







决策树预测算法以及模型的联结
- 针对分类问题,叶子节点给出的数据属于每个类别的概率,而这个概率值等于各个类别的数据占比。假设数据分为K类,分别记为0,1,…,K-1,叶子节点上一共有N个数据,则P(y=i)=Σj1{yj=i}/N。基于预测得到的概率,就可以很直接地得到最终的预测结果为出现概率最大的类别。
- 针对回归问题,叶子节点的处理方式类似,最终的预测结果等于节点内标签变量{yi}的平均值。
模型的联结
仔细分析决策树可以得到,这个模型的优点在于能综合考虑多个变量,对变量的线性转换是稳定的。另外,它对连续性变量的处理方法是将其划分成几个互不相交的区间,这样的处理方法能有效地规避定量变量边际效应恒定的隐含假设。但模型的最后一步算法比较薄弱,只是简单地求类别占比或者平均值。这实际导致单独使用决策树搭建模型时,预测效果并不理想(实际建模时,很少单独使用决策树模型)。
实际应用中,为了得到更好的预测效果,需要借助模型联结主义:将决策树作为整体模型的一部分和其他模型嵌套使用。
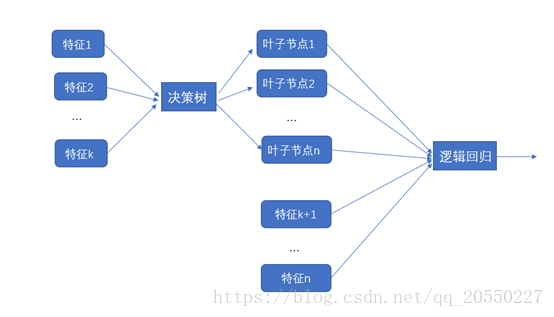
如下图所示,将决策树视为一种特征提取的模型,首先使用它对某些原始特征(一般为数值型特征)做聚类运算,将数据位于决策树的哪个叶子节点作为新特征。比如假设决策树有4个节点,依次命名为1,2,3,4;某个数据落在第3个叶子节点,则用向量(0,1,0,0)来表示这个数据。如何利用这些新特征和剩下的原始特征搭建逻辑回归模型,由此得到最终的预测结果。














 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









