







Few-shot Object Detection via Feature Reweighting
摘要:这是ICCV2019的一片文章,主要是将Few-Shot Learning用于物体检测上面。其核心思是使用具有大量标签的base类训练一个特征调整模块,通过这个模块可以使用许多类的底层特征对需要检测图片的特征进行调整。这些底层特征能够在一定程度上反应所有类的通性,也可以理解为组成物体的属性(虽然我们检测的物体可能不属于同一类,但是在属性层面还是有很多相通的)然后,再将网络fine tune到小样本检测中去。
模型组成
模型三个模块组成:Feature Extractor;Reweighting Module;Prediction Layer
Feature Extractor
其中,Feature Extractor主要用来提取待检测图片(query image)的特征。对于一张图片,使用YoLoV2的backbone(DarkNet)来提取特征,如下图所示:
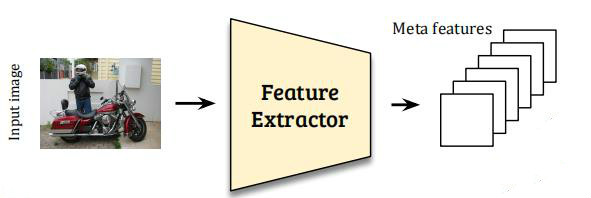
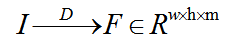
Reweighting Module
Reweighting Module主要是使用从base类中提取的属性特征对待检测图片特征进行调整。既然,我们需要提取base的属性特征,所以base类的标签一定是可知的,只有将标签融合进网络,网络才能知道怎么提取基础属性特征。至于怎么提取,这就是深度学习需要做的事情了。所以如下图所示:

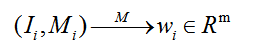

Prediction Layer
然后就简单了,将得到向量特征输入到常用的检测网络中计算待检测图像的一些损失。包括好多好多损失,都是物体检测中常用的损失,所以网络的整体框架也就出来了:

训练策略
模型会首先在标签足够的base类上进行训练,使得三个模块都能够正确的提取对应的特征而且能够协同工作后,在迁移到小样本上进行训练。
(1)所以模型的训练分为两步,首先在base类中,产生足够的Task来进行模型的第一步训练。
(2)然后,将base类和小样本的novel类进行融合。在base+novel类上进行最后的训练。
需要注意的是,在第二步的训练中。因为novel类的标签很少,通常只有k个(k-shot),所以为了类别平衡,相对应的也只是使用base类中每个类别的k个标签。这样才能真正达到小样本学习的效果。

待完成所有训练后,模型已经可以检测出新的小样本了。模型在voc和coco数据集上进行了检验,最后贴两个检验效果:

















 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









