







一、缓存概述
1、基本概念
1. Cache(缓存): 从cpu的一级和二级缓存、Internet的DNS、到浏览器缓存都可以看做是一种缓存。
维基百科: 写道
a store of things that will be required in the future, and can be retrieved rapidly.
(存贮数据(使用频繁的数据)的临时地方,因为取原始数据的代价太大了,所以我可以取得快一些)

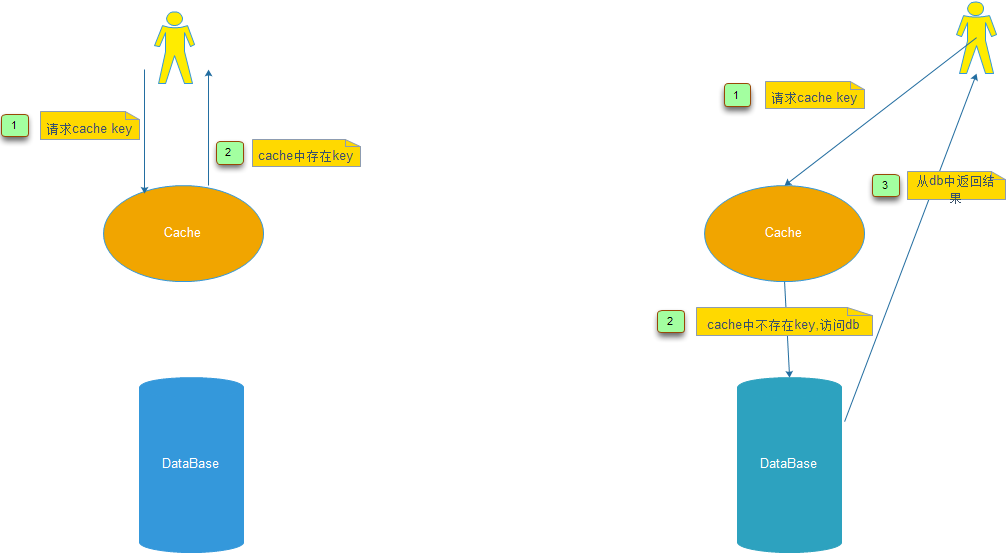
2. Cache hit(缓存命中)(下图左)
When a data element is requested from cache and the elements exists for the given key.
3. Cahe miss(缓存未命中): 与Cache hit相反(下图右)
4. 缓存算法:缓存容量超过预设,如何踢掉“无用”的数据。
例如:LRU(Least Recently Used) FIFO(First Input First Output)Least Frequently Used(LFU) 等等
5. System-of-Record(真实数据源): 例如关系型数据库、其他持久性系统等等。
也有英文书叫做authority data(权威数据)
6. serialization-and-deserialization(序列化与反序列化):可以参考:序列化与反序列化(美团工程师写的,非常棒的文章)
后面也有单独文章去分析。

6. Scale Up (垂直扩容) 和 Scale out (水平扩容)
驴拉车,通常不是把一头驴养壮(有极限),而通常是一群驴去拉(当然每个个体也不能太差)。

服务器也是一样的道理,至少互联网是这样:

7. Write-through 和 write-behind


8.阿姆而达定律:用于计算缓存加速比
2、缓存的种类或者类型
1. LocalCache(独立式): 例如Ehcache、BigMemory Go
(1) 缓存和应用在一个JVM中。
(2) 缓存间是不通信的,独立的。
(3) 弱一致性。

2. Standalone(单机):
(1) 缓存和应用是独立部署的。
(2) 缓存可以是单台。(例如memcache/redis单机等等)
(3) 强一致性
(4) 无高可用、无分布式。
(5) 跨进程、跨网络

3. Distributed(分布式):例如Redis-Cluster, memcache集群等等
(1) 缓存和应用是独立部署的。
(2) 多个实例。(例如memcache/redis等等)
(3) 强一致性或者最终一致性
(4) 支持Scale Out、高可用。
(5) 跨进程、跨网络

4. Replicated(复制式): 缓存数据时同时存放在多个应用节点的,数据复制和失效的事件以同步或者异步的形式在各个集群节点间传播。(也是弱一致性)
这种用的不太多。
注意:数据层访问速度:(作为开发人员要记住这些量级)

二、缓存的几种更新策略
从下面的表格看,缓存的更新策略大致分为三种,本文将从一致性和维护成本两个方面对于三种缓存更新策略进行简要说明,因为这些东西比较理论和抽象,如哪里说得不对,欢迎拍砖。
注:
(1) 一致性:缓存和真实数据源(例如mysql, hbase, elasticsearch等等)是否存在一段时间数据的不一致。
(2) 维护成本: 开发人员的开发和维护成本。
| 策略 | 一致性 | 维护成本 |
| LRU/LIRS/FIFO算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
2.1、LRU/LFU/FIFO算法剔除
1. 使用场景:
通常用于缓存使用量超过了预设的最大值时候(缓存空间不够),如何对现有的数据进行清理。例如FIFO会把最新进入缓存的数据清理出去, LRU会把最近最少使用的数据清理掉。
例如:Memcache使用的是LRU,具体Memcache如何实现的,这里就不在赘述了,网上资料多的是。
例如:Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的更新策略。
| 配置名 | 含义 | 默认值 |
| maxmemory | 最大可用内存 | 不使用该配置,也就对内存使用无限制 |
| maxmemory-policy | 内存不够时,淘汰策略 | volatile-lru |
- volatile-lru -> 用lru算法删除过期的键值
- allkeys-lru -> 用lru算法删除所有键值
- volatile-random -> 随机删除过期的键值
- allkeys-random -> 随机删除任何键值
- volatile-ttl -> 删除最近要到期的键值
- noeviction -> 不删除键,只返回一个错误
2. 常用算法:
这里不再赘述,常用的算法有如下几种:
FIFO[first in first out]
LFU[Less Frequently Used]
LRU[Least Recently used]
3. 一致性
可以想象,要清理哪些数据,不是由开发者决定(只能决定大致方向:策略算法),数据的一致性是最差的。
4. 维护成本
这些算法不需要开发者自己来实现,通常只需要配置最大maxmemory和对应的策略即可。
开发者只需要有这个东西,知道是什么意思,选择自己需要的算法,算法的实现是由缓存服务器实现的。
2.2、超时剔除
1. 使用场景:
就是我们通常做的缓存数据过期时间设置,例如redis和memcache都提供了expire这样的API,来设置K-V的过期时间。
一般来说业务可以容忍一段时间内(例如一个小时),缓存数据和真实数据(例如:mysql, hbase等等)数据不一致(一般来说,缓存可以提高访问速度降低后端负载),那么我们可以对一个数据设置一定时间的过期时间,在数据过期后,再从真实数据源获取数据,重新放到缓存中,继续设置过期时间。
例如: 一个视频的描述信息,我们可以容忍一个小时内数据不一致,但是涉及到钱的方面,如果不一致可想而知。
2. 一致性:
一段时间内(取决于过期时间)存在数据一致性问题,即缓存数据和真实数据源数据不一致。
3. 维护成本
用户的维护成本不是很高,只需要设置expire过期时间即可(前提是你的业务允许这段时间可能发生的数据不一致)。
2.3、主动更新
1. 使用背景:
业务对于数据的一致性要求很高,需要在真实数据更新后,立即更新缓存数据。
具体做法:例如可以利用消息系统或者其他方式(比如数据库触发器,或者其他数据源的listener机制来完成)通知缓存更新。
2. 一致性:
可以想象一致性最高(几乎接近强一致),但是有个问题:如果主动更新发生了问题,那么这条数据很可能很长时间不会更新了(所以可以结合超时剔除一起使用,下面最佳实践会说到)
3. 维护成本:
相当高,用户需要自己来完成更新(需要一定量的代码,从某种程度上加大了系统的复杂性),需要自己检查数据是否真的更新了之类的工作。
2.4、最佳实践
其实最佳实践就是组合使用:
1. 一般来说我们都需要配置超过最大缓存后的更新策略(例如:LRU)以及最大内存,这样可以保证系统可以继续运行(例如redis可能存在OOM问题)(极端情况下除外,数据一致性要求极高)。
2. 一般来说我们需要把超时剔除和主动更新组合使用,那样即使主动更新出了问题,也能保证过期时间后,缓存就被清除了(不至于永远都是脏数据)。
三、什么是缓存粒度
下面这个图是很多项目关于缓存使用最常用的一个抽象,那么我们假设storage层为mysql, cache层为redis。

假如我现在需要对视频的信息做一个缓存,也就是需要对select * from video where id=?的每个id在redis里做一份缓存,这样cache层就可以帮助我抗住很多的访问量(注:这里不讨论一致性和架构等等问题,只讨论缓存的粒度问题)。
我们假设视频表有100个属性(这个真有,有些人可能难以想象),那么问题来了,需要缓存什么维度呢,也就是有两种选择吧:
Java代码
- (1)cache(id)=select * from video where id=#id
- (2)cache(id)=select importantColumn1, importantColumn2 .. importantColumnN from video where id=#id
其实这个问题就是缓存粒度问题,我们在缓存设计应该考虑颗粒度呢?下面我们将从通用性、空间、代码维护三个角度进行说明。
3.1、全部数据和部分数据比较
1. 两者的特点是显而易见的:
| 数据类型 | 通用性 | 空间占用(内存空间 + 网络码率) | 代码维护 |
| 全部数据 | 高 | 大 | 简单 |
| 部分数据 | 低 | 小
| 较为复杂 |
2. 通用性:
如果单从通用性上看,全部数据是最优秀的,但是有个问题就是是否有必要缓存全部数据,认为以后会有这样的需求,但是从经验看除了非常重要的信息,那些不重要的字段基本不会在需求里出现,也就是说这种通用性 通常都是想象出来的。太多人觉得通用性是最重要的。vid拿一些基本信息,会想专辑明星。。要不要用通用性高的,于是加了全局的,通用性很重要,但是要想清楚。
3. 空间占用:
很显然,缓存全部数据,会占用大量的内存,有人会说,不就费一点内存吗,能有多少钱?而且已经有人习惯了把缓存当做下水道来使用,什么都框框的往里面放,但是我这里要说内存并不是免费的,可以说是很珍贵的资源。instagram21->4G的例子就说明了这个道理,好的程序员可以帮助公司节约大量的资源。
而且单个cache(id)也带来两个问题:序列化的开销和网络流量的开销(QPS,百倍),都是无容忽视的。
4. 代码维护:
代码维护性,全部数据的优势更加明显,而部分数据一旦要加新字段就会修改代码,而且还需要对原来的数据进行刷新。
注意:总结:
缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很多无用空间的浪费,可能会造成网络带宽的浪费,可能会造成代码通用性较差等情况,必须学会综合数据通用性、空间占用比、代码维护性 三点评估取舍因素权衡使用。
四、引出热点key问题
我们通常使用 缓存 + 过期时间的策略来帮助我们加速接口的访问速度,减少了后端负载,同时保证功能的更新,一般情况下这种模式已经基本满足要求了。
但是有两个问题如果同时出现,可能就会对系统造成致命的危害:
(1) 这个key是一个热点key(例如一个重要的新闻,一个热门的八卦新闻等等),所以这种key访问量可能非常大。
(2) 缓存的构建是需要一定时间的。(可能是一个复杂计算,例如复杂的sql、多次IO、多个依赖(各种接口)等等)
于是就会出现一个致命问题:在缓存失效的瞬间,有大量线程来构建缓存(见下图),造成后端负载加大,甚至可能会让系统崩溃 。

4.1、四种解决方案
我们的目标是:尽量少的线程构建缓存(甚至是一个) + 数据一致性 + 较少的潜在危险,下面会介绍四种方法来解决这个问题:
1. 使用互斥锁(mutex key): 这种解决方案思路比较简单,就是只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据就可以了(如下图)

如果是单机(standalone),可以用synchronized或者lock来处理,如果是分布式环境可以用分布式锁就可以了(分布式锁,可以用memcache的add, redis的setnx, zookeeper的添加节点操作)。
下面是Tim yang博客的代码,是memcache的伪代码实现
Java代码
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
} 如果换成redis,就是:
Java代码
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}
2. "提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。伪代码如下:
Java代码
v = memcache.get(key);
if (v == null) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
} else {
if (v.timeout <= now()) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
// extend the timeout for other threads
v.timeout += 3 * 60 * 1000;
memcache.set(key, v, KEY_TIMEOUT * 2);
// load the latest value from db
v = db.get(key);
v.timeout = KEY_TIMEOUT;
memcache.set(key, value, KEY_TIMEOUT * 2);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}
} 3. "永远不过期":
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期

从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
Java代码
- String get(final String key) {
- V v = redis.get(key);
- String value = v.getValue();
- long timeout = v.getTimeout();
- if (v.timeout <= System.currentTimeMillis()) {
- // 异步更新后台异常执行
- threadPool.execute(new Runnable() {
- public void run() {
- String keyMutex = "mutex:" + key;
- if (redis.setnx(keyMutex, "1")) {
- // 3 min timeout to avoid mutex holder crash
- redis.expire(keyMutex, 3 * 60);
- String dbValue = db.get(key);
- redis.set(key, dbValue);
- redis.delete(keyMutex);
- }
- }
- });
- }
- return value;
- }
4. 资源保护:
采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。

4.2、四种方案对比:
作为一个并发量较大的互联网应用,我们的目标有3个:
1. 加快用户访问速度,提高用户体验。
2. 降低后端负载,保证系统平稳。
3. 保证数据“尽可能”及时更新(要不要完全一致,取决于业务,而不是技术。)
所以第二节中提到的四种方法,可以做如下比较,还是那就话:没有最好,只有最合适。
| 解决方案 | 优点 | 缺点 |
| 简单分布式锁(Tim yang) | 1. 思路简单 2. 保证一致性 | 1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
| 加另外一个过期时间(Tim yang) | 1. 保证一致性 | 同上 |
| 不过期(本文) | 1. 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
| 资源隔离组件hystrix(本文) | 1. hystrix技术成熟,有效保证后端。 2. hystrix监控强大。
| 1. 部分访问存在降级策略。 |
4.3、总结
1. 热点key + 过期时间 + 复杂的构建缓存过程 => mutex key问题
2. 构建缓存一个线程做就可以了。
3. 四种解决方案:没有最佳只有最合适。
4.4、参考文献
(本文部分代码和图来自如下两篇博客)















 5284
5284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









