







python爬取B站关注列表
一、数据库的设计与操作
1、数据的分析
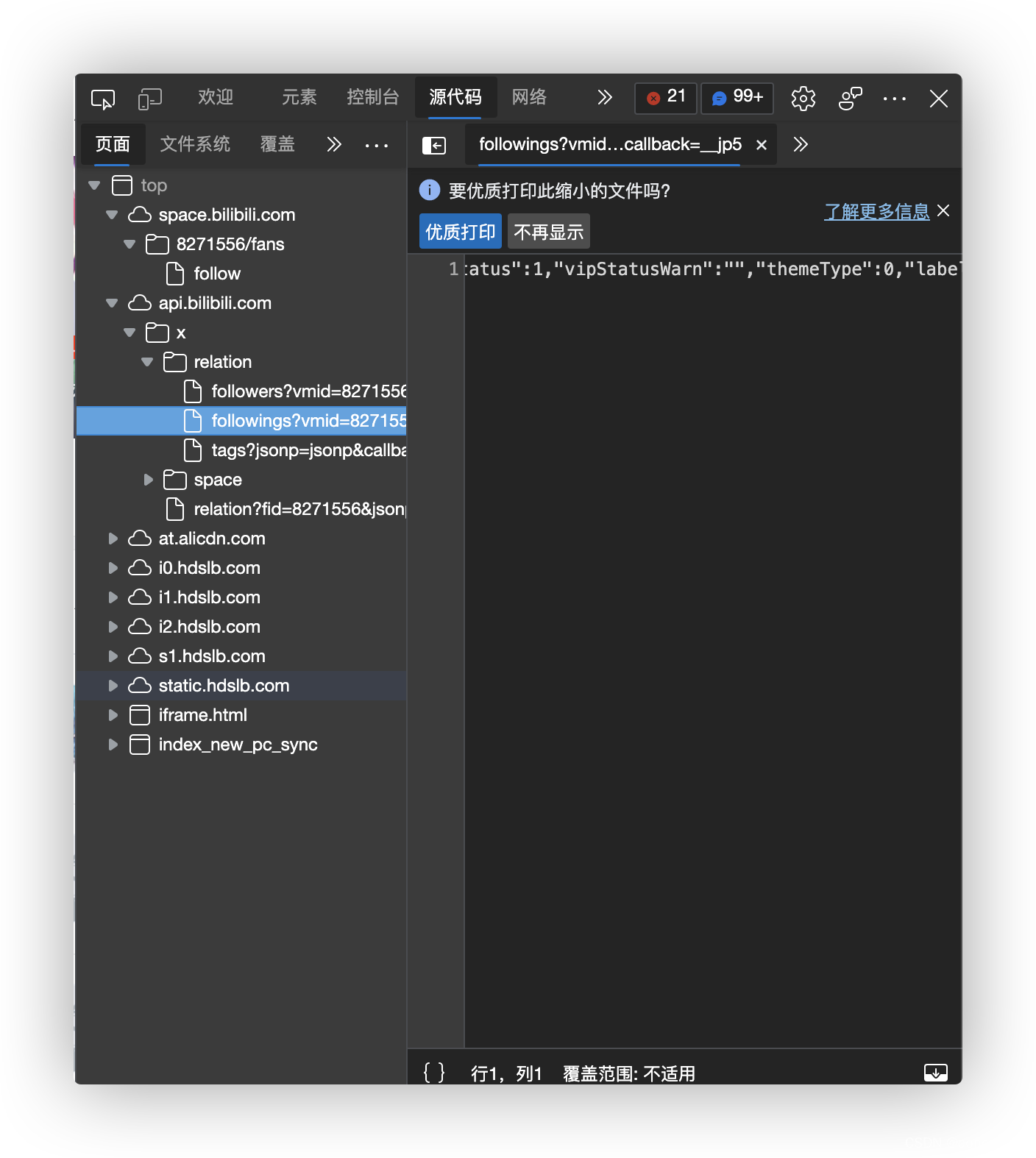
B站的关注列表在
https://api.bilibili.com/x/relation/followings?vmid=UID&pn=1&ps=50&order=desc&order_type=attention
中,一页最多50条信息。
我们大致分析一下信息,
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"list": [{……
首先,列表内容存在data:list里。
其次,对于列表中每一项,有如下信息
"mid": 672353429,
"attribute": 2,
"mtime": 1630510107,
"tag": null,
"special": 0,
"contract_info": {
"is_contractor": false,
"ts": 0,
"is_contract": false,
"user_attr": 0
},
"uname": "贝拉kira",
"face": "http://i2.hdslb.com/bfs/face/668af440f8a8065743d3fa79cfa8f017905d0065.jpg",
"sign": "元气满满的A-SOUL舞担参上~目标TOP IDOL,一起加油!",
"official_verify": {
"type": 0,
"desc": "虚拟偶像团体A-SOUL 所属艺人"
},
"vip": {
"vipType": 2,
"vipDueDate": 1674576000000,
"dueRemark": "",
"accessStatus": 0,
"vipStatus": 1,
"vipStatusWarn": "",
"themeType": 0,
"label": {
"path": "",
"text": "年度大会员",
"label_theme": "annual_vip",
"text_color": "#FFFFFF",
"bg_style": 1,
"bg_color": "#FB7299",
"border_color": ""
},
"avatar_subscript": 1,
"nickname_color": "#FB7299",
"avatar_subscript_url": "http://i0.hdslb.com/bfs/vip/icon_Certification_big_member_22_3x.png"
}
其中,mid为用户独一无二的UID,vipType,0是什么都没开,1是大会员,2是年度大会员,official_verify中,type 0代表官方认证,-1代表没有官方认证。
同时我们发现,如果对方锁了列表,会返回
{"code":-400,"message":"请求错误","ttl":1}
2、数据库设计
基于这些,我们先设计数据库,包含两张表,用户信息的基本属性表和关注的关系表。
def createDB():
link=sqlite3.connect('BiliFollowDB.db')
print("database open success")
UserTableDDL='''
create table if not exists user(
UID int PRIMARY KEY NOT NULL,
NAME varchar NOT NULL,
SIGN varchar DEFAULT NULL,
vipType int NOT NULL,
verifyType int NOT NULL,
verifyDesc varchar DEFAULT NULL)
'''
RelationTableDDL='''
create table if not exists relation(
follower int NOT NULL,
following int NOT NULL,
followTime int NOT NULL,
PRIMARY KEY (follower,following),
FOREIGN KEY(follower,following) REFERENCES user(UID,UID)
)
'''
# create user table
link.execute(UserTableDDL)
# create relation table
link.execute(RelationTableDDL)
print("database create success")
link.commit()
link.close()
3、数据库操作
其次是插入新用户的列表,我的思路是爬完一个人的关注列表,把一整个list丢给该函数,判断是否存在新增用户,存在则把新增用户传回,作为下一次爬虫的起点。
def insertUser(infos):
conn=sqlite3.connect('BiliFollowDB.db')
link=conn.cursor()
InsertCmd="insert into user (UID,NAME,vipType,verifyType,sign,verifyDesc) values (?,?,?,?,?,?);"
ExistCmd="select count(UID) from user where UID='%d';"# % UID
newID=[]
for info in infos:
answer=link.execute(ExistCmd%info['uid'])
for row in answer:
exist_ID=row[0]
if exist_ID==0:
newID.append(info['uid'])
link.execute(InsertCmd,(info['uid'],info['name'],info['vipType'],info['verifyType'],info['sign'],info['verifyDesc']))
conn.commit()
conn.close()
return newID
然后是插入关系的函数,这个比较简单
def insertFollowing(uid:int,subscribe):
conn=sqlite3.connect('BiliFollowDB.db')
link=conn.cursor()
InsertCmd="insert into relation (follower,following,followTime) values (?,?,?);"
for follow in subscribe:
link.execute(InsertCmd,(uid,follow[0],follow[1]))
conn.commit()
conn.close()
二、爬虫
通过观察,我们发现睿叔叔锁了5页的关注列表
即使是人工操作也只能访问5页,那没办法啦,我们就爬5页吧。
def getFollowingList(uid:int):
url="https://api.bilibili.com/x/relation/followings?vmid=%d&pn=%d&ps=50&order=desc&order_type=attention&jsonp=jsonp"# % (UID, Page Number)
infos=[]
subscribe=[]
for i in range(1,6):
html=requests.get(url%(uid,i))
if html.status_code!=200:
print("GET ERROR!")
text=html.text
dic=json.loads(text)
if dic['code']==-400:
break
list=dic['data']['list']
for usr in list:
info={}
info['uid']=usr['mid']
info['name']=usr['uname']
info['vipType']=usr['vip']['vipType']
info['verifyType']=usr['official_verify']['type']
info['sign']=usr['sign']
if info['verifyType']==-1:
info['verifyDesc']='NULL'
else :
info['verifyDesc']=usr['official_verify']['desc']
subscribe.append((usr['mid'],usr['mtime']))
infos.append(info)
newID=insertUser(infos)
insertFollowing(uid,subscribe)
return newID
三、完整代码
#by concyclics
# -*- coding:UTF-8 -*-
import sqlite3
import json
import requests
def createDB():
link=sqlite3.connect('BiliFollowDB.db')
print("database open success")
UserTableDDL='''
create table if not exists user(
UID int PRIMARY KEY NOT NULL,
NAME varchar NOT NULL,
SIGN varchar DEFAULT NULL,
vipType int NOT NULL,
verifyType int NOT NULL,
verifyDesc varchar DEFAULT NULL)
'''
RelationTableDDL='''
create table if not exists relation(
follower int NOT NULL,
following int NOT NULL,
followTime int NOT NULL,
PRIMARY KEY (follower,following),
FOREIGN KEY(follower,following) REFERENCES user(UID,UID)
)
'''
# create user table
link.execute(UserTableDDL)
# create relation table
link.execute(RelationTableDDL)
print("database create success")
link.commit()
link.close()
def insertUser(infos):
conn=sqlite3.connect('BiliFollowDB.db')
link=conn.cursor()
InsertCmd="insert into user (UID,NAME,vipType,verifyType,sign,verifyDesc) values (?,?,?,?,?,?);"
ExistCmd="select count(UID) from user where UID='%d';"# % UID
newID=[]
for info in infos:
answer=link.execute(ExistCmd%info['uid'])
for row in answer:
exist_ID=row[0]
if exist_ID==0:
newID.append(info['uid'])
link.execute(InsertCmd,(info['uid'],info['name'],info['vipType'],info['verifyType'],info['sign'],info['verifyDesc']))
conn.commit()
conn.close()
return newID
def insertFollowing(uid:int,subscribe):
conn=sqlite3.connect('BiliFollowDB.db')
link=conn.cursor()
InsertCmd="insert into relation (follower,following,followTime) values (?,?,?);"
for follow in subscribe:
try:
link.execute(InsertCmd,(uid,follow[0],follow[1]))
except:
print((uid,follow[0],follow[1]))
conn.commit()
conn.close()
def getFollowingList(uid:int):
url="https://api.bilibili.com/x/relation/followings?vmid=%d&pn=%d&ps=50&order=desc&order_type=attention&jsonp=jsonp"# % (UID, Page Number)
infos=[]
subscribe=[]
for i in range(1,6):
html=requests.get(url%(uid,i))
if html.status_code!=200:
print("GET ERROR!")
return []
text=html.text
dic=json.loads(text)
if dic['code']==-400:
return []
try:
list=dic['data']['list']
except:
return []
for usr in list:
info={}
info['uid']=usr['mid']
info['name']=usr['uname']
info['vipType']=usr['vip']['vipType']
info['verifyType']=usr['official_verify']['type']
info['sign']=usr['sign']
if info['verifyType']==-1:
info['verifyDesc']='NULL'
else :
info['verifyDesc']=usr['official_verify']['desc']
subscribe.append((usr['mid'],usr['mtime']))
infos.append(info)
newID=insertUser(infos)
insertFollowing(uid,subscribe)
return newID
def getFollowingUid(uid:int):
url="https://api.bilibili.com/x/relation/followings?vmid=%d&pn=%d&ps=50&order=desc&order_type=attention&jsonp=jsonp"# % (UID, Page Number)
for i in range(1,6):
html=requests.get(url%(uid,i))
if html.status_code!=200:
print("GET ERROR!")
return []
text=html.text
dic=json.loads(text)
if dic['code']==-400:
return []
try:
list=dic['data']['list']
except:
return []
IDs=[]
for usr in list:
IDs.append(usr['mid'])
return IDs
def work(root):
IDlist=root
tmplist=[]
while len(IDlist)!=0:
tmplist=[]
for ID in IDlist:
print(ID)
tmplist+=getFollowingList(ID)
IDlist=tmplist
def rework():
conn=sqlite3.connect('BiliFollowDB.db')
link=conn.cursor()
SelectCmd="select uid from user;"
answer=link.execute(SelectCmd)
IDs=[]
for row in answer:
IDs.append(row[0])
conn.commit()
conn.close()
newID=[]
print(IDs)
for ID in IDs:
ids=getFollowingUid(ID)
for id in ids:
if id not in IDs:
newID.append(id)
return newID
if __name__=="__main__":
createDB()
#work([**put root UID here**,])
四、项目仓库
如果您觉得有所收获的话,麻烦帮我点个小小的star


















 5410
5410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











