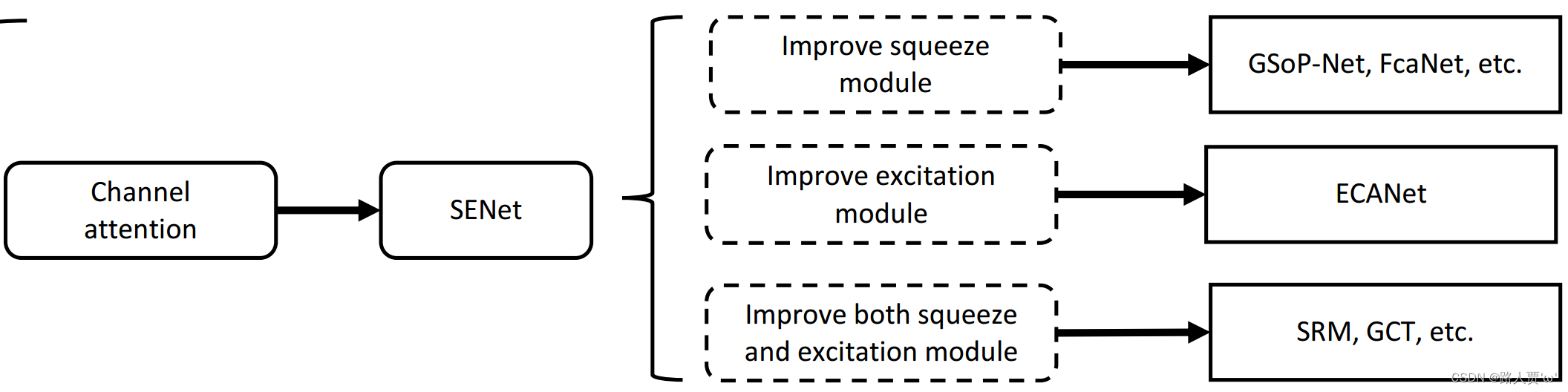
咦,我们好像看到了一个老朋友——SENet! ╰(*°▽°*)╯
4.2 SENet
SE注意力机制(Squeeze-and-Excitation Networks)在通道维度增加注意力机制,关键操作是squeeze和excitation。
通过自动学习的方式,即使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,然后用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
如下图所示,在输入SE注意力机制之前(左侧白图C2),特征图的每个通道的重要程度都是一样的,通过SENet之后(右侧彩图C2),不同颜色代表不同的权重,使每个特征通道的重要性变得不一样了,使神经网络重点关注某些权重值大的通道。
这里就简单回顾一下~
更详细的了解请看我的这两篇:
经典神经网络论文超详细解读(七)——SENet(注意力机制)学习笔记(翻译+精读+代码复现) SENet代码复现+超详细注释(PyTorch)
4.3 其他通道注意力机制
① ECA
ECA 注意力机制,它是一种通道注意力机制;常常被应用与视觉模型中。支持即插即用,即:它能对输入特征图进行通道特征加强,而且最终ECA模块输出,不改变输入特征图的大小。
- 背景:ECA-Net认为:SENet中采用的降维操作会对通道注意力的预测产生负面影响;同时获取所有通道的依赖关系是低效的,而且不必要的;
- 设计:ECA在SE模块的基础上,把SE中使用全连接层FC学习通道注意信息,改为1*1卷积学习通道注意信息;
- 作用:使用1*1卷积捕获不同通道之间的信息,避免在学习通道注意力信息时,通道维度减缩;降低参数量;(FC具有较大参数量;1*1卷积只有较小的参数量)

② CBAM
CBAM全称Convolutional Block Attention Module,这是一种用于前馈卷积神经网络的简单而有效的注意模块。是传统的通道注意力机制+空间注意力机制,是 channel(通道) + spatial(空间) 的统一。即对两个Attention进行串联,channel 在前,spatial在后。
给定一个中间特征图,我们的模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征修饰。 由于CBAM是轻量级的通用模块,因此可以以可忽略的开销将其无缝集成到任何CNN架构中,并且可以与基础CNN一起进行端到端训练。

🌟五、空间注意力机制:Spatial Attention
5.1 什么是空间注意力机制?
其实上面那个图就包含空间注意力机制了:绿色长条的是通道注意力机制,而紫色平面则就是空间注意力机制。
不是图像中所有的区域对任务的贡献都是同样重要的,只有任务相关的区域才是需要关心的,比如分类任务的主体,空间注意力模型就是寻找网络中最重要的部位进行处理。空间注意力旨在提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。
5.2 STN
STN《Spatial Transformer Networks》是15年NIPS上的文章STN引入了一个新的可学习的空间转换模块,提出了空间变换器(Spatial Transformer)的概念,它可以使模型具有空间不变性。这个可微分模块可以插入到现有的卷积结构中,使神经网络能够在Feature Map本身的条件下自动地对特征进行空间变换,而无需任何额外的训练监督或优化过程的修改。主要作用是找到图片中需要被关注的区域,并对其旋转、缩放,提取出固定大小的区域。
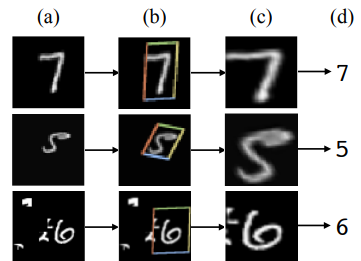
空间采样器的实现主要分成三个部分:
- 1)局部网络(Localisation Network)
- 2)参数化网格采样( Parameterised Sampling Grid)
- 3)差分图像采样(Differentiable Image Sampling)
总结
以上就是我们这篇要介绍的注意力机制,目前所有的注意力机制方法大都是基于各个不同的维度利用有限的资源进行信息的充分利用,它本质作用是增强重要特征,抑制非重要特征。注意力机制非常重要,在CV领域可以说是遍地开花,被广泛应用在网络中提升模型精度,本文也只是简单的介绍了一下,为下一篇论文阅读扫清障碍。以后应用于代码之中再详细介绍吧!
本文参考:
一文看尽深度学习中的各种注意力机制 - 知乎 (zhihu.com)
注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制 - 知乎 (zhihu.com)




















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











