









做业务时,往往要加载自己的数据集,本文将结合torch.utils.data.Dataset 和 Dataloader 介绍如何自定义一个数据集加载模块。
本文转自:公众号:写bug的程旭源
pytorch中的数据pipeline设计:
生产者消费者模式,分为sampler、dataset、dataloaderlter、dataloader四个抽象层次:
1、sampler:(采样器)
负责生成读取index序列采样(可以自定义控制采样顺序)
2、dataset:
负责根据index读取相应数据并执行预处理(负责处理索引index到样本sample映射的一个类)
3、dataloaderlter:
负责协调多进程执行dataset
4、dataloader:最顶层的抽象
通过index找出一条数据出来 index——>record
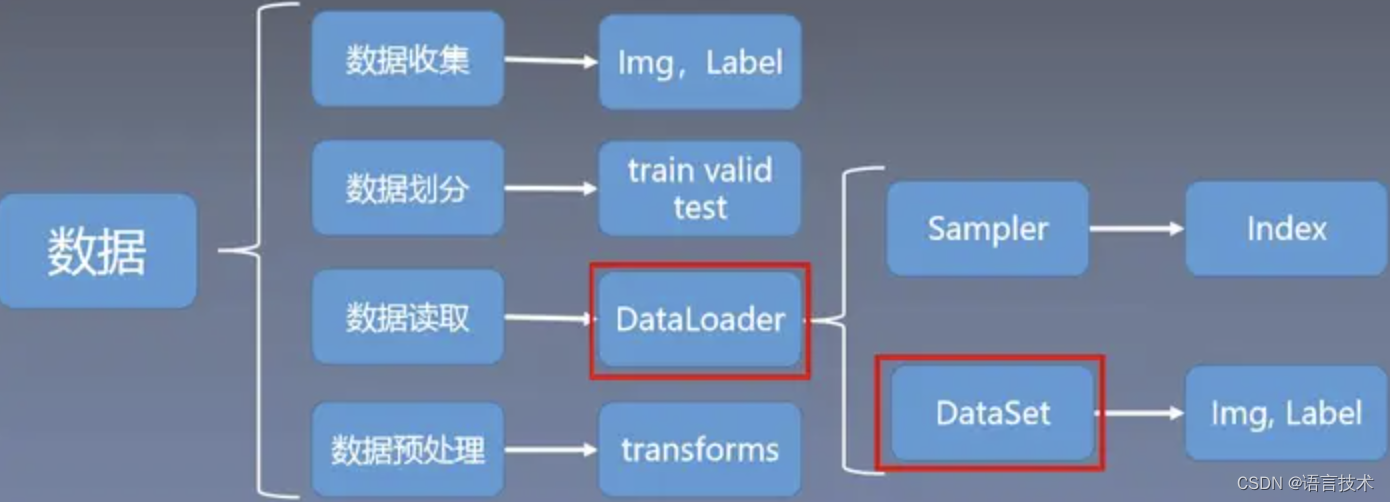
本文主要讲解的是dataset和 dataloader。
深度学习中使用Dataset和Dataloader类的流程:
定义Dataset并实例化;
使用Dataloader加载数据;
循环迭代使用Dataloader加载的数据进行训练或者验证;
(一)构建自定义数据集
import torch.utils.data as data
# 自定义Dataset的基本模板
class ExampleDataset(data.Dataset):
# 自定义一个类
def __init__(self, data):
# 初始化,把数据作为一个参数传递给类;
self.data = data
def __len__(self):
# 返回数据的长度
return len(self.data)
def __getitem__(self, idx):
x = ...
y = ...
return x, y
#根据索引返回数据
# return self.data[idx]自定义数据集一般要有这三个函魔法函数:
def __init__ :初始化,把数据作为一个参数传给类
def __getitem__:根据索引获取样本对(x,y) 索引为(0,len(dataset)-1),根据数据集长度从0开始的索引序列;模型通过这个函数获取一对样本对
def __len__:表示数据集的长度,最终训练时用到的数据集的样本个数
示例
第一个示例,参考[2]:
import torch.utils.data as data
import torchvision.transforms as transforms
import os
import torch
class MyDataset(data.Dataset):
def __init__(self, data_folder):
self.data_folder = data_folder
self.filenames = []
self.labels = []
per_classes = os.listdir(data_folder)
for per_class in per_classes:
per_class_paths = os.path.join(data_folder, per_class)
label = torch.tensor(int(per_class))
per_datas = os.listdir(per_class_paths)
for per_data in per_datas:
self.filenames.append(os.path.join(per_class_paths, per_data))
self.labels.append(label)
def __getitem__(self, index):
image = Image.open(self.filenames[index])
label = self.labels[index]
data = self.preprocess(image)
return data, label
def __len__(self):
return len(self.filenames)
def preprocess(self, data):
transform_train_list = [
transforms.Resize((self.opt.h, self.opt.w), interpolation=3),
transforms.Pad(self.opt.pad, padding_mode='edge'),
transforms.RandomCrop((self.opt.h, self.opt.w)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
return transforms.Compose(transform_train_list)(data)第二个示例,参考[3]:
class Dataset_name(Dataset):
def __init__(self, flag='train'):
assert flag in ['train', 'test', 'valid']
self.flag = flag
self.__load_data__()
def __getitem__(self, index):
pass
def __len__(self):
pass
def __load_data__(self, csv_paths: list):
pass
# print( "train_X.shape:{}\ntrain_Y.shape:{}\nvalid_X.shape:{}\nvalid_Y.shape:{}\n"
# .format(self.train_X.shape, self.train_Y.shape, self.valid_X.shape, # self.valid_Y.shape))
train_dataset = Dataset_name(flag='train')
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
valid_dataset = Dataset_name(flag='valid')
valid_dataloader = DataLoader(dataset=valid_dataset, batch_size=64, shuffle=True)
第三个示例,参考[4]:
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(data.Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label(二)读取数据
创建DataLoader迭代器
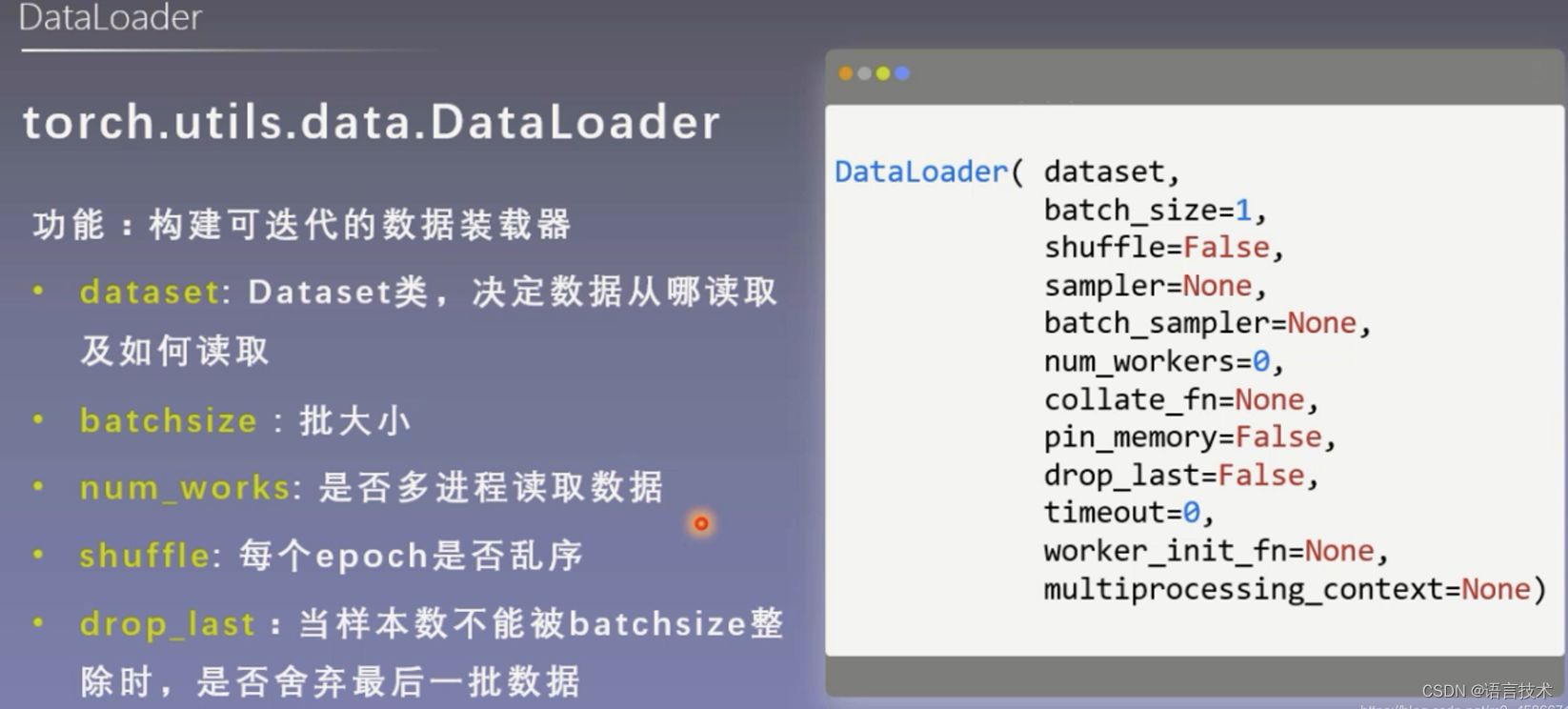
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
valid_dataloader = DataLoader(valid_data, batch_size=64, shuffle=True)使用enumerate访问可遍历的数组对象,参考[5]
for step, (data, label) in enumerate(dataloader):
print('step is :', step)
# data, label = item
print('data is {}, label is {}'.format(data, label))
for i, item in enumerate(dataloader):
print('i:', i)
data, label = item
print('data:', data)
print('label:', label)参考链接:
[1.] https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
[2.] https://mp.weixin.qq.com/s/EcqsWhissIr1woerYQwEcQ
[3.] https://zhuanlan.zhihu.com/p/396666255
[4.] https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
[5.] https://blog.csdn.net/qq_38607066/article/details/98474121














 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









