






简介:
由于B站要会员才能看的番,B站对其实施了反爬技术,对要会员才能看的番的视频和音频进行加密,根本找不其视频和音频的url。所以,暂时没办法爬取要会员才能看的番,但是可以爬取那些需要不需要会员的番。以下手把手教你一键爬取B站你需要的番:
演示:觉得有用就点赞和收藏吧
目录
(1)在网页里打开B站并选择你喜欢看的番,按F2或者ctrl+shift+i就会打开调试工具,找到网络或WIFI这个图标。此时你会发现网络比如:牧神记(哪一集都可以)
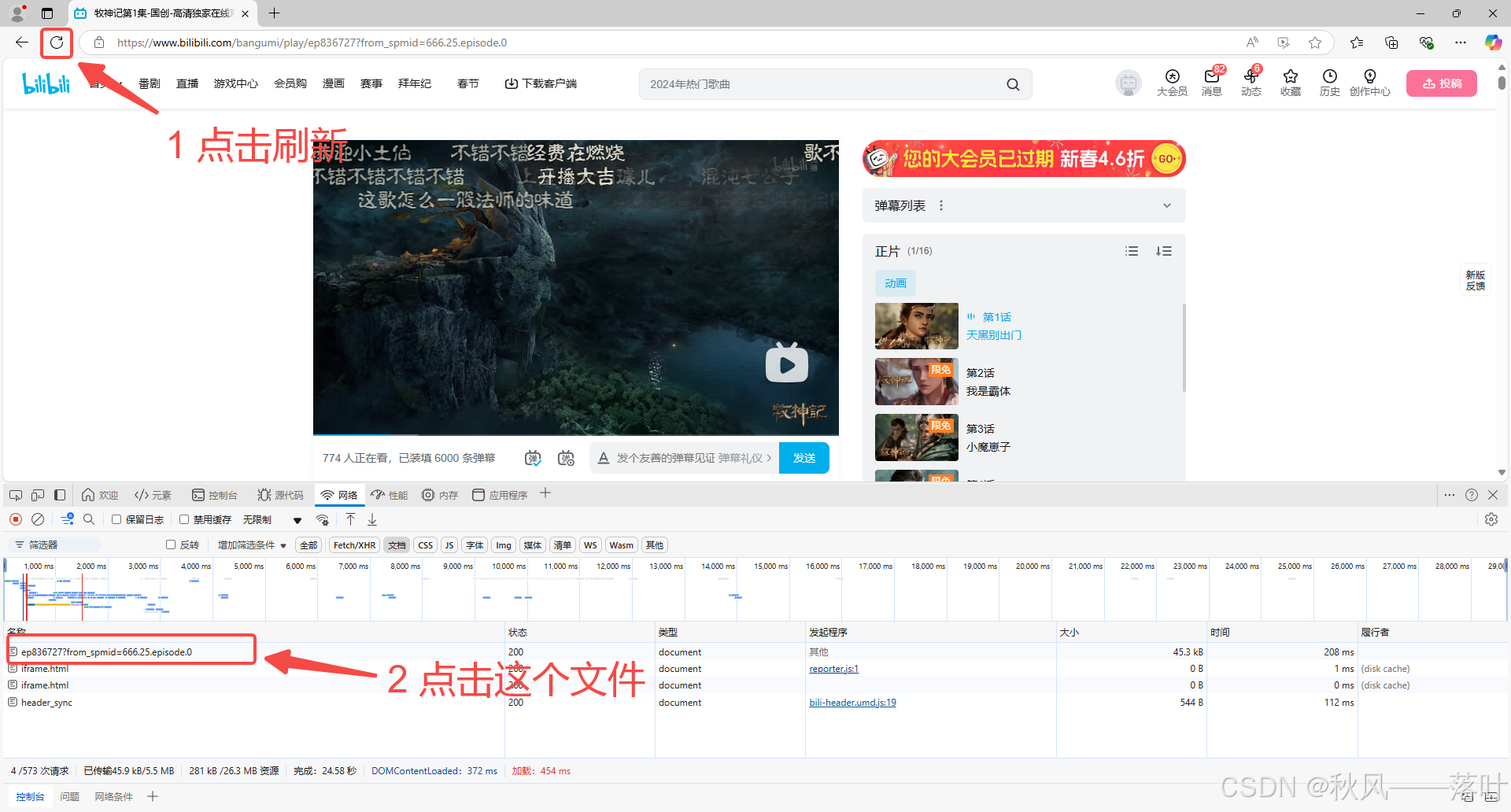
(2)点击浏览器左上角的刷新,点击下面那个ep开头的文件。你就会得到一些数据。下面那个文件就有我们想要的数据
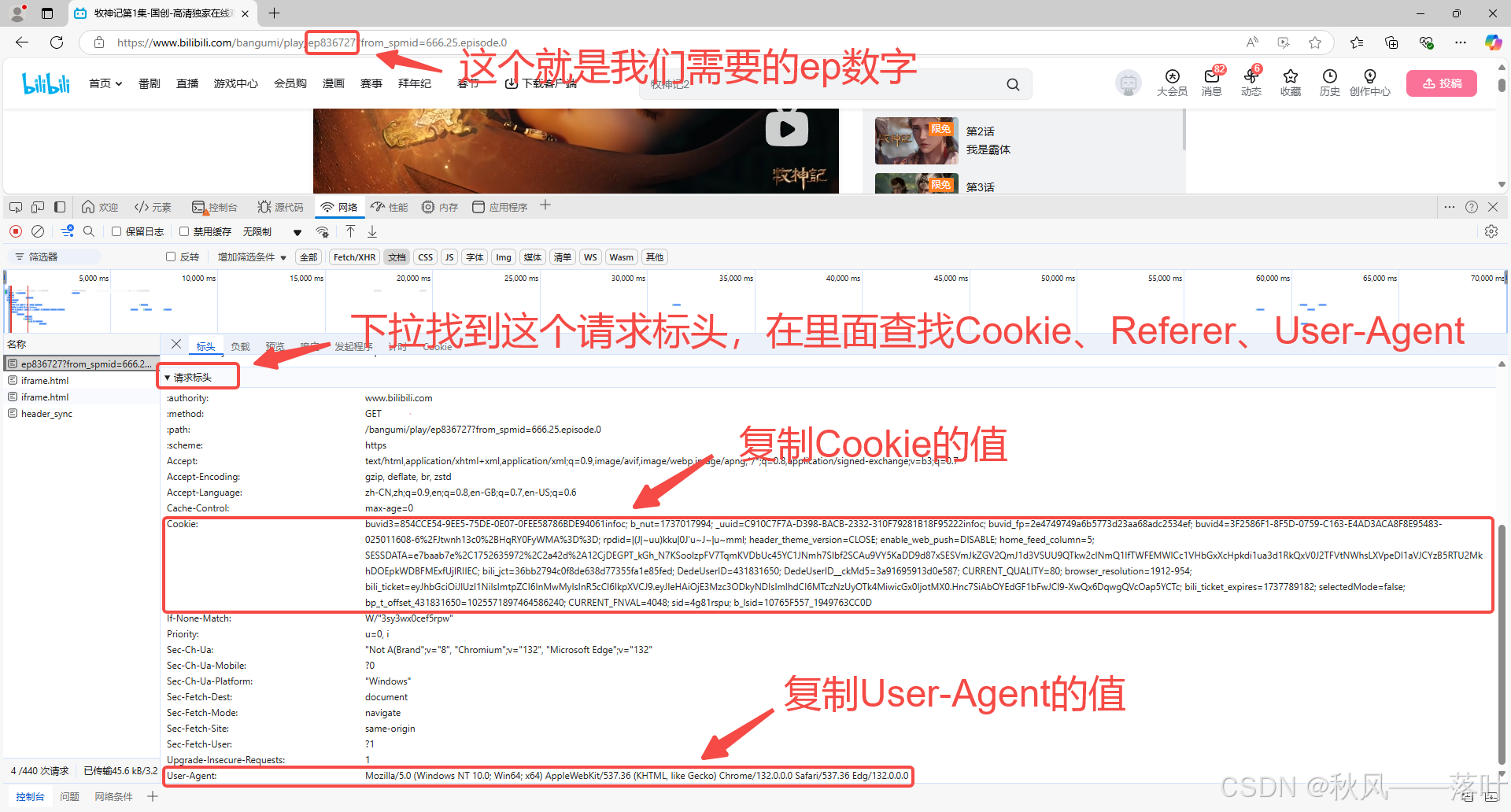
(3)复制以下几个数据,要修改的参数有Cookie、Referer和User-Agent,现在就差一个Referer没找到了
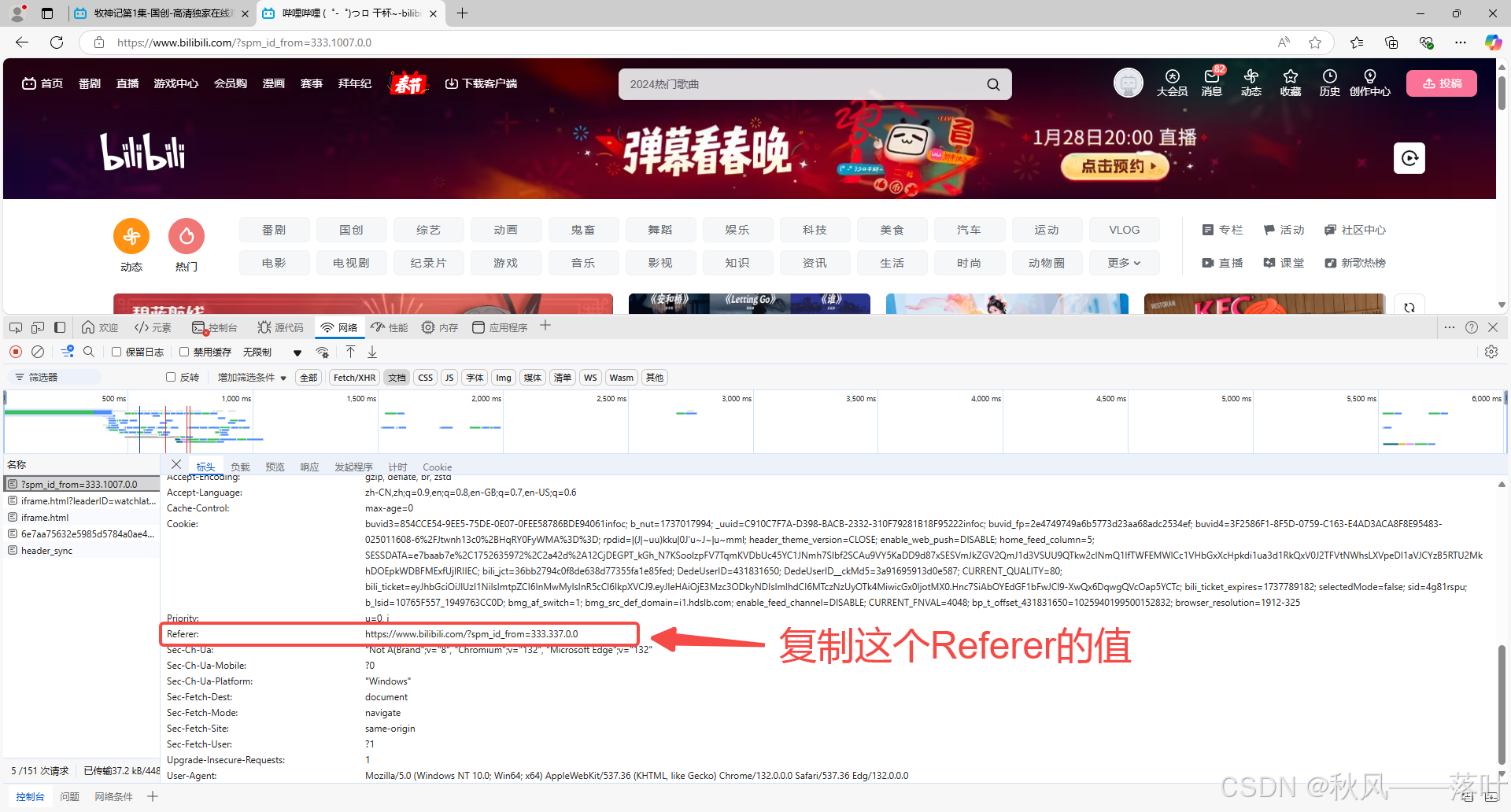
(4)你回到B站的首页再重复进行以上的(1)(2)(3)步骤,注意:点击哪个文件都没关系,只要有我们需要的Referer即可。这次我们只要拿Referer的值
爬虫
全套代码(在下方):安装配置ffmpeg后,只需要修改几个参数即可运行(headers里的三个参数Cookie、Referer、User-Agent),如需下载其他番,就是需要查一下该番的ep数字
注意:后面自动将视频和音频合并起来(需要安装个工具ffmpeg)
一、ffmpeg的安装配置
链接:保姆级教你安装ffmpeg和配置环境-CSDN博客
二、修改参数headers和查ep
注意:一定要登录账号才会能进行UA伪装
(1)在网页里打开B站并选择你喜欢看的番,按F2或者ctrl+shift+i就会打开调试工具,找到网络或WIFI这个图标。此时你会发现网络比如:牧神记(哪一集都可以)
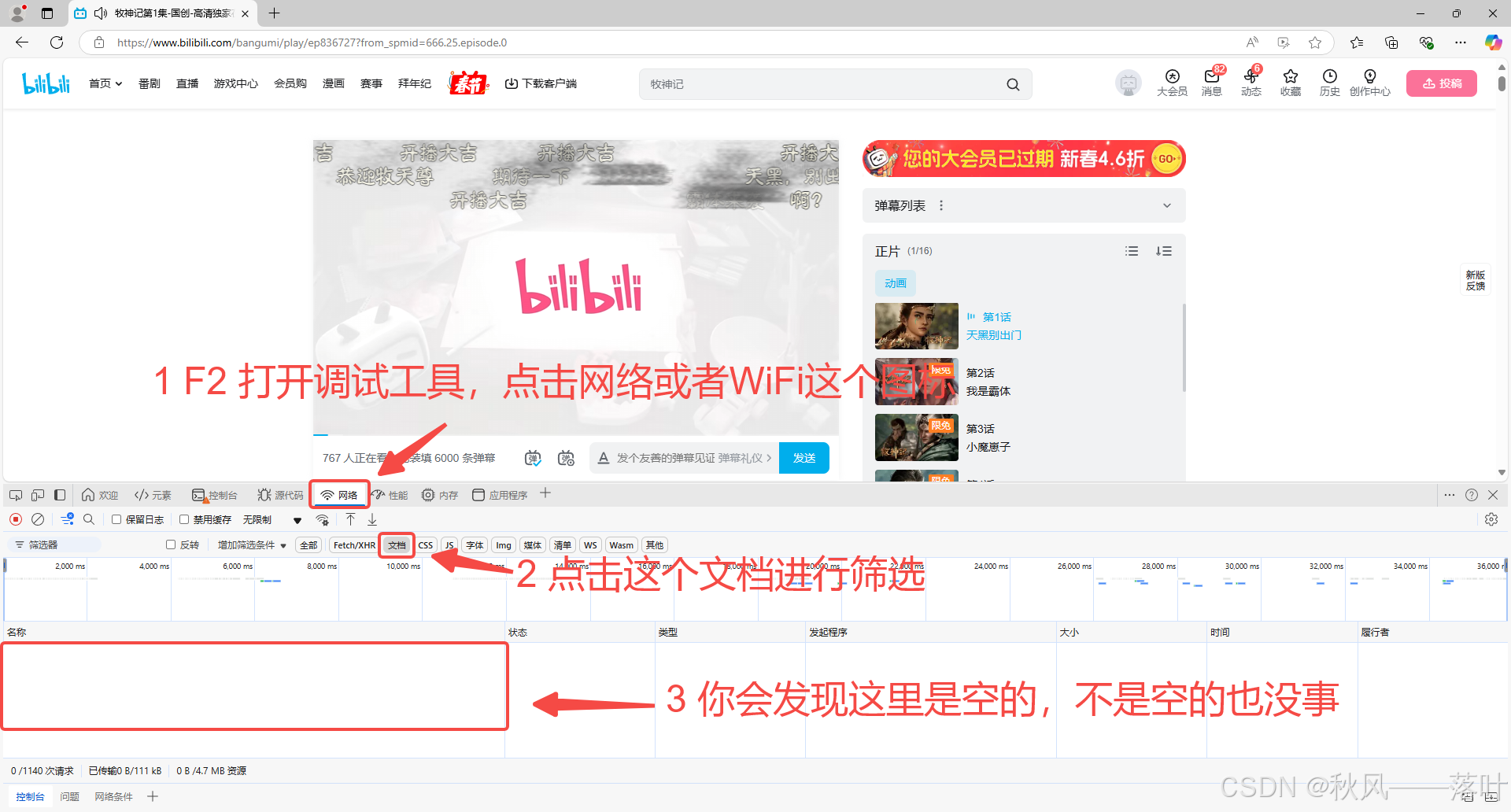
(2)点击浏览器左上角的刷新,点击下面那个ep开头的文件。你就会得到一些数据。下面那个文件就有我们想要的数据
(3)复制以下几个数据,要修改的参数有Cookie、Referer和User-Agent,现在就差一个Referer没找到了
(4)你回到B站的首页再重复进行以上的(1)(2)(3)步骤,注意:点击哪个文件都没关系,只要有我们需要的Referer即可。这次我们只要拿Referer的值
(5)回到代码里,去修改代码即可。
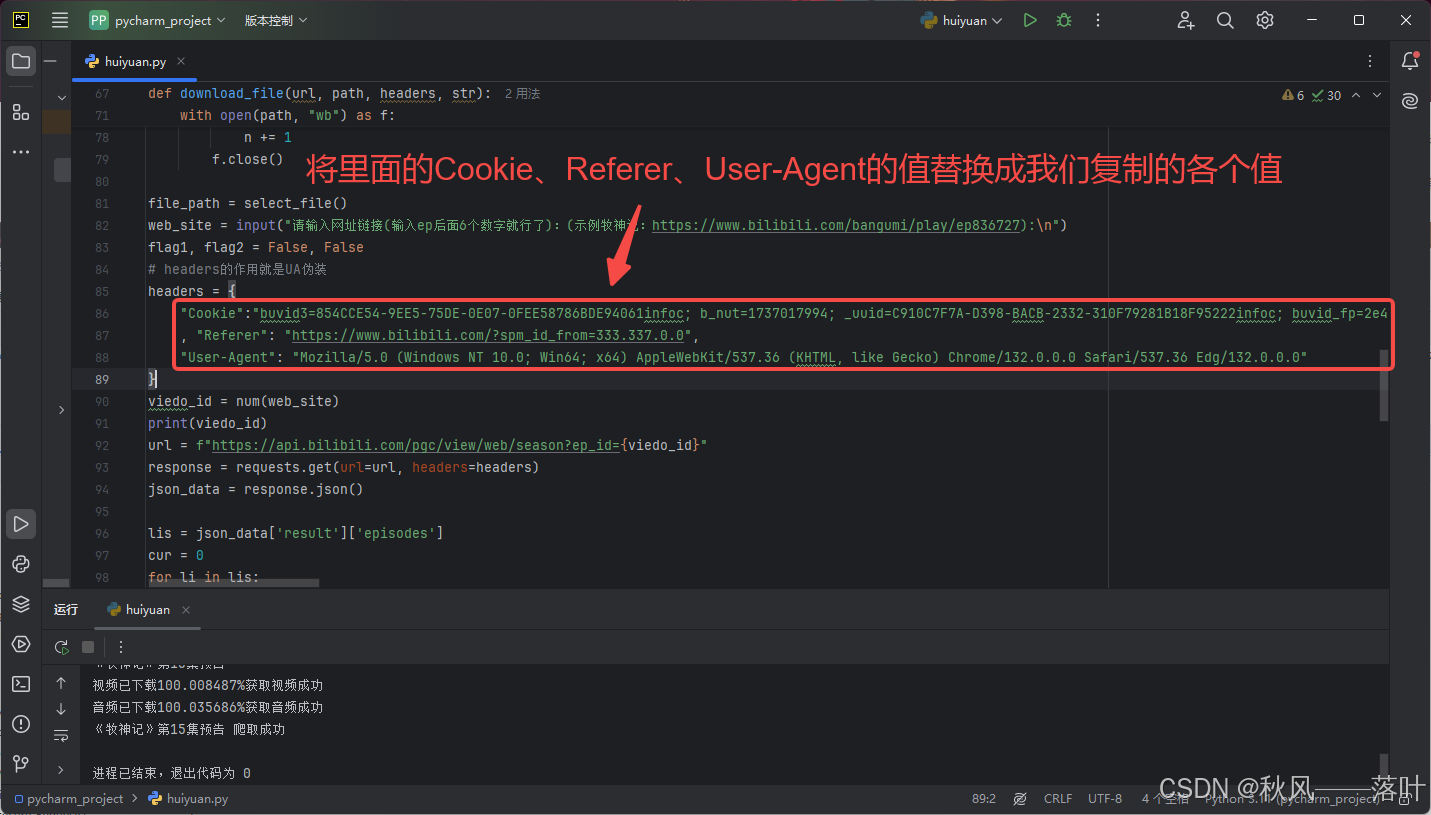
到这里,我们已经把参数修改成我们自己的参数了。现在代码可以运行了
三、运行程序
输入我们在前面查找的ep数字,并按回车(Enter)

接下来就会打印出对应番的各个数据,并提示你想要从第几集开始到第几集结束下载,输入你想要的数据并按回车。接下来坐等爬取完成即可
完整代码:
import subprocess
import os
import requests
import tkinter as tk
from tkinter import filedialog
from sys import stdout
# 选择你保存视频的文件路径
def select_file():
root = tk.Tk()
root.withdraw() # 隐藏主窗口
file_path = filedialog.askdirectory(title="选择保存的文件夹") # 会自动弹出文件选择对话框
print(file_path) # 打印选择的文件路径
return file_path
# 删除视频和音频
def delete_files(video_path, audio_path):
try:
# 删除视频文件
if os.path.exists(video_path):
os.remove(video_path)
else:
print(f"视频文件不存在:{video_path}")
# 删除音频文件
if os.path.exists(audio_path):
os.remove(audio_path)
else:
print(f"音频文件不存在:{audio_path}")
except Exception as e:
print(f"删除文件时发生错误:{e}")
# 将视频和音频合并起来
def combination():
process = subprocess.Popen(
[
'ffmpeg',
'-y', # 忽略已存在的输出文件,强制输出
'-i', f"{file_path}/{title}.mp4",
'-i', f"{file_path}/{title}audio.mp4",
'-c:v', 'copy', # 复制当前视频编码方式,速度最快
'-c:a', 'copy', # 复制当前音频编码方式,速度最快
'-strict', 'experimental',
'-shortest', # 截取视频、音频之间最短
f"{file_path}/{title}(完整).mp4"
],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
process.wait()
if process.returncode:
print(f"视频音频合成失败")
else:
pass
# print(title + "合并完成")
def num(u):
a = ''
for i in u:
if i >= '0' and i <= '9':
a += i
else:
if a != '':
a = ''
return a
def download_file(url, path, headers, str):
r = requests.get(url=url, headers=headers, stream=True)
chunk_size = 1024
content_size = int(r.headers['content-length'])
with open(path, "wb") as f:
n = 1
for chunl in r.iter_content(chunk_size=chunk_size):
loaded = n * 1024.0 / content_size
f.write(chunl)
stdout.write('\r' + str + '已下载{0:%}'.format(loaded))
stdout.flush()
n += 1
f.close()
file_path = select_file()
web_site = input("请输入网址链接(输入ep后面6个数字就行了):(示例牧神记:https://www.bilibili.com/bangumi/play/ep836727):\n")
flag1, flag2 = False, False
# headers的作用就是UA伪装
headers = {
"Cookie":"buvid3=854CCE54-9EE5-75DE-0E07-0FEE58786BDE94061infoc; b_nut=1737017994; _uuid=C910C7F7A-D398-BACB-2332-310F79281B18F95222infoc; buvid_fp=2e4749749a6b5773d23aa68adc2534ef; buvid4=3F2586F1-8F5D-0759-C163-E4AD3ACA8F8E95483-025011608-6%2FJtwnh13c0%2BHqRY0FyWMA%3D%3D; rpdid=|(J|~uu)kku|0J'u~J~|u~mml; header_theme_version=CLOSE; enable_web_push=DISABLE; home_feed_column=5; SESSDATA=e7baab7e%2C1752635972%2C2a42d%2A12CjDEGPT_kGh_N7KSoolzpFV7TqmKVDbUc45YC1JNmh7SIbf2SCAu9VY5KaDD9d87xSESVmJkZGV2QmJ1d3VSUU9QTkw2clNmQ1lfTWFEMWlCc1VHbGxXcHpkdi1ua3d1RkQxV0J2TFVtNWhsLXVpeDl1aVJCYzB5RTU2MkhDOEpkWDBFMExfUjlRIIEC; bili_jct=36bb2794c0f8de638d77355fa1e85fed; DedeUserID=431831650; DedeUserID__ckMd5=3a91695913d0e587; CURRENT_QUALITY=80; browser_resolution=1912-954; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3Mzc3ODkyNDIsImlhdCI6MTczNzUyOTk4MiwicGx0IjotMX0.Hnc7SiAbOYEdGF1bFwJCl9-XwQx6DqwgQVcOap5YCTc; bili_ticket_expires=1737789182; CURRENT_FNVAL=4048; selectedMode=false; bp_t_offset_431831650=1025571897464586240; b_lsid=C410423A8_19495DC2062; sid=f0djrh3d"
, "Referer": "https://www.bilibili.com/?spm_id_from=333.337.0.0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0"
}
viedo_id = num(web_site)
print(viedo_id)
url = f"https://api.bilibili.com/pgc/view/web/season?ep_id={viedo_id}"
response = requests.get(url=url, headers=headers)
json_data = response.json()
lis = json_data['result']['episodes']
cur = 0
for li in lis:
cur += 1
print(str(cur) + li['share_copy'] + ' ' + li['badge'])
start = int(input("从第几集开始:\n"))
end = int(input("到第几集结束:\n"))
cur = 0
for li in lis:
cur += 1
# 跳过你想要开始下载的集数之前的番
if cur < start:
continue
# 下载完你想下载的番的集数就停止下载了
if cur > end:
break
try:
aid = li['aid']
cid = li['cid']
ep_id = li['ep_id']
title = li['share_copy']
link = "https://api.bilibili.com/pgc/player/web/v2/playurl"
data = {
"support_multi_audio": "true",
"avid": aid,
"cid": cid,
"qn": "0",
"fnver": "0",
"fnval": "4048",
"fourk": "1",
"gaia_source": '',
"from_client": "BROWSER",
"ep_id": ep_id
}
print(title)
link_data = requests.get(params=data, url=link, headers=headers).json()
video_url = link_data["result"]['video_info']['dash']['video'][0]['baseUrl']
audio_url = link_data["result"]['video_info']['dash']['audio'][0]['baseUrl']
# print("获得url")
download_file(video_url, f"{file_path}/{title}.mp4", headers, '视频')
print("获取视频成功")
download_file(audio_url, f"{file_path}/{title}audio.mp4", headers, '音频')
print("获取音频成功")
combination() #将视频和音频组合起来
print(title + "爬取成功")
delete_files(f"{file_path}/{title}.mp4", f"{file_path}/{title}audio.mp4") #将没有组合的视频和音频删除
except Exception as e:
print(e)
恭喜你成功学会了爬取B站的番。快去试试吧

















 1480
1480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









