








今天要讲的文章是OSDI 2012年的一篇文章,PowerGraph:Distributed Graph-Parallel Computation on Natural Graphs。本文主要想解决的问题就是:现有的图数据,如社交网络、Web网页等都是一种Power-law幂律图的特征。所谓Power-law幂律图就是指在图数据中顶点的度数分配不均匀。有的图顶点的度数很高,有的顶点度数很低。并且顶点度数呈现着幂律分布的特征,对于这种Power-law的图数据,会存在很大的计算分配不均匀的特征。针对这个问题:PowerGraph分析了在幂律图的特征情况下,采用vertex-cut划分的策略。采用vertex-cut,切分成若干个Mirror顶点。利用Mirror顶点减少了高度顶点计算任务繁重的问题,并且采用vertex-cut划分策略产生很少一部分的Mirror。
1. Graphs are ubiquitous
我们都知道,图在我们生活中是无所不在的。

社交媒体、科学中分子结构关系、电商平台的广告推荐、网页信息。图是能够将人、产品、想法、事实、兴趣爱好之间的关系进行编码,转成一种结构进行存储。图的一个特点是:Big,数十亿的点和边以及丰富的元数据。各种场景下的信息都能转成图来表示,同时我们可以利用图来进行数据挖掘和机器学习,比如 ,识别出有影响力的人和信息、社区发现、寻找产品和广告的投放用户、给有依赖关系的复杂数据构建模型等等这些都可以使用图来完成。
2. Natural Graphs
从不同平台或实际应用中产生的图我们称为:Natural Graphs。面对各种应用中如此海量的Natural Graphs,现有分布式的图处理平台处理性能还是比较低效的。作者选用Twitter数据集测试目前几个主流分布式平台在处理这种Natural Graph的性能,这里是利用PageRank算法每次迭代的时间作为横轴,纵坐标是不同的分布式平台,可以看到Hadoop和原生态的GraphLab的处理时间还是很长的,性能最好的是Piccolo,这里举一个明星效应的例子,比如这里表示社交网络中的一个子图,中间红色点表示某个用户,旁边黑点表示的是所有的粉丝,比如这里我们一个黑点表示100w的用户,那么这个人可能就是obama,但像obama这样拥有这么多粉丝的人是非常少的,大部分人粉丝只有大黑点中的一个点,几百或者多者上千。这就是我们说的密率度分布图的特点。它是Google的Pregel的C++实现 。
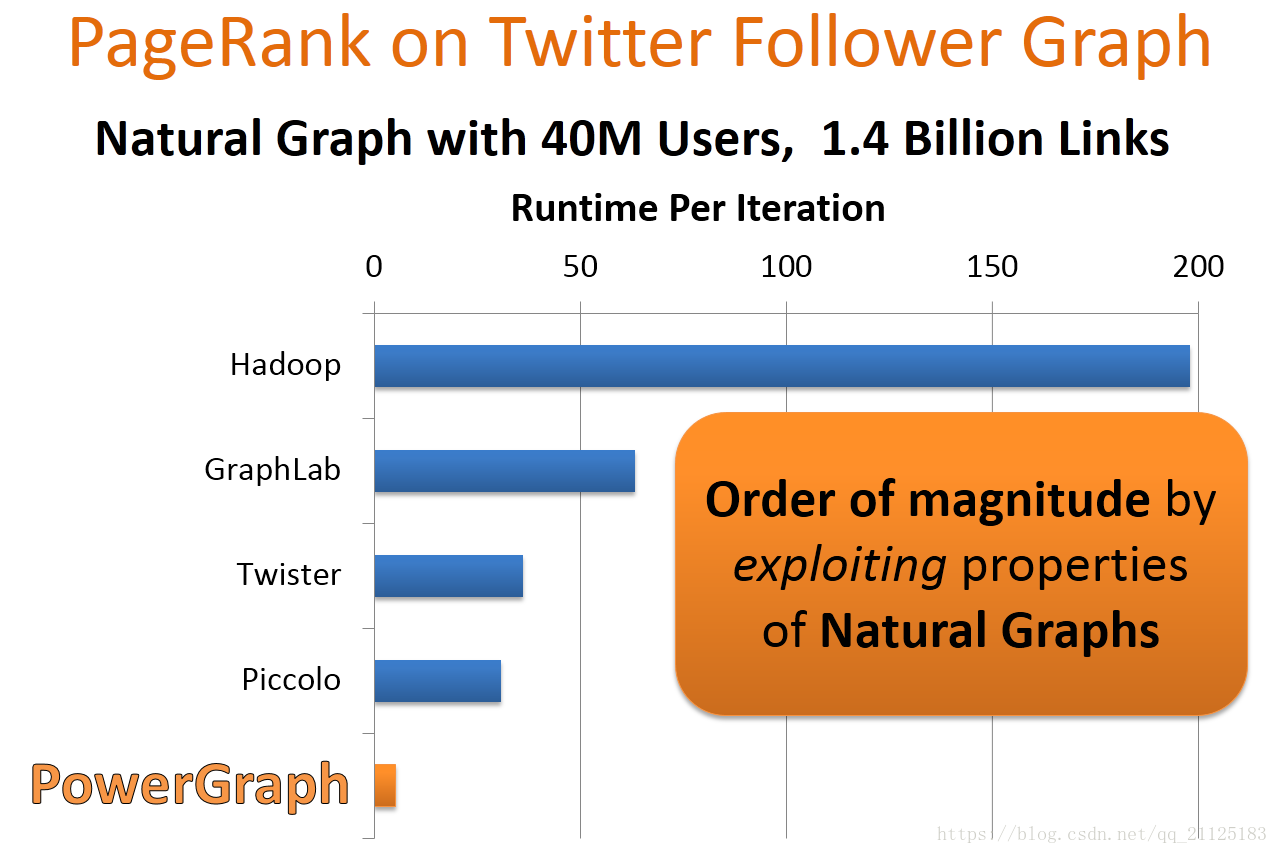
现有的分布式图处理系统在自然图中的处理性能都很差。这是为什么会造成这个原因呢?下面我们来看一下自然图到底有什么特征。
2.1 Power-Law Degree Distribution
下面我们来看一下,Natural Graph这种图到底有什么特点,为什么大部分分布式处理系统性能都比较低效,PowerGraph在Natural Graph有如此好的性能。Natural Graphs的属性特点是满足密率度分布。下面我们来看下什么叫幂律度分布。

简单来说,幂律有两个通俗的解释,一个是“长尾”理论,只有少数明星是有很多人关注的,但是还有大部分人只有少部分人关注。长尾理论就是对幂律通俗化的解释。 另外一个通俗解释就是马太效应,穷者越穷富者越富。 从这幅图可以看出,只有一个邻居的点的数目有超过10的8次方个,而仅有那1%的点却占了整个图50%的边。这些点被称为高纬度点。

这里举一个明星效应的例子,比如这里表示社交网络中的一个子图,中间红色点表示某个用户,旁边黑点表示的是所有的粉丝,比如这里我们一个黑点表示100w的用户,那么这个人可能就是obama,但像obama这样拥有这么多粉丝的人是非常少的,大部分人粉丝只有大黑点中的一个点,几百或者多者上千。这就是我们说的密率度分布图的特点。
现有的大部分研究表明,对于这样的幂律图来说:Power-law 是很难去分区的。传统的图划分方法对于Power-law 图来说,执行图算法会造成性能很差。比如书传统的图划分方法:随机划分和edge-cut边划分。
3. PowerGraph Main Idea
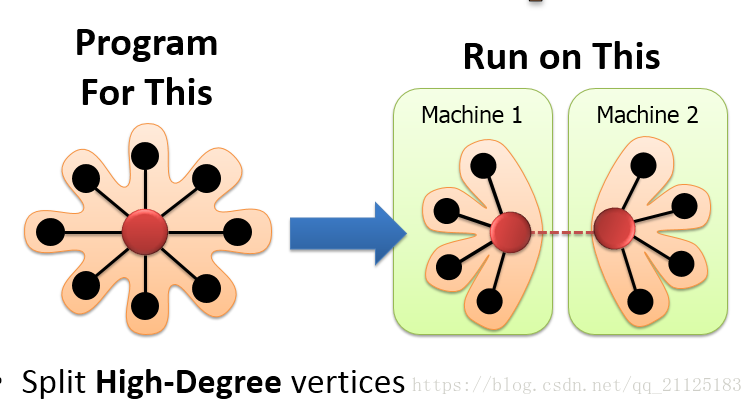
PowerGraph中在计算时会切分高纬度点,被切分的点形成了一个新的抽象。但是在节点切分策略下要解决的一个问题是如何运行节点程序?在之前的边切分策略下节点是单一的、完整的,节点拥有所有邻居的信息,可以独立完成节点程序的运算。但是在节点切分策略下,每个节点看到的只是部分的邻居,无法完成整个计算。在节点切分策略下,分布在不同的CPU或者机器上的节点如何对其进行编程?下面将介绍两种目前最具代表性的图计算方法是如何对图进行并行化抽象计算的。
4. Graph-Parallel Abstraction
图并行化抽象目前流行的两种方法是 :
——使用Message-Passing Pregel
——使用Shared-Memory GraphLab
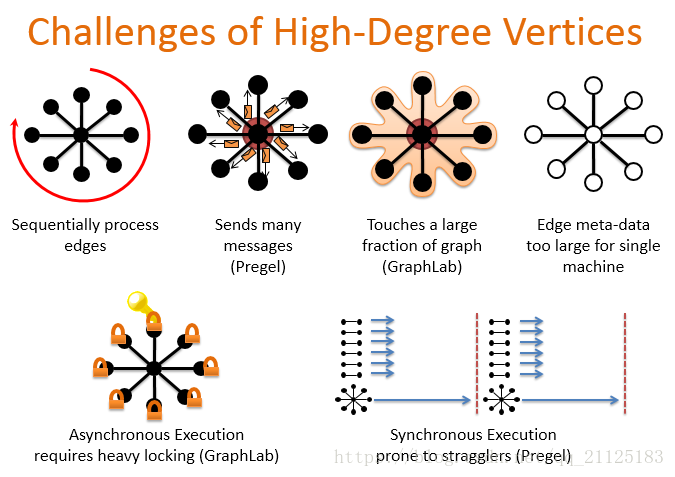
但对于我们前面提到的幂律图,Pregel和GraphLab都不能很好地处理这种节点。最大的挑战就是如何来处理这些高维度的点。最简单也最低效的方法是顺序处理这些边,说白了就是遍历所有点。第二种方法就是刚才提到的Pregel,它处理高纬度点的缺陷是单个worker要发送大量消息给邻居节点。GraphLab的方法的缺点是会触到图的大部分(GraphLab)并且对于单台机器边的元数据太大,GraphLab共享状态是异步执行,需要大量锁 。Pregel同步执行但容易产生straggler,straggler可以理解为执行比较慢的节点(木桶的短板效应)。导致这些系统中存在这些问题主要原因是他们对图的切分策略是采用边分割的方式。下面我们来比较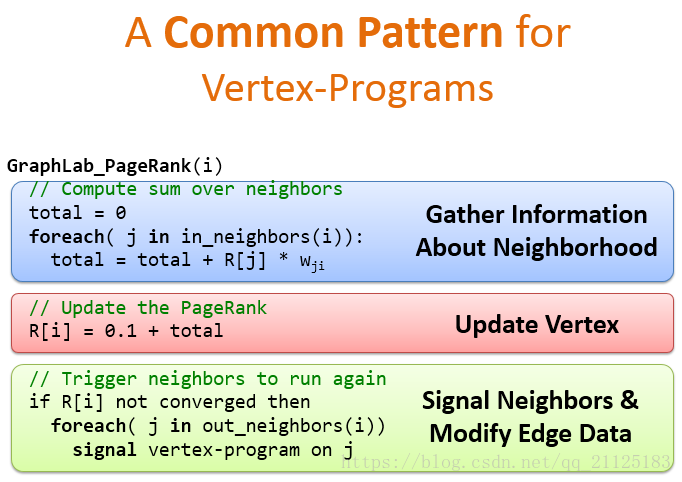 一下边划分和点划分的区别。下面对比了Pregel、GraphLab和PowerGraph在运行PageRank算法上通信开销和执行的时间,可以看出PowerGraph不仅通信开销小而且运行时间短,对高纬度点有很强的健壮性。这时在人工合成的数据集上的一个性能。
一下边划分和点划分的区别。下面对比了Pregel、GraphLab和PowerGraph在运行PageRank算法上通信开销和执行的时间,可以看出PowerGraph不仅通信开销小而且运行时间短,对高纬度点有很强的健壮性。这时在人工合成的数据集上的一个性能。
5. Edge-Cut and Vertex-Cut

还有一种是点切分的方式,下面我们看下边切分的方式和点切分方式有什么不同, 我们现在要将一个有4个顶点的图存储到3台机器上,这三台机器分别叫1,2,3。那么按照边切分的方式,这且边被切人后在3台机器的分布如右边图。 从图中可以看出,切分的过程中,总共有AB,BC,CD三条边被切开,保存到3台机器后,边的总数目由原来的3条,变成了6条,多了一倍,外加5个节点副本。第二种方式是点切分方式,同样是4个节点的图,我们将B、C节点切分开来。存储到3台机器后,得到右边这个图,可以看出我们的边的数目还是3台,只多了两个节点的副本。所以当边的数量比节点数量大很多的情况下,这种两种切分方式差异会更加明显。
图的切分问题又叫着图分区。图并行抽象的性能要依赖于图的分区方式, 而我们的目标是
—— 最小化通信——权衡图计算和存储开销

而前面提到的两种流行的图处理框架GraphLab和Pregel采用的都是边切分方式的随机Hash分区策略这种策略只保证了节点均匀分布在整个集群中,边被切分成双份分散在整个集群中。对于一般图来说,边的数量是要远大于点的数量,因此按边分区会带来存储和计算上的不均衡。 论文中总结了这种边切分方式带来的影响,给出了一个公式用来求被切的边除以总的边的均值,p表示随机被分的机器数目,当p等于10时有90%的边被切分,当p等于100时,有99%的边会被切。 可以看出,当我们集群规模越大,按照边来切分方式进行分区是非常划不来的,图中大部分边会变切分开来。所以作者提出了PowerGraph:一种基于点划分的分布式图处理系统。
6. PowerGraph
这里总结一下目前对于专门的图处理框架GraphLab和Pregel是不适合处理这种natural graphs。主要的两大挑战是高纬度的点和低质量的分区策略。本文提出的PowerGraph即是为了解决这2个问题而设计的,其中Power的意思就是幂律分布的意思。
下面就来介绍PowerGraph的详细设计细节,PowerGraph的主要贡献或者说创新点可归结为以下两点:
第一,提出了GAS计算模型,将高维度的点进行并行化
第二是采用点切分策略,来保证整个集群的均衡性,该策略对大量密率图分区是非常高效的。
6.1 GAS Decomposition
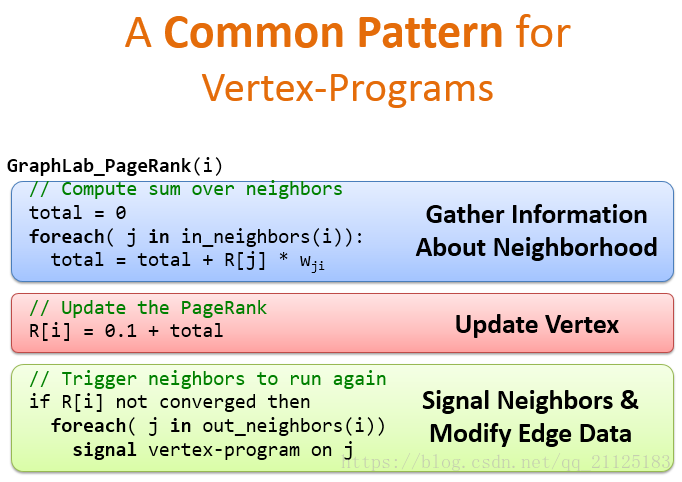
下面以PageRank为例,顶点程序的通用模板大致如图所示,第一步收集邻居节点信息,第二步更新节点权值,如果还没有收敛,触发节点邻居再次运行顶点程序。 这是一种通用的处理模板 。
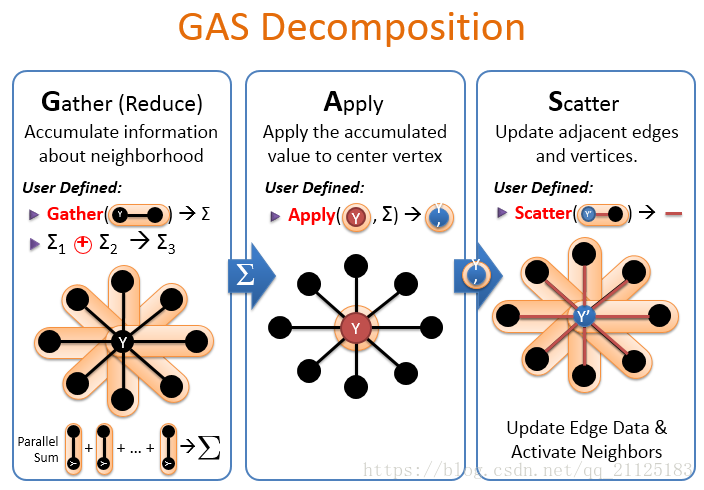
GAS分解过程如下,
Gather:收集邻居信息
先收集同一台机器的信息,然后对不同主机收集的信息进行汇总。得到最后的求和信息。
Apply:对中心点应用收集点的值,得到y一撇
Scatter(分散):更新邻居点和边,并且激活邻居顶点,触发邻居点进行下一轮迭代。

那么就PowerGraph的GAP模型应用到RageRank算法中,是什么样的过程?该公式中i表示目标节点,我们需要对这个节点求PageRank值,wij表示从j点到i点的权值,Gather阶段,先求i所有邻居节点的权值,用户自定义一个sum操作,统计所有邻居节点的权值之和。Apply阶段更新i点的权值,利用上一阶段的sum值加上一个偏置值,计算得到i的新的权值;Scatter阶段如果i值被修改,就触发相应的邻居节点j重新计算。
下面用一个动画演示PowerGraph是如何执行顶点程序。当顶点按点切分方式被分到4台机器之后,在多个节点上指派一个为Master,其余的为Mirror。Mirror上可以运行Gather程序来收集所有邻居的信息,并进行聚合计算(sum)后发送给Master。Master上的Gather程序收集这些结果,最终将这个结果应用到Apply程序上,得到新的节点状态。然后通过Scatter程序将新的节点状态广播给各个Mirror,Mirror进而广播给各个邻居。
6.2 Constructing Vertex-Cuts
PowerGraph提出了一种均衡图划分方案,在减少计算中通信量的同时保证负载均衡。实际上通信开销是和节点所跨的机器数目成线性关系,但点切分的方式可以最小化每个顶点所跨的机器数目。PowerGraph使用的不是边切分,边切分前面已经提到会同步大量的边的信息。而是采用点切分,点切分只要同步一个点的节点信息。
论文中给出了一个新的理论(定理):对于任何边切分我们都可以直接构造一个点切分,能够严格减少通信和存储开销。下面将介绍该论文是如何来构造这个点分割。
论文提出了3种分配方式
随机边分配
贪婪协同边分配
非贪婪边分配(Oblivious遗忘)
6.2.1 随机的边分配策略
第一种策略是随机的边放置策略,按照点切分的方式,随机放置边 。

这里数据集选用的是Twitter数据集,有410w个顶点,14亿条边 。横坐标是实际集群中机器的数目,纵坐标表示1个顶点期望跨了机器数目,关于这两者的数量关系公式,作者在论文中给出了一个定理。蓝色的线表示表示理论推测期望值,红线是实际随机边放置的曲线图。可以看出期望值和理论值之间基本是能够match上的。所以针对随即边放置策略,就可以做到精确的估计内存和通信开销。
6.2.2 贪婪的点切分策略

如果新加进来的边,它的某个节点已经存在于某台机器上,就将该边分到对应的机器上,比如在1号机器上已经存在AB这条边,2号机器上已经存在BC这条边,那门当一条新的边AD在要加进来时,发现A节点已经在1号机器上,所以就将该边放置到1号机器上。如果再来一条边BE,发向两台机器上都存有B节点,这时候贪婪策略会选择机器中分配的边最少的机器进行分配。所以会将BE分配到2号机器,这里只是简单的举了个例子,论文中是用集合的表示方式将这种贪婪策略归纳了4种case,这里不详细介绍,具体可以参考论文第8页相关内容。
上面提到的贪婪策略,作者论文中称之为De-randomiztion。de的含义这里因该是去除,与随机化刚好是反义词。De-randomization就是Greedy的含义,贪婪点切分能够最小化机器所跨的机器数目。实际的贪婪的放置策略性能要比随即放置策略要好。关于贪婪边切分策略,作者给出了两种实现方式:
第一种是协同边放置策略,这需要维护一张全局u顶点放置的历史纪录表,在执行贪心切分之前都要去查询这张表,在执行的过程中需要更新这张表。协同点切分的策略,它的特点是慢但点切分的质量高 ,
第二种方式是Oblivious的贪婪策略,它是一种近似的贪婪策略,不需要做全局的协同。贪婪算法的运行不依赖每一台机器,不需要维护全局的记录表,而是每台机器自己维护这张表,不需要做机器间的通信。这种策略速度快,但切分质量比较低。关于这种方式,论文只用了一段话来描述,具体如何操作明白。
6.2.3 对比三种分区策略的性能
下面是对比这三种分区策略的性能,对比的是平均的机器跨度和构建时间。
协同的贪婪分区算法平局机器跨度最小,但构建时间最长。而随机策略构建时间短,但平局的机器跨度最大。而Oblivious的贪婪分区策略能够在平局机器跨度和构建时间上获得一个折中的性能。
7. System Desgin
整个PowerGraph的架构是这样一个结构,最上层是PowerGraph 系统,它和GraphLab集成到一起,实现的接口是C++,利用HDFS进行数据的输入和输出,利用检查点来实现容错。

在这个系统上实现了许多经典算法,比如:
Alternating Least Squares 交替最小二乘法
Stochastic Gradient Descent随机梯度下降
SVD(Singular Value Decomposition)奇异值分解
Statistical Inference统计推断
Loopy Belief Propagation(LBP)循环信度传播算法
Gibbs Sampling吉布斯采样
Image stitching图像拼接
LDA(Latent Dirichlet Allocation)隐含狄利克雷分布文档主题生成模型
下面对比了Pregel、GraphLab和PowerGraph在运行PageRank算法上通信开销和执行的时间,可以看出PowerGraph不仅通信开销小而且运行时间短,对高纬度点有很强的健壮性。这时在人工合成的数据集上的一个性能。

7. Summary


















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









