






linux内存管理
段式存储
早期的8086和8088是16位的处理器,但由于对内存空间的需求,8086采用了1M字节的内存地址空间,那么地址总线的宽度就是20位,为了在16位的cpu上进行20位的寻址,intel设计了段式内存管理。
实模式
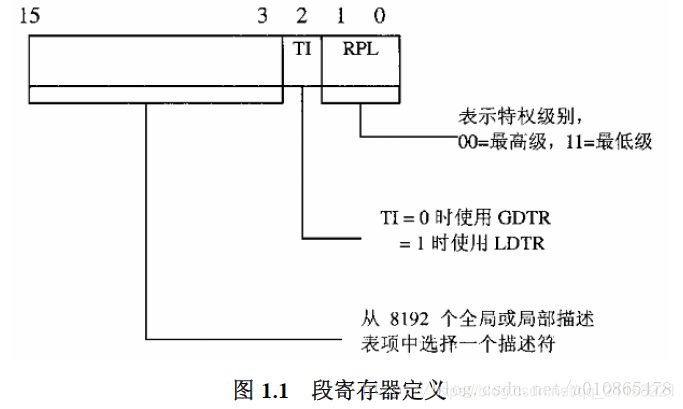
intel在8086 cpu上设置了四个16位的段寄存器:cs(代码段)、ds(数据段)、ss(堆栈)、es(其他),他们对应于地址总线中的高16位。在要寻址的内部地址(16位)被送入地址总线(20位)之前,cpu内部自动的将内部地址的高12位与对应的段寄存器中的16位相加,这样就形成了一个20位的地址,使得任意一个进程都可以访问内存中的任意一个单元。
保护模式
由于实模式下的段式存储没有对访问权限的限制,所以在80286/80386开始,intel实现了保护模式。
80386是32位的cpu,但是intel为了兼容老产品,依然沿用了16位的段寄存器,并且新增了两个段寄存器fs和gs,新增了两个段描述表寄存器,gdtr和ldtr分别用来存储全局段描述表和局部段描述表,并且将访问这两个寄存器的指令设置为特权指令(LGDT/LLDT和SGDT/SLDT)。
段表述表指向一个段描述结构数组,段描述结构中定义了段的起始地址,长度以及其他的一些有用信息

而段寄存器的高13位用作索引这个表的下标。
这样当cpu发出一条访问内存的指令时
1)首先通过特权指令可以找到段描述表的位置
2)然后通过指令的性质(转移指令在代码段,取数指令在数据段)确定使用哪一个段寄存器
3)通过段寄存器中的内容索引到对应的段描述项
4)指令发出的地址作为偏移,与段描述项中的段长度对比,看是否越界,并检查段描述项中的权限设置,看是否越权
5)指令地址作为偏移与段描述项中的基地址相加得到实际的地址
linux中的段式存储
linux采用页式存储管理,但段式存储无法绕过,所以linux采用平坦模式(flat),即把所有段寄存器都指向同一个描述项,并且描述项中基地址设置为0,长度设置为最大的4G,这样整个32位地址空间成为一个段,物理地址与逻辑地址相同。
页式存储
页式存储将线性地址空间划分成4K的页面进行管理,每个页面可以映射至物理内存的任意一块4K大小的空间。
32位地址空间可寻址范围4G字节,linux将这4G空间划分为两部分。最高的1G(0xC0000000-0xFFFFFFFF)用于内核本身,低3G(0x0-0xBFFFFFFF)用作各个进程的用户空间。
内核空间的虚拟地址直接映射到物理内存的0x0-1G的空间,所以内核空间的虚拟地址和物理地址之间的转换可以简单的加上一个page_offset来表。
需要注意的是,这种表示方法并不是映射方法,只是一种方便的表示方法。
include/asm-i386/page.h
#define __PAGE_OFFSET (0xC0000000)
...
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
线性地址到物理地址的映射过程
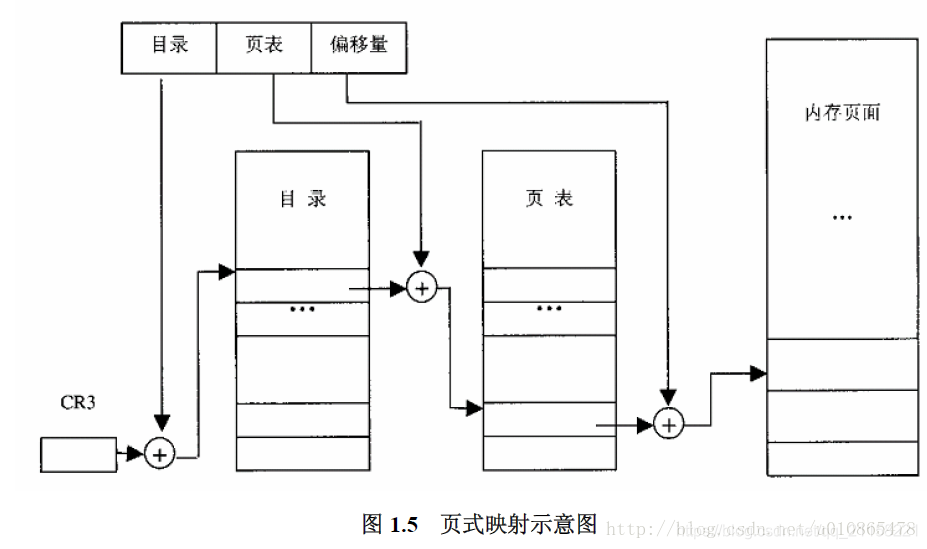
页式存储中,线性地址被划分为三个部分,dir,pte,offset
dir:页面目录索引,31–22共10bit,可索引210=1024个页面目录,页面目录的首地址存储在CR3寄存器中,页面目录项中存储着其管理着的页面表的首地址
pte:页面表索引,21–12共10bit,页面项中的高20位存储着其管理的页面在mem_map中的位置,低12位用作描述页面属性(存在映射p=1)或页面去向(页面换出至磁盘p=0),高20位加12个0即为对应物理页面的起始地址
offset:页内偏移

线性地址到物理地址的转换过程
1)首先从CR3中获取页面目录首地址pdir_tb
2)索引目录项,找到页表首地址pte_tb = pdir_tb[addr >> 22]
3)索引页表项,找到对应的物理页面地址paddr_tb = pte_tb[addr >> 12 & (1024-1)] & ~ (4096 - 1)
4)加offset,paddr = paddr_tb + offset
虚拟内存管理
虚存空间的管理以进程为基础,每个进程都有自己的虚存空间,虚存区间的控制结构struct vm_area_struct在include/linux/mm.h中:
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
struct mm_struct * vm_mm; /* VM area parameters */
unsigned long vm_start;
unsigned long vm_end;
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
/* AVL tree of VM areas per task, sorted by address */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* For areas with an address space and backing store,
* one of the address_space->i_mmap{,shared} lists,
* for shm areas, the list of attaches, otherwise unused.
*/
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops;
unsigned long vm_pgoff; /* offset in PAGE_SIZE units, *n ot* PAGE_CACHE_SIZE */
struct file * vm_file;
unsigned long vm_raend;
void * vm_private_data; /* was vm_pte (shared mem) */
};
其中[vm_start,vm_end)是这个虚存区间的开始和结束,start包含在区间里,end不在。vm_page_prot和vm_flags描述了一个区间所有页面的属性和用途,通过vm_next指针,同一个进程的所有区间都被连接在一个链表里。vm_avl_height,vm_avl_left和vm_avl_right用作将这些区间构成一个avl树,增加了在区间数量较多的情况下的检索效率。
vm_ops定义了一组类似文件操作的指针,用于每个区间在打开,关闭和建立映射时可以有各自独特的操作,nopage指向的函数是page_fault时调用来申请物理内存并建立映射的:
/*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);
};
vm_area_struct中的vm_mm是一个指向mm_struct结构的指针,是进程的控制结构,包含在进程控制块task_struct中,结构定义在include/linux/sched中:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct vm_area_struct * mmap_avl; /* tree of VMAs */
struct vm_area_struct * mmap_cache; /* last find_vma result */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct semaphore mmap_sem;
spinlock_t page_table_lock;
struct list_head mmlist; /* List of all active mm's */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_cnt; /* number of pages to swap on next pass */
unsigned long swap_address;
/* Architecture-specific MM context */
mm_context_t context;
};
mmap用来构建进程所有虚存区间的单项链表,mmap_avl则是所有区间构成的avl树,mmap_cache用来指向最近一次使用的虚存区间,这是因为最近一次使用的区间很有可能是下一次要使用的区间,这样在寻找区间时就能极大的提高效率,map_count用来表示当前进程有多少个区间。
pgd指向进程的页表目录,当内核调度一个进程进入运行时,就将这个指针转换成物理地址,写入CR3中。
page_fault
mm_struct和vm_area_struct是表明了对虚存空间的需求,这个虚存空间则不一定真实的映射到某一个物理页面,更不能保证这个页面就在内存中(换出),所以当一个未经映射的页面受到访问时,就会产生缺页异常page_fault,并执行处理函数do_page_fault。
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*
* error_code:
* bit 0 == 0 means no page found, 1 means protection fault
* bit 1 == 0 means read, 1 means write
* bit 2 == 0 means kernel, 1 means user-mode
*/
asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
struct task_struct *tsk;
struct mm_struct *mm;
struct vm_area_struct * vma;
unsigned long address;
unsigned long page;
unsigned long fixup;
int write;
siginfo_t info;
/* get the address */
__asm__("movl %%cr2,%0":"=r" (address));
tsk = current;
/*
* We fault-in kernel-space virtual memory on-demand. The
* 'reference' page table is init_mm.pgd.
*
* NOTE! We MUST NOT take any locks for this case. We may
* be in an interrupt or a critical region, and should
* only copy the information from the master page table,
* nothing more.
*/
if (address >= TASK_SIZE)
goto vmalloc_fault;
mm = tsk->mm;
info.si_code = SEGV_MAPERR;
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
if (in_interrupt() || !mm)
goto no_context;
down(&mm->mmap_sem);
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
i386 cpu会将产生缺页异常的地址存放在cr2中,首先获取这个地址,然后找到他的虚存区间
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache;//上次用的vma
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {//没满足就是中了,直
//接跳过
if (!mm->mmap_avl) {//没树遍历链表
/* Go through the linear list. */
vma = mm->mmap;
while (vma && vma->vm_end <= addr)//找到第一个vm_end>addr
vma = vma->vm_next;
} else {//有树找树
/* Then go through the AVL tree quickly. */
struct vm_area_struct * tree = mm->mmap_avl;
vma = NULL;
for (;;) {
if (tree == vm_avl_empty)
break;
if (tree->vm_end > addr) {
vma = tree;
if (tree->vm_start <= addr)
break;//找到第一个vm_end>addr且vm_start <= addr
tree = tree->vm_avl_left;
} else
tree = tree->vm_avl_right;
}
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
要是没找到,看一下error_code,cpu在用户模式那就是越界了,直接返回,并向用户进程发送一个信号。
/*
* error_code:
* bit 0 == 0 means no page found, 1 means protection fault
* bit 1 == 0 means read, 1 means write
* bit 2 == 0 means kernel, 1 means user-mode
*/
/*
* Something tried to access memory that isn't in our memory map..
* Fix it, but check if it's kernel or user first..
*/
bad_area:
up(&mm->mmap_sem);
bad_area_nosemaphore:
/* User mode accesses just cause a SIGSEGV */
if (error_code & 4) {
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
info.si_signo = SIGSEGV;
info.si_errno = 0;
/* info.si_code has been set above */
info.si_addr = (void *)address;
force_sig_info(SIGSEGV, &info, tsk);
return;
}
不是用户空间的话,那就是kernel访问了非法地址,这就比较严重了,如果能fix就fix然后return,fix不了就干掉当前进程。
回头看find_vma的几过不是0的话,说明找到了一块空间,但如果vma->start>addr的话,说明发生异常的地址落在了一个空洞里。
而落在空洞里有两种情况,一种是落在了堆栈区以下,一种是这个区间的映射被撤消了或者压根没有建立过映射,显然第二中空洞也属于越界访问,也需要跳转到bad_area标号处去访问。堆栈的扩展方向是向下的,所以当(vma->vm_flags & VM_GROWSDOWN) == 0时就说明空洞上方不是堆栈区,属于第二种情况。
如果当(vma->vm_flags & VM_GROWSDOWN) != 0时就说明空洞上方是堆栈区,那么这里有一个特例,就是用户堆栈空间已经用尽,即esp已经指向堆栈区间的起始地址时,cpu需要将返回地址压栈(esp-4这个地址),这个地址并未映射,并且这次空洞落在了堆栈区下方,所以(vma->vm_flags & VM_GROWSDOWN) == 1
if (error_code & 4) {
/*
* accessing the stack below %esp is always a bug.
* The "+ 32" is there due to some instructions (like
* pusha) doing post-decrement on the stack and that
* doesn't show up until later..
*/
if (address + 32 < regs->esp)
goto bad_area;
}
if (expand_stack(vma, address))
goto bad_area;
当前场景下应该有address == esp-4,但是因为i386有一条pusha指令,可以将32个字节一次压栈,所以超过这个范围就判断不是当前这个场景,同之前一样跳转到bad_area处理。
如果是正常的扩展堆栈需求,就调用expand_stack从空洞顶部开始,分配若干页面建立映射,并将其并入堆栈区:
/* vma is the first one with address < vma->vm_end,
* and even address < vma->vm_start. Have to extend vma. */
static inline int expand_stack(struct vm_area_struct * vma, unsigned long address)
{
unsigned long grow;
address &= PAGE_MASK;
grow = (vma->vm_start - address) >> PAGE_SHIFT;
if (vma->vm_end - address > current->rlim[RLIMIT_STACK].rlim_cur ||
((vma->vm_mm->total_vm + grow) << PAGE_SHIFT) > current->rlim[RLIMIT_AS].rlim_cur)
return -ENOMEM;
vma->vm_start = address;
vma->vm_pgoff -= grow;
vma->vm_mm->total_vm += grow;
if (vma->vm_flags & VM_LOCKED)
vma->vm_mm->locked_vm += grow;
return 0;
}
vma为堆栈所在的区间,最小单位是页面,所以先将地址按页面对齐,grow是需要扩展的页数,每个进程都有一组rlim用来限制其各种资源的使用,RLIMIT_STACK就是对用户空间堆栈大小的限制,所以判断扩展后堆栈大小和整个区间大小都不超过限制的情况下,扩展当前区间。
当然扩展完的虚拟区间需要执行good_area后面的程序进行物理页面的映射,这就与正常映射失败导致的异常是相同的流程了。
/*
* Ok, we have a good vm_area for this memory access, so
* we can handle it..
*/
good_area:
info.si_code = SEGV_ACCERR;
write = 0;
switch (error_code & 3) {
default: /* 3: write, present */
#ifdef TEST_VERIFY_AREA
if (regs->cs == KERNEL_CS)
printk("WP fault at %08lx\n", regs->eip);
#endif
/* fall through */
case 2: /* write, not present */
if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
break;
case 1: /* read, present */
goto bad_area;
case 0: /* read, not present */
if (!(vma->vm_flags & (VM_READ | VM_EXEC)))
goto bad_area;
}
/*
* If for any reason at all we couldn't handle the fault,
* make sure we exit gracefully rather than endlessly redo
* the fault.
*/
switch (handle_mm_fault(mm, vma, address, write)) {
case 1:
tsk->min_flt++;
break;
case 2:
tsk->maj_flt++;
break;
case 0:
goto do_sigbus;
default:
goto out_of_memory;
}
首先检查error_code,case 0表示读操作缺页,所以若区间不支持读操作,那肯定是出错了,直接跳到bad_area,case 1表示物理页存在,这也属于异常直接goto bad_area,case 2表示写操作缺页,所以不支持写操作的话就goto bad_area。
接下来将读写权限传入handle_mm_fault,为区间添加物理页面的映射:
/*
* By the time we get here, we already hold the mm semaphore
*/
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,
unsigned long address, int write_access)
{
int ret = -1;
pgd_t *pgd;
pmd_t *pmd;
pgd = pgd_offset(mm, address);
pmd = pmd_alloc(pgd, address);
if (pmd) {
pte_t * pte = pte_alloc(pmd, address);
if (pte)
ret = handle_pte_fault(mm, vma, address, write_access, pte);
}
return ret;
}
首先由pgd_offset计算出页表目录的地址:
/* to find an entry in a page-table-directory. */
#define pgd_index(address) ((address >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))
#define __pgd_offset(address) pgd_index(address)
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
然后位页表目录分配一个中间目录,由于i386只使用两层页表,所以中间目录只是指向了pgd:
extern inline pmd_t * pmd_alloc(pgd_t *pgd, unsigned long address)
{
if (!pgd)
BUG();
return (pmd_t *) pgd;
}
接下来分配一个页表:
extern inline pte_t * pte_alloc(pmd_t * pmd, unsigned long address)
{
address = (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);//目录项索引
if (pmd_none(*pmd))
goto getnew;
if (pmd_bad(*pmd))
goto fix;
return (pte_t *)pmd_page(*pmd) + address;//目录项内容,也就是页表地址
getnew:
{
unsigned long page = (unsigned long) get_pte_fast();
if (!page)
return get_pte_slow(pmd, address);
set_pmd(pmd, __pmd(_PAGE_TABLE + __pa(page)));
return (pte_t *)page + address;
}
fix:
__handle_bad_pmd(pmd);
return NULL;
}
首先判断目录项是不是0,是0表示没有页表,去get_new搞一个,不是0就直接返回对应的页表地址。
getnew首先尝试get_pte_fast,内核将释放的页表放在一个缓冲池中,只有缓冲池满了以后,才真的将页表占用的物理内存释放:
extern __inline__ pte_t *get_pte_fast(void)
{
unsigned long *ret;
if((ret = (unsigned long *)pte_quicklist) != NULL) {
pte_quicklist = (unsigned long *)(*ret);
ret[0] = ret[1];
pgtable_cache_size--;
}
return (pte_t *)ret;
}
extern __inline__ void free_pte_fast(pte_t *pte)
{
*(unsigned long *)pte = (unsigned long) pte_quicklist;
pte_quicklist = (unsigned long *) pte;
pgtable_cache_size++;
}
fast失败了(!page)就只能slow了:
pte_t *get_pte_slow(pmd_t *pmd, unsigned long offset)
{
unsigned long pte;
pte = (unsigned long) __get_free_page(GFP_KERNEL);
if (pmd_none(*pmd)) {
if (pte) {
clear_page((void *)pte);
set_pmd(pmd, __pmd(_PAGE_TABLE + __pa(pte)));
return (pte_t *)pte + offset;
}
set_pmd(pmd, __pmd(_PAGE_TABLE + __pa(get_bad_pte_table())));
return NULL;
}
free_page(pte);
if (pmd_bad(*pmd)) {
__handle_bad_pmd(pmd);
return NULL;
}
return (pte_t *) pmd_page(*pmd) + offset;
}
首先从伙伴系统申请一个页面,然后将页面地址写入pmd。__get_free_page起始就是调用了alloc_pages分配一个页面,alloc_pages的说明见下文物理内存管理中的的物理页面的分配。
此时pte_alloc完成,页表已经准备好了,只是页表还是空的,真正的映射要在handle_mm_fault->handle_pte_fault中实现:
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* Note the "page_table_lock". It is to protect against kswapd removing
* pages from under us. Note that kswapd only ever _removes_ pages, never
* adds them. As such, once we have noticed that the page is not present,
* we can drop the lock early.
*
* The adding of pages is protected by the MM semaphore (which we hold),
* so we don't need to worry about a page being suddenly been added into
* our VM.
*/
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct * vma, unsigned long address,
int write_access, pte_t * pte)
{
pte_t entry;
/*
* We need the page table lock to synchronize with kswapd
* and the SMP-safe atomic PTE updates.
*/
spin_lock(&mm->page_table_lock);
entry = *pte;
if (!pte_present(entry)) {
/*
* If it truly wasn't present, we know that kswapd
* and the PTE updates will not touch it later. So
* drop the lock.
*/
spin_unlock(&mm->page_table_lock);
if (pte_none(entry))
return do_no_page(mm, vma, address, write_access, pte);
return do_swap_page(mm, vma, address, pte, pte_to_swp_entry(entry), write_access);
}
if (write_access) {
if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, entry);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
establish_pte(vma, address, pte, entry);
spin_unlock(&mm->page_table_lock);
return 1;
}
entry是页表项,表项的最后一位是present,为1表示存在,0表示不存在。不存在一是页表项是空的是0,说明还没有映射过;二是页表项不是空的,说明这个表项对应的页面被交换到交换设备上面去了,那我们需要把它交换回来。这里我们暂不讨论页面交换的场景,来看以下do_no_page:
/*
* do_no_page() tries to create a new page mapping. It aggressively
* tries to share with existing pages, but makes a separate copy if
* the "write_access" parameter is true in order to avoid the next
* page fault.
*
* As this is called only for pages that do not currently exist, we
* do not need to flush old virtual caches or the TLB.
*
* This is called with the MM semaphore held.
*/
static int do_no_page(struct mm_struct * mm, struct vm_area_struct * vma,
unsigned long address, int write_access, pte_t *page_table)
{
struct page * new_page;
pte_t entry;
if (!vma->vm_ops || !vma->vm_ops->nopage)
return do_anonymous_page(mm, vma, page_table, write_access, address);
/*
* The third argument is "no_share", which tells the low-level code
* to copy, not share the page even if sharing is possible. It's
* essentially an early COW detection.
*/
new_page = vma->vm_ops->nopage(vma, address & PAGE_MASK, (vma->vm_flags & VM_SHARED)?0:write_access);
if (new_page == NULL) /* no page was available -- SIGBUS */
return 0;
if (new_page == NOPAGE_OOM)
return -1;
++mm->rss;
/*
* This silly early PAGE_DIRTY setting removes a race
* due to the bad i386 page protection. But it's valid
* for other architectures too.
*
* Note that if write_access is true, we either now have
* an exclusive copy of the page, or this is a shared mapping,
* so we can make it writable and dirty to avoid having to
* handle that later.
*/
flush_page_to_ram(new_page);
flush_icache_page(vma, new_page);
entry = mk_pte(new_page, vma->vm_page_prot);
if (write_access) {
entry = pte_mkwrite(pte_mkdirty(entry));
} else if (page_count(new_page) > 1 &&
!(vma->vm_flags & VM_SHARED))
entry = pte_wrprotect(entry);
set_pte(page_table, entry);
/* no need to invalidate: a not-present page shouldn't be cached */
update_mmu_cache(vma, address, entry);
return 2; /* Major fault */
}
首先如果区间没有设置特定的nopage函数,那么就会调用do_anonymous_page并返回其结果,如果有,则执行区间制定的nopage函数获区页面,rss表示当前进程占用的页面数量,成功的话通过mk_pte将page和vm_page_prot(区间的页面属性)制作成页表项也如页表对应位置,返回2。
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
#define mk_pte(page, pgprot) __mk_pte((page) - mem_map, (pgprot))
page_nr = page-mem_map表示页面的编号,这个编号最大220所以将低12位空出来描述页面的属性。
对于没有指定nopage的区间而言,直接调用do_anonymous_page:
static int do_anonymous_page(struct mm_struct * mm, struct vm_area_struct * vma, pte_t *page_table, int write_access, unsigned long addr)
{
struct page *page = NULL;
pte_t entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr), vma->vm_page_prot));
if (write_access) {
page = alloc_page(GFP_HIGHUSER);
if (!page)
return -1;
clear_user_highpage(page, addr);
entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)));
mm->rss++;
flush_page_to_ram(page);
}
set_pte(page_table, entry);
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, addr, entry);
return 1; /* Minor fault */
}
首先默认读操作的情况下,不管虚拟地址是什么都将ZERO_PAGE加上区间属性构成页表项,这是一个内容全0全局数组,是一个特殊的物理页面:
extern unsigned long empty_zero_page[1024];
#define ZERO_PAGE(vaddr) (virt_to_page(empty_zero_page))
只有写操作的情况下才真正的分配独立的物理内存,并将使用物理内存地址和区间属性构成页表项,写入页表对应的位置。
至此,映射建立完毕,由映射尚未建立或者堆栈扩展产生的缺页异常就处理完了。
物理内存管理
bios-e820
系统boot阶段,setup.s会向bios发送e820指令获取内存信息
arch/i386/boot/setup.s
# Get memory size (extended mem, kB)
xorl %eax, %eax
movl %eax, (0x1e0)
#ifndef STANDARD_MEMORY_BIOS_CALL
movb %al, (E820NR)
# Try three different memory detection schemes. First, try
# e820h, which lets us assemble a memory map, then try e801h,
# which returns a 32-bit memory size, and finally 88h, which
# returns 0-64m
# method E820H:
# the memory map from hell. e820h returns memory classified into
# a whole bunch of different types, and allows memory holes and
# everything. We scan through this memory map and build a list
# of the first 32 memory areas, which we return at [E820MAP].
# This is documented at http://www.teleport.com/~acpi/acpihtml/topic245.htm
#define SMAP 0x534d4150
meme820:
xorl %ebx, %ebx # continuation counter
movw $E820MAP, %di # point into the whitelist
# so we can have the bios
# directly write into it.
jmpe820:
movl $0x0000e820, %eax # e820, upper word zeroed
movl $SMAP, %edx # ascii 'SMAP'
movl $20, %ecx # size of the e820rec
pushw %ds # data record.
popw %es
int $0x15 # make the call
jc bail820 # fall to e801 if it fails
cmpl $SMAP, %eax # check the return is `SMAP'
jne bail820 # fall to e801 if it fails
# cmpl $1, 16(%di) # is this usable memory?
# jne again820
# If this is usable memory, we save it by simply advancing %di by
# sizeof(e820rec).
#
good820:
movb (E820NR), %al # up to 32 entries
cmpb $E820MAX, %al
jnl bail820
incb (E820NR)
movw %di, %ax
addw $20, %ax
movw %ax, %di
again820:
cmpl $0, %ebx # check to see if
jne jmpe820 # %ebx is set to EOF
读上来的内存信息按照如下结构存储成一个结构数组
struct e820entry {
__u64 addr; /* start of memory segment */
__u64 size; /* size of memory segment */
__u32 type; /* type of memory segment */
} __attribute__((packed));
这个结构数组在内存初始化完成前临时存放在全局页面empty_zero_page[4096]中(这个页面将来会用来映射给缺页异常中的只读缺页异常)。
arch/i386/kernel/setup.c
/*
* This is set up by the setup-routine at boot-time
*/
#define PARAM ((unsigned char *)empty_zero_page)
...
#define E820_MAP_NR (*(char*) (PARAM+E820NR))
#define E820_MAP ((struct e820entry *) (PARAM+E820MAP))
...
然后在start_kernel–>setup_arch–>setup_memory_region–>copy_e820_map中把640k - 1M这段区间抠出去,原因如下图所示,这段存储空间被留作VGA显示等硬件的用途
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
将这些内存信息复制到全局变e820中
include/asm-i386/e820.h
struct e820map {
int nr_map;
struct e820entry {
unsigned long long addr; /* start of memory segment */
unsigned long long size; /* size of memory segment */
unsigned long type; /* type of memory segment */
} map[E820MAX];
};
接下来通过e820的内容计算整个物理内存可以被划分成多少个页面,最大页面max_low_pfn。
/*
* partially used pages are not usable - thus
* we are rounding upwards:
*/
start_pfn = PFN_UP(__pa(&_end));//这里_end在ld文件中定义,是内核镜像结束的地方。
//__pa是将虚拟地址转化成物理地址
//用作自举分配器的位图首地址
/*
* Find the highest page frame number we have available
*/
max_pfn = 0;
for (i = 0; i < e820.nr_map; i++) {
unsigned long start, end;
/* RAM? */
if (e820.map[i].type != E820_RAM)
continue;
start = PFN_UP(e820.map[i].addr);
end = PFN_DOWN(e820.map[i].addr + e820.map[i].size);
if (start >= end)
continue;
if (end > max_pfn)
max_pfn = end;
}
/*
* Determine low and high memory ranges:
*/
max_low_pfn = max_pfn;
PFN_UP和PFN_DOWN是对page_size的向上和向下取整对齐。
#define PFN_UP(x) (((x) + PAGE_SIZE-1) >> PAGE_SHIFT)
#define PFN_DOWN(x) ((x) >> PAGE_SHIFT)
bootmem
在内核初始化阶段,用于内存管理的伙伴算法系统尚未初始化完成,但初始化内存管理本身确需要分配内存,所以内核在这个阶段采取了一种较为简单的内存管理方式,将所有内存页用一个位图来控制,每次分配内存时从头扫描位图,找到第一个满足内存分配需求的位置,将该段bit位置1表示已经分配。
start_kernel–>setup_arch–>init_bootmem–>init_bootmem_core初始化了这个分配器
/*
* Called once to set up the allocator itself.
*/
static unsigned long __init init_bootmem_core (pg_data_t *pgdat,
unsigned long mapstart, unsigned long start, unsigned long end)
{
bootmem_data_t *bdata = pgdat->bdata;
unsigned long mapsize = ((end - start)+7)/8;//需要使用这么多字节
pgdat->node_next = pgdat_list;
pgdat_list = pgdat;
mapsize = (mapsize + (sizeof(long) - 1UL)) & ~(sizeof(long) - 1UL);//按long对齐
bdata->node_bootmem_map = phys_to_virt(mapstart << PAGE_SHIFT);//位图首地址
bdata->node_boot_start = (start << PAGE_SHIFT);//当前管理的内存的首地址
bdata->node_low_pfn = end;//页数
/*
* Initially all pages are reserved - setup_arch() has to
* register free RAM areas explicitly.
*/
memset(bdata->node_bootmem_map, 0xff, mapsize);
return mapsize;
}
参数pgdat表示一个内存节点,在smp系统中,每个cpu到达自己的内存和到达其他cpu或者是公共内存的距离不同,导致性能和权限等等的差异。每个cpu的内存作为一个内存节点被pg_data_t所描述,并将这些节点链接成链,这样系用就可以根据节点的描述,距离和自身的需求选择访问哪个节点的内存。
只有一个cpu的系统只有一个全局的pg_data_t结构,他被定义在mm/numa.c中
static bootmem_data_t contig_bootmem_data;
pg_data_t contig_page_data = { bdata: &contig_bootmem_data };
bdata即为当前节点的自举分配器管理结构,具体成员如下
/*
* node_bootmem_map is a map pointer - the bits represent all physical
* memory pages (including holes) on the node.
*/
typedef struct bootmem_data {
unsigned long node_boot_start;//内存起点
unsigned long node_low_pfn;//终点
void *node_bootmem_map;//位图首地址,start_pfn
unsigned long last_offset;//上次分配的结束地址的页内偏移
unsigned long last_pos;//上次分配的页的偏移
} bootmem_data_t;
自举分配器通过last_offset和last_pos来应对分配内存的需求不是按页对齐的情况,当last_offset不为0时,说明上一个页面只分配了一部分,还剩page_size - last_offset可供分配使用,last_pos指出了未完全分配的页的位置。
初始化结束后所有内存均被设置为不可分配的保留状态,然后根据e820map的信息,通过free_bootmem将所有可用的内存设置为free
for (i = 0; i < e820.nr_map; i++) {
unsigned long curr_pfn, last_pfn, size;
/*
* Reserve usable low memory
*/
if (e820.map[i].type != E820_RAM)
continue;
/*
* We are rounding up the start address of usable memory:
*/
curr_pfn = PFN_UP(e820.map[i].addr);
if (curr_pfn >= max_low_pfn)
continue;
/*
* ... and at the end of the usable range downwards:
*/
last_pfn = PFN_DOWN(e820.map[i].addr + e820.map[i].size);
if (last_pfn > max_low_pfn)
last_pfn = max_low_pfn;
/*
* .. finally, did all the rounding and playing
* around just make the area go away?
*/
if (last_pfn <= curr_pfn)
continue;
size = last_pfn - curr_pfn;
free_bootmem(PFN_PHYS(curr_pfn), PFN_PHYS(size));
}
自举分配alloc_bootmem_low_pages
alloc_bootmem_low_pages由宏定义实现为__alloc_bootmem((x), PAGE_SIZE, 0),指定了对齐长度位page_size,开始扫描的地方(goal)为0
#define alloc_bootmem_low_pages(x) \
__alloc_bootmem((x), PAGE_SIZE, 0)
__alloc_bootmem的核心为__alloc_bootmem_core,只是用了一个循环遍历pgdat_list。__alloc_bootmem_core实现的功能就是从当前自举分配器中扫描位图,找到连续的size个字节,返回连续字节的首地址,并将相应位图置位。
/*
* alignment has to be a power of 2 value.
*/
static void * __init __alloc_bootmem_core (bootmem_data_t *bdata,
unsigned long size, unsigned long align, unsigned long goal)
{
unsigned long i, start = 0;
void *ret;
unsigned long offset, remaining_size;
unsigned long areasize, preferred, incr;
unsigned long eidx = bdata->node_low_pfn - (bdata->node_boot_start >>
PAGE_SHIFT);
if (!size) BUG();
/*
* We try to allocate bootmem pages above 'goal'
* first, then we try to allocate lower pages.
*/
if (goal && (goal >= bdata->node_boot_start) &&
((goal >> PAGE_SHIFT) < bdata->node_low_pfn)) {
preferred = goal - bdata->node_boot_start;
} else
preferred = 0;
preferred = ((preferred + align - 1) & ~(align - 1)) >> PAGE_SHIFT;
areasize = (size+PAGE_SIZE-1)/PAGE_SIZE;
incr = align >> PAGE_SHIFT ? : 1;
restart_scan:
for (i = preferred; i < eidx; i += incr) {
unsigned long j;
if (test_bit(i, bdata->node_bootmem_map))
continue;
for (j = i + 1; j < i + areasize; ++j) {
if (j >= eidx)
goto fail_block;
if (test_bit (j, bdata->node_bootmem_map))
goto fail_block;
}
start = i;
goto found;
fail_block:;
}
if (preferred) {
preferred = 0;
goto restart_scan;
}
found:
标号restart_scan前面都是一些准备工作,eidx是最大页面数,goal代表调用着期望从哪个地址开始扫描位图,prefferred是goal按align对齐的结果,areasize是size按页面向上取整,incr代表步长。
这个两重循环实现从preferred页开始,到eidx页为止,查找连续areasize个空闲页的功能,如果没找到,因为是从preferred开始,0-preferred这段还有可能有满足条件的内存块,所以就从头开始再来一遍。
/*
* Is the next page of the previous allocation-end the start
* of this allocation's buffer? If yes then we can 'merge'
* the previous partial page with this allocation.
*/
if (align <= PAGE_SIZE
&& bdata->last_offset && bdata->last_pos+1 == start) {
offset = (bdata->last_offset+align-1) & ~(align-1);
if (offset > PAGE_SIZE)
BUG();
remaining_size = PAGE_SIZE-offset;
if (size < remaining_size) {
areasize = 0;
// last_pos unchanged
bdata->last_offset = offset+size;
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset +
bdata->node_boot_start);
} else {
remaining_size = size - remaining_size;
areasize = (remaining_size+PAGE_SIZE-1)/PAGE_SIZE;
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset +
bdata->node_boot_start);
bdata->last_pos = start+areasize-1;
bdata->last_offset = remaining_size;
}
bdata->last_offset &= ~PAGE_MASK;
} else {
bdata->last_pos = start + areasize - 1;
bdata->last_offset = size & ~PAGE_MASK;
ret = phys_to_virt(start * PAGE_SIZE + bdata->node_boot_start);
}
/*
* Reserve the area now:
*/
for (i = start; i < start+areasize; i++)
if (test_and_set_bit(i, bdata->node_bootmem_map))
BUG();
memset(ret, 0, size);
如果对齐方式小于等于一页,并且这次要分配的内存起始页刚好是上一次分配的页+1,并且上一次的最后一页有剩余,就尝试将剩余的那些合并到这次要分配的内存块中。如果现在要分配的大小size小于上次剩下的,就直接在剩下的内存里分配,然后直接移动offset。如果size大于remain,那么从offset开始分配,设置好last_pos和新的offset供下次使用。
如果不满足合并的条件就老老实实按照之前计算的结果分配内存,并设置好last_pos和新的offset供下次使用。
free_bootmem
释放bootmem分配的内存就简单很多,直接将调用者传入的地址参数按页向上取整,然后根据size计算出需要释放多少个页面,将他们对应的bitmap清0就可以了
static void __init free_bootmem_core(bootmem_data_t *bdata, unsigned long addr, unsigned long size)
{
unsigned long i;
unsigned long start;
/*
* round down end of usable mem, partially free pages are
* considered reserved.
*/
unsigned long sidx;
unsigned long eidx = (addr + size - bdata->node_boot_start)/PAGE_SIZE;
unsigned long end = (addr + size)/PAGE_SIZE;
if (!size) BUG();
if (end > bdata->node_low_pfn)
BUG();
/*
* Round up the beginning of the address.
*/
start = (addr + PAGE_SIZE-1) / PAGE_SIZE;
sidx = start - (bdata->node_boot_start/PAGE_SIZE);
for (i = sidx; i < eidx; i++) {
if (!test_and_clear_bit(i, bdata->node_bootmem_map))
BUG();
}
}
伙伴系统初始化
物理内存从供给的角度管理内存,将一个节点中的所有内存分为最多3个zone,dma,normal,high memory
一些老的硬件设备,比如ISA总线设备要求dma的物理地址不能高于16M,所以低16M的空间被划分为zone_dma
linux将虚拟地址的0xC0000000开始到0xFFFFFFFF的1G空间划分为系统空间,而物理地址总是从最低的0开始的,所以系统空间到物理地址的映射就变成了简单的线性关系,而高于1G的物理地址空间则不能直接映射到内核,所以1G以上的物理地址空间被划分为zone_highmem,而为了能够访问全部的物理地址空间,内核又在normal中预留了一部分空间用来临时的映射highmem,那就是vmalloc的128M,所以从896M开始的部分都被划分为了zone_highmem。
伙伴算法的初始化主要就是对内存节点中各个zone的管理结构的初始化
typedef struct zone_struct {
/*
* Commonly accessed fields:
*/
spinlock_t lock;
unsigned long offset;
unsigned long free_pages;
unsigned long inactive_clean_pages;
unsigned long inactive_dirty_pages;
unsigned long pages_min, pages_low, pages_high;
/*
* free areas of different sizes
*/
struct list_head inactive_clean_list;
free_area_t free_area[MAX_ORDER];
/*
* rarely used fields:
*/
char *name;
unsigned long size;
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
struct page *zone_mem_map;
} zone_t;
offset是当前管理区在mem_map中的起始页面号,free_area[i]是一组链表,用来将连续页面数为2i的页面块链接成链,相邻的两个页面块互为伙伴,并且用一个位图map中的一个bit来管理这两个伙伴,bit为1表示可以合并伙伴。
伙伴系统的初始化主要就是初始化这些zone结构以及将空闲页面链入相应的free_area,并且初始化全局的mem_map。
start_kernel–>setup_arch–>paging_init完成了这个工作,并干掉了自举分配器,一切都将步入正轨。
void __init paging_init(void)
{
pagetable_init();
__asm__( "movl %%ecx,%%cr3\n" ::"c"(__pa(swapper_pg_dir)));
#if CONFIG_X86_PAE
/*
* We will bail out later - printk doesnt work right now so
* the user would just see a hanging kernel.
*/
if (cpu_has_pae)
set_in_cr4(X86_CR4_PAE);
#endif
__flush_tlb_all();
#ifdef CONFIG_HIGHMEM
kmap_init();
#endif
{
unsigned long zones_size[MAX_NR_ZONES] = {0, 0, 0};
unsigned int max_dma, high, low;
max_dma = virt_to_phys((char *)MAX_DMA_ADDRESS) >> PAGE_SHIFT;
low = max_low_pfn;
high = highend_pfn;
if (low < max_dma)
zones_size[ZONE_DMA] = low;
else {
zones_size[ZONE_DMA] = max_dma;
zones_size[ZONE_NORMAL] = low - max_dma;
#ifdef CONFIG_HIGHMEM
zones_size[ZONE_HIGHMEM] = high - low;
#endif
}
free_area_init(zones_size);
}
return;
}
这个函数主要干了两个事情1、初始化页表,2、初始化空闲物理页面伙伴
首先看1、初始化页表
static void __init pagetable_init (void)
{
unsigned long vaddr, end;
pgd_t *pgd, *pgd_base;
int i, j, k;
pmd_t *pmd;
pte_t *pte;
/*
* This can be zero as well - no problem, in that case we exit
* the loops anyway due to the PTRS_PER_* conditions.
*/
end = (unsigned long)__va(max_low_pfn*PAGE_SIZE);
pgd_base = swapper_pg_dir;
#if CONFIG_X86_PAE
for (i = 0; i < PTRS_PER_PGD; i++) {
pgd = pgd_base + i;
__pgd_clear(pgd);
}
#endif
i = __pgd_offset(PAGE_OFFSET);
pgd = pgd_base + i;
for (; i < PTRS_PER_PGD; pgd++, i++) {
vaddr = i*PGDIR_SIZE;
if (end && (vaddr >= end))
break;
#if CONFIG_X86_PAE
pmd = (pmd_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pgd(pgd, __pgd(__pa(pmd) + 0x1));
#else
pmd = (pmd_t *)pgd;
#endif
if (pmd != pmd_offset(pgd, 0))
BUG();
for (j = 0; j < PTRS_PER_PMD; pmd++, j++) {
vaddr = i*PGDIR_SIZE + j*PMD_SIZE;
if (end && (vaddr >= end))
break;
if (cpu_has_pse) {
unsigned long __pe;
set_in_cr4(X86_CR4_PSE);
boot_cpu_data.wp_works_ok = 1;
__pe = _KERNPG_TABLE + _PAGE_PSE + __pa(vaddr);
/* Make it "global" too if supported */
if (cpu_has_pge) {
set_in_cr4(X86_CR4_PGE);
__pe += _PAGE_GLOBAL;
}
set_pmd(pmd, __pmd(__pe));
continue;
}
pte = (pte_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pmd(pmd, __pmd(_KERNPG_TABLE + __pa(pte)));
if (pte != pte_offset(pmd, 0))
BUG();
for (k = 0; k < PTRS_PER_PTE; pte++, k++) {
vaddr = i*PGDIR_SIZE + j*PMD_SIZE + k*PAGE_SIZE;
if (end && (vaddr >= end))
break;
*pte = mk_pte_phys(__pa(vaddr), PAGE_KERNEL);
}
}
}
/*
* Fixed mappings, only the page table structure has to be
* created - mappings will be set by set_fixmap():
*/
vaddr = __fix_to_virt(__end_of_fixed_addresses - 1) & PMD_MASK;
fixrange_init(vaddr, 0, pgd_base);
#if CONFIG_HIGHMEM
/*
* Permanent kmaps:
*/
vaddr = PKMAP_BASE;
fixrange_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + __pgd_offset(vaddr);
pmd = pmd_offset(pgd, vaddr);
pte = pte_offset(pmd, vaddr);
pkmap_page_table = pte;
#endif
#if CONFIG_X86_PAE
/*
* Add low memory identity-mappings - SMP needs it when
* starting up on an AP from real-mode. In the non-PAE
* case we already have these mappings through head.S.
* All user-space mappings are explicitly cleared after
* SMP startup.
*/
pgd_base[0] = pgd_base[USER_PTRS_PER_PGD];
#endif
}
整体就是在给各级页表分配空间,并建立映射,这些表中存储的内容都是物理地址。
2、初始化伙伴系统
{
unsigned long zones_size[MAX_NR_ZONES] = {0, 0, 0};
unsigned int max_dma, high, low;
max_dma = virt_to_phys((char *)MAX_DMA_ADDRESS) >> PAGE_SHIFT;
low = max_low_pfn;
high = highend_pfn;
if (low < max_dma)
zones_size[ZONE_DMA] = low;
else {
zones_size[ZONE_DMA] = max_dma;
zones_size[ZONE_NORMAL] = low - max_dma;
#ifdef CONFIG_HIGHMEM
zones_size[ZONE_HIGHMEM] = high - low;
#endif
}
free_area_init(zones_size);
}
首先设置zones_size,代表各个zone中的物理页面数量,然后free_area_init会将各个zone中的页面全部链接入他们的空闲区域frea_area[order]。
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*/
void __init free_area_init_core(int nid, pg_data_t *pgdat, struct page **gmap,
unsigned long *zones_size, unsigned long zone_start_paddr,
unsigned long *zholes_size, struct page *lmem_map)
...
map_size = (totalpages + 1)*sizeof(struct page);
if (lmem_map == (struct page *)0) {
lmem_map = (struct page *) alloc_bootmem_node(pgdat, map_size);
lmem_map = (struct page *)(PAGE_OFFSET +
MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET));
}
*gmap = pgdat->node_mem_map = lmem_map;
gmap是指向全局mem_map指针的指针,通过自举分配器给mem_map分配空间,多申请一页(totalpages + 1)是为了下面将lmem_map的地址按sizeof(struct page)对齐。
接下来对每一个page的控制结构进行初始化,设置页面引用次数,初始化等待队列啥的,平平无奇。
然后是对当前控制区的一些锁,队列,和控制变量的初始化,包括分配页面时判断当前控制区页面存量压力的min,low,high三个参数的初始化。
终于来到了关键的空闲队列初始化了
mask = -1;
for (i = 0; i < MAX_ORDER; i++) {
unsigned long bitmap_size;
memlist_init(&zone->free_area[i].free_list);
mask += mask;
size = (size + ~mask) & mask;//页面数按2的i次方对齐
bitmap_size = size >> i;//连续页面块的个数,需要的bit数
bitmap_size = (bitmap_size + 7) >> 3;//需要的字节数
bitmap_size = LONG_ALIGN(bitmap_size);//需要的long的个数
zone->free_area[i].map =
(unsigned int *) alloc_bootmem_node(pgdat, bitmap_size);
}
在管理区内循环max_order次,依次初始化管理2i连续页面块的free_area list,为每个list的管理位图申请空间。
start_kernel–>mem_init清空了empty_zero_page,并调用free_all_bootmem将所有页面,包括自举分配器自身使用的页面全部链接入free_area list,至此,伙伴系统正式启动
/* clear the zero-page */
memset(empty_zero_page, 0, PAGE_SIZE);
/* this will put all low memory onto the freelists */
totalram_pages += free_all_bootmem();
free_all_bootmem
实现为free_all_bootmem_core,遍历bootmem管理的所有物理页面,将所有空闲的物理页面通过__free_page链入空闲链表,并将自举分配器的位图使用的页面回收至空闲页面链表。
__free_pages
void __free_pages(struct page *page, unsigned long order)
{
if (!PageReserved(page) && put_page_testzero(page))
__free_pages_ok(page, order);
}
主要做了__free_pages_ok,使用计数是0,并且不是保留的就可以回收
进入__free_pages_ok,进行了一串平平无奇的参数检查以后,我们进入到一段循环,开始遍历从当前order一直到最大order的free_area中是否有我要释放的这个page的伙伴,找到以后合并继续查找下一层的伙伴,没找到就推出循环,将以page为首的内存块链入当前order的free_area。
mask = (~0UL) << order;
base = mem_map + zone->offset;//这个管理区的第一个page
page_idx = page - base;//在这个管理区排老几
if (page_idx & ~mask)
BUG();
index = page_idx >> (1 + order);//在free_area.map中的位置,page_idx >> order / 2
//因为1bit管一对伙伴两个内存块,所以多除个2
area = zone->free_area + order;
spin_lock_irqsave(&zone->lock, flags);
zone->free_pages -= mask;//mask是负数,相当于增加1<<order
while (mask + (1 << (MAX_ORDER-1))) {//相当于循环max_order - order次
struct page *buddy1, *buddy2;
if (area >= zone->free_area + MAX_ORDER)//越界了
BUG();
if (!test_and_change_bit(index, area->map))//测试并取反,返回取反前的值
//返回0表示伙伴丢了,不在家,我们在这等
//他就行了
/*
* the buddy page is still allocated.
*/
break;
/*
* Move the buddy up one level.
*/
buddy1 = base + (page_idx ^ -mask);//前面那个内存块
buddy2 = base + page_idx;
if (BAD_RANGE(zone,buddy1))
BUG();
if (BAD_RANGE(zone,buddy2))
BUG();
memlist_del(&buddy1->list);
mask <<= 1;
area++;
index >>= 1;
page_idx &= mask;
}
memlist_add_head(&(base + page_idx)->list, &area->free_list);//回家了,等人叫走,或者
//等伙伴回来
物理页面的分配
alloc_pages
当一个进程需要分配若干连续的物理页面时,可通过alloc_pages()完成,linux2.4.0的代码有两个alloc_pages,一个在mm/numa.c,一个在mm/page_alloc.c。
用于NUMA结构的alloc_pages():
struct page * alloc_pages(int gfp_mask, unsigned long order)
{
struct page *ret = 0;
pg_data_t *start, *temp;
#ifndef CONFIG_NUMA
unsigned long flags;
static pg_data_t *next = 0;
#endif
if (order >= MAX_ORDER)
return NULL;
#ifdef CONFIG_NUMA
temp = NODE_DATA(numa_node_id());
#else
spin_lock_irqsave(&node_lock, flags);
if (!next) next = pgdat_list;
temp = next;
next = next->node_next;
spin_unlock_irqrestore(&node_lock, flags);
#endif
start = temp;
while (temp) {
if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
return(ret);
temp = temp->node_next;
}
temp = pgdat_list;
while (temp != start) {
if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
return(ret);
temp = temp->node_next;
}
return(0);
}
next是个静态变量,保存着上一次分配到哪一个node,gfp_mask是个整数,表示使用哪个分配策略,即node_zonelists的索引,order表示所需物理块的大小,2order个页面。
函数的两个while循环先从节点链表的temp开始扫描到链表结束,然后从链表开头扫描到temp,直到节点内分配成功,或者全部失败返回0。
每个节点内的分配由__alloc_pages实现:
static struct page * alloc_pages_pgdat(pg_data_t *pgdat, int gfp_mask,
unsigned long order)
{
return __alloc_pages(pgdat->node_zonelists + gfp_mask, order);
}
连续空间uma结构的alloc_pages则直接调用了__alloc_pages:
static inline struct page * alloc_pages(int gfp_mask, unsigned long order)
{
/*
* Gets optimized away by the compiler.
*/
if (order >= MAX_ORDER)
return NULL;
return __alloc_pages(contig_page_data.node_zonelists+(gfp_mask), order);
}
__alloc_pages
/*
* This is the 'heart' of the zoned buddy allocator:
*/
struct page * __alloc_pages(zonelist_t *zonelist, unsigned long order)
{
zone_t **zone;
int direct_reclaim = 0;
unsigned int gfp_mask = zonelist->gfp_mask;
struct page * page;
/*
* Allocations put pressure on the VM subsystem.
*/
memory_pressure++;
/*
* (If anyone calls gfp from interrupts nonatomically then it
* will sooner or later tripped up by a schedule().)
*
* We are falling back to lower-level zones if allocation
* in a higher zone fails.
*/
/*
* Can we take pages directly from the inactive_clean
* list?
*/
if (order == 0 && (gfp_mask & __GFP_WAIT) &&
!(current->flags & PF_MEMALLOC))
direct_reclaim = 1;
/*
* If we are about to get low on free pages and we also have
* an inactive page shortage, wake up kswapd.
*/
if (inactive_shortage() > inactive_target / 2 && free_shortage())
wakeup_kswapd(0);
/*
* If we are about to get low on free pages and cleaning
* the inactive_dirty pages would fix the situation,
* wake up bdflush.
*/
else if (free_shortage() && nr_inactive_dirty_pages > free_shortage()
&& nr_inactive_dirty_pages >= freepages.high)
wakeup_bdflush(0);
memory_pressure表示内存页面管理受到的压力,分配页面时递增,归还时递减。gfp_mask来自于具体分配策略的控制结构,是一些标志位。
如果需求是单个页面,并且需要等待分配完成,并且不是出于管理目的则direct_reclaim = 1,表示可以从不活跃干净页面的缓冲队列中回收,这些页面已经将内容写出至交换设备或者文件中,只是内容保留下来,方便下次使用这个页面时可以简单直接的使用,而这些页面不见得连续,所以只有需要单个页面的时候允许从这些页面中回收。
当可分配页面短缺时(inactive_shortage()/free_shortage()),唤醒kswap和bdflush两个线程设法腾出一些页面来。
try_again:
/*
* First, see if we have any zones with lots of free memory.
*
* We allocate free memory first because it doesn't contain
* any data ... DUH!
*/
zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
if (!z->size)
BUG();
if (z->free_pages >= z->pages_low) {
page = rmqueue(z, order);
if (page)
return page;
} else if (z->free_pages < z->pages_min &&
waitqueue_active(&kreclaimd_wait)) {
wake_up_interruptible(&kreclaimd_wait);
}
}
首先按照既定策略扫描管理区(策略在调用函数时确定,参数zonelist为选中的管理区数组),如果管理区的空闲页面足够(>=pages_low),就调用rmqueue尝试从当前管理区分配页面;如果空闲页面在低水平以下,并且kreclaimd线程在等待队列中,就唤醒他让他会帮忙回收一些页面备用。
rmqueue
函数rmqueue()尝试从一个管理区中分配若干连续的页面:
static struct page * rmqueue(zone_t *zone, unsigned long order)
{
free_area_t * area = zone->free_area + order;
unsigned long curr_order = order;
struct list_head *head, *curr;
unsigned long flags;
struct page *page;
spin_lock_irqsave(&zone->lock, flags);
do {
head = &area->free_list;
curr = memlist_next(head);
if (curr != head) {
unsigned int index;
page = memlist_entry(curr, struct page, list);
if (BAD_RANGE(zone,page))
BUG();
memlist_del(curr);
index = (page - mem_map) - zone->offset;
MARK_USED(index, curr_order, area);//设置伙伴位图
zone->free_pages -= 1 << order;
page = expand(zone, page, index, order, curr_order, area);
spin_unlock_irqrestore(&zone->lock, flags);
set_page_count(page, 1);
if (BAD_RANGE(zone,page))
BUG();
DEBUG_ADD_PAGE
return page;
}
curr_order++;
area++;
} while (curr_order < MAX_ORDER);
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
zone->free_area + order 指向了所需页面大小的空闲管理队列,如果这个队列中没有可分配的页面块,则尝试更大的内存块管理队列(curr_order++, area++)。若分配成功的话调用expand尝试将当前内存块剩余的内存页面(2curr_oder-2order)分解成小块,并链入相应队列。
static inline struct page * expand (zone_t *zone, struct page *page,
unsigned long index, int low, int high, free_area_t * area)
{
unsigned long size = 1 << high;
while (high > low) {
if (BAD_RANGE(zone,page))
BUG();
area--;//下一当空闲队列
high--;//order-1
size >>= 1;//也就是2的high-1次方
memlist_add_head(&(page)->list, &(area)->free_list);
MARK_USED(index, high, area);//设置位图
index += size;//位图索引
page += size;
}
if (BAD_RANGE(zone,page))
BUG();
return page;
}
high位当点空闲队列的order,low是分配走的页面数的order,size为当前内存块的页面总数,循环中,每次将size的一半链入低一档的空闲队列中,并设置相应的位图,最终必有high==low结束循环,刚好处理完所有剩余的内存页面。
如果rmqueue分配失败,就通过前面的for循环尝试下一个zones,若所有zones都失败,就得继续加大分配的力度了,首先降低管理区的低水平限制,并且允许的话尝试通过reclaim来回收页面,那就是__alloc_pages_limit
__alloc_pages_limit
/*
* Try to allocate a page from a zone with a HIGH
* amount of free + inactive_clean pages.
*
* If there is a lot of activity, inactive_target
* will be high and we'll have a good chance of
* finding a page using the HIGH limit.
*/
page = __alloc_pages_limit(zonelist, order, PAGES_HIGH, direct_reclaim);
if (page)
return page;
/*
* Then try to allocate a page from a zone with more
* than zone->pages_low free + inactive_clean pages.
*
* When the working set is very large and VM activity
* is low, we're most likely to have our allocation
* succeed here.
*/
page = __alloc_pages_limit(zonelist, order, PAGES_LOW, direct_reclaim);
if (page)
return page;
/*
* OK, none of the zones on our zonelist has lots
* of pages free.
*
* We wake up kswapd, in the hope that kswapd will
* resolve this situation before memory gets tight.
*
* We also yield the CPU, because that:
* - gives kswapd a chance to do something
* - slows down allocations, in particular the
* allocations from the fast allocator that's
* causing the problems ...
* - ... which minimises the impact the "bad guys"
* have on the rest of the system
* - if we don't have __GFP_IO set, kswapd may be
* able to free some memory we can't free ourselves
*/
wakeup_kswapd(0);
if (gfp_mask & __GFP_WAIT) {
__set_current_state(TASK_RUNNING);
current->policy |= SCHED_YIELD;
schedule();
}
/*
* After waking up kswapd, we try to allocate a page
* from any zone which isn't critical yet.
*
* Kswapd should, in most situations, bring the situation
* back to normal in no time.
*/
page = __alloc_pages_limit(zonelist, order, PAGES_MIN, direct_reclaim);
if (page)
return page;
通过传递参数limit逐步降低管理区的低水位要求,来增加分配成功的可能性,并且允许的话通过reclaim来回收一些干净的页面。
/*
* This function does the dirty work for __alloc_pages
* and is separated out to keep the code size smaller.
* (suggested by Davem at 1:30 AM, typed by Rik at 6 AM)
*/
static struct page * __alloc_pages_limit(zonelist_t *zonelist,
unsigned long order, int limit, int direct_reclaim)
{
zone_t **zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
unsigned long water_mark;
if (!z)
break;
if (!z->size)
BUG();
/*
* We allocate if the number of free + inactive_clean
* pages is above the watermark.
*/
switch (limit) {
default:
case PAGES_MIN:
water_mark = z->pages_min;
break;
case PAGES_LOW:
water_mark = z->pages_low;
break;
case PAGES_HIGH:
water_mark = z->pages_high;
}
if (z->free_pages + z->inactive_clean_pages > water_mark) {
struct page *page = NULL;
/* If possible, reclaim a page directly. */
if (direct_reclaim && z->free_pages < z->pages_min + 8)
page = reclaim_page(z);
/* If that fails, fall back to rmqueue. */
if (!page)
page = rmqueue(z, order);
if (page)
return page;
}
}
/* Found nothing. */
return NULL;
}
首先根据接收的limit来设置water_mark,用来给管理区保留一些页面以应对某些紧急情况。如果可供分配的页面依然小于water_mark,那没办法只能返回NULL表示没有分配失败了;否则先判断是否可以从不活跃干净的页面直接回收页面以分配,一是要允许回收(单个页面),二是空闲页面确实太少,毕竟不活跃干净的页面的内容是给别人准备的(换出到交换设备的页面再次启用,就可以不用读取了),只有不得已的情况才会挪作他用。若不能回收,则直接尝试rmqueque来分配页面。
如果还是失败的话,那就真的是空闲页面短缺到一定程度了,这时候可能真的是页面总量不够,还有可能是页面总量是够的,但是页面块的大小不满足要求,也就是有很多零散的小的页面块,这时候可能有些页面是不活跃的,就是没有人在用的,但是他们在不活跃干净的和不活跃脏的队列中,此时内核就考虑做两件事情,将脏的洗干净和将干净的释放,这样就又能获得一些可供分配的页面了。
首先调用page_launder洗白页面,这个函数的功能就是将inactive_dirty_pages中的页面洗干净,链入inactive_clean_pages中,函数实现两趟遍历,第一遍将所有脏的页面放到队列结尾,并将干净的页面链入对应管理区的inactive_clean_pages,第二趟将能写出到交换设备的页面全部写出洗白,但是并没有将他们链入inactive_clean_pages,所以inactive_clean_pages中多了第一趟处理的那么多页面。
然后开始循环遍历各个管理区,回收并释放那些干净的页面:
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
if (!z->size)
continue;
while (z->inactive_clean_pages) {
struct page * page;
/* Move one page to the free list. */
page = reclaim_page(z);
if (!page)
break;
__free_page(page);
/* Try if the allocation succeeds. */
page = rmqueue(z, order);
if (page)
return page;
}
while循环中,一个一个的回收并释放干净的页面,每释放一个页面,就尝试分配一次,直到inactive_clean_pages为空或者分配成功。
reclaim_page负责将一个干净的页面从inactive_clean_pages中释放出来,__free_page负责将这个页面回收到伙伴系统中以供分配时用。
如果这时候还是失败,那么就可能真的是页面总数不够了,此时需要唤醒kswapd或者直接调用try_to_free_pages来释放到岁数的页面。如果请求的是单个页面的话,回到开头,重新尝试以下。
最后,如果是PF_MEMALLOC(出于内存管理的目的)或者需求是成块内存的需求,__alloc_pages将最后一次放宽自己的老本,分配所有自己能分配的页面:
/*
* Final phase: allocate anything we can!
*
* Higher order allocations, GFP_ATOMIC allocations and
* recursive allocations (PF_MEMALLOC) end up here.
*
* Only recursive allocations can use the very last pages
* in the system, otherwise it would be just too easy to
* deadlock the system...
*/
zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
struct page * page = NULL;
if (!z)
break;
if (!z->size)
BUG();
/*
* SUBTLE: direct_reclaim is only possible if the task
* becomes PF_MEMALLOC while looping above. This will
* happen when the OOM killer selects this task for
* instant execution...
*/
if (direct_reclaim) {
page = reclaim_page(z);
if (page)
return page;
}
/* XXX: is pages_min/4 a good amount to reserve for this? */
if (z->free_pages < z->pages_min / 4 &&
!(current->flags & PF_MEMALLOC))//不是PF_MEMALLOC的时候还是保留了一丢丢,就是给PF_MEMALLOC预留的吧
continue;
page = rmqueue(z, order);
if (page)
return page;
}
slab
内核中有很多地方需要动态申请和释放的小的存储空间,例如进程控制块的结构task_struct,而不同的结构需要的空间是不同的,并且他们都远远小于一个页面的大小(page_size),如果每申请一个小块内存就分配一个页面的话,将极大的造成浪费,所以,内核采用了slab缓冲队列的管理办法。
在slab队列中每种结构都有自己专用的缓冲区队列,队列中的的每个对象(obj)都是一个结构,每个slab可以由1,2,4,8…32个页面构成。每个slab都有一个用于管理的描述结构,描述结构可能存放在slab的开头(小slab),也有可能单独存放在其他地方(大slab):
/*
* slab_t
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into one ordered list: fully used, partial, then fully
* free slabs.
*/
typedef struct slab_s {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
} slab_t;
用于同一种对象的slab通过控制结构中的队列头list形成一条双向链表。s_mem指向第一个对象。
colouroff是slab中一个称为着色区的区域的偏移,着色区的设计是为了使slab中对象的起始地址都能按照高速缓存的缓冲行对齐,并且不同slab上同一相对位置的对象起始地址在高速缓存中错开,以提高高速缓存的效率。slab中的对象大小如果不与高速缓存的缓冲行对齐,还会对其进行补齐。所以slab上的所有对象都是按缓冲行对齐的。
inuse表示slab中正在使用的对象数目,free是空闲链接数组的索引,空闲链接数组紧挨着描述结构,所以空闲数组的访问方式slab_bufctl(slabp)[free]:
#define slab_bufctl(slabp) \
((kmem_bufctl_t *)(((slab_t*)slabp)+1))
每种对象的slab队列都有一个头部,他的结构是k_mem_cache_t
struct kmem_cache_s {
/* 1) each alloc & free */
/* full, partial first, then free */
struct list_head slabs;
struct list_head *firstnotfull;
unsigned int objsize;
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
spinlock_t spinlock;
#ifdef CONFIG_SMP
unsigned int batchcount;
#endif
/* 2) slab additions /removals */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
unsigned int gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
unsigned int colour_next; /* cache colouring */
kmem_cache_t *slabp_cache;
unsigned int growing;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
void (*dtor)(void *, kmem_cache_t *, unsigned long);
unsigned long failures;
/* 3) cache creation/removal */
char name[CACHE_NAMELEN];
struct list_head next;
#ifdef CONFIG_SMP
/* 4) per-cpu data */
cpucache_t *cpudata[NR_CPUS];
#endif
#if STATS
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
#ifdef CONFIG_SMP
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#endif
#endif
};
slabs是k_mem_cache_t管理的slab队列,firstnotfull指向第一个有空闲对象的slab,colour是每个slab着色区总大小,colour_next = curr_colour + colour_off。slabp_cache是大对象的描述结构的管理队列。
内核中有一个总的slab队列,其头部也是一个k_mem_cache_t,名字叫做cache_cache。cache_cache的slabs是一个管理k_mem_cache_t对象的slab队列,这里面的每一个k_mem_cache_t的slabs又分别管理以一种特定数据结构为对象的slab队列,这样就形成了整个slab缓冲队列的管理结构。
cache_cache初始化
首先全局的cache_cache队列由内核在start_kernel->kmem_cache_init()中初始化:
/* internal cache of cache description objs */
static kmem_cache_t cache_cache = {
slabs: LIST_HEAD_INIT(cache_cache.slabs),
firstnotfull: &cache_cache.slabs,
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES,
name: "kmem_cache",
};
/* Initialisation - setup the `cache' cache. */
void __init kmem_cache_init(void)
{
size_t left_over;
init_MUTEX(&cache_chain_sem);
INIT_LIST_HEAD(&cache_chain);
kmem_cache_estimate(0, cache_cache.objsize, 0,
&left_over, &cache_cache.num);
if (!cache_cache.num)
BUG();
cache_cache.colour = left_over/cache_cache.colour_off;
cache_cache.colour_next = 0;
}
left_over是剩下的字节数,处以off得到colour总数
/* Cal the num objs, wastage, and bytes left over for a given slab size. */
static void kmem_cache_estimate (unsigned long gfporder, size_t size,
int flags, size_t *left_over, unsigned int *num)
{
int i;
size_t wastage = PAGE_SIZE<<gfporder;
size_t extra = 0;
size_t base = 0;
if (!(flags & CFLGS_OFF_SLAB)) {
base = sizeof(slab_t);
extra = sizeof(kmem_bufctl_t);
}
i = 0;
while (i*size + L1_CACHE_ALIGN(base+i*extra) <= wastage)
i++;
if (i > 0)
i--;
if (i > SLAB_LIMIT)
i = SLAB_LIMIT;
*num = i;
wastage -= i*size;
wastage -= L1_CACHE_ALIGN(base+i*extra);
*left_over = wastage;
}
计算order个页面能存放多少个对象,小对象的话需要减去描述结构和链接数组的大小,大对象则不需要。并且至少留一个对象大小的区域当作着色区(i–),最终剩余字节数位left_over当作着色区使用。
专用缓冲队列的建立
当需要一个专用缓冲队列时,就通过调用kmem_cache_create建立,这个函数定义在mm/slab.c中,
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t offset,
unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
{
...
/* Get cache's description obj. */
cachep = (kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
if (!cachep)
goto opps;
memset(cachep, 0, sizeof(kmem_cache_t));
首先kmem_cache_alloc获得一个slab的队列头:
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
return __kmem_cache_alloc(cachep, flags);
}
static inline void * __kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
unsigned long save_flags;
void* objp;
...
objp = kmem_cache_alloc_one(cachep);
#endif
local_irq_restore(save_flags);
return objp;
alloc_new_slab:
#ifdef CONFIG_SMP
spin_unlock(&cachep->spinlock);
alloc_new_slab_nolock:
#endif
local_irq_restore(save_flags);
if (kmem_cache_grow(cachep, flags))
/* Someone may have stolen our objs. Doesn't matter, we'll
* just come back here again.
*/
goto try_again;
return NULL;
}
/*
* Returns a ptr to an obj in the given cache.
* caller must guarantee synchronization
* #define for the goto optimization 8-)
*/
#define kmem_cache_alloc_one(cachep) \
({ \
slab_t *slabp; \
\
/* Get slab alloc is to come from. */ \
{ \
struct list_head* p = cachep->firstnotfull; \
if (p == &cachep->slabs) \
goto alloc_new_slab; \
slabp = list_entry(p,slab_t, list); \
} \
kmem_cache_alloc_one_tail(cachep, slabp); \
})
可以看到,首先__kmem_cache_alloc通过kmem_cache_alloc_one试图在cache_cache中找到一个空闲的kmem_cache_t对象。如果firstnotfull指向了slabs,就说明slab队列已空,回到__kmem_cache_alloc去alloc一个新的slab。如果找到了由kmem_cache_alloc_one_tail进一步从这个slab里分配一个对象,并返回其指针。
static inline void * kmem_cache_alloc_one_tail (kmem_cache_t *cachep,
slab_t *slabp)
{
void *objp;
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
/* get obj pointer */
slabp->inuse++;
objp = slabp->s_mem + slabp->free*cachep->objsize;
slabp->free=slab_bufctl(slabp)[slabp->free];
if (slabp->free == BUFCTL_END)
/* slab now full: move to next slab for next alloc */
cachep->firstnotfull = slabp->list.next;
#if DEBUG
if (cachep->flags & SLAB_POISON)
if (kmem_check_poison_obj(cachep, objp))
BUG();
if (cachep->flags & SLAB_RED_ZONE) {
/* Set alloc red-zone, and check old one. */
if (xchg((unsigned long *)objp, RED_MAGIC2) !=
RED_MAGIC1)
BUG();
if (xchg((unsigned long *)(objp+cachep->objsize -
BYTES_PER_WORD), RED_MAGIC2) != RED_MAGIC1)
BUG();
objp += BYTES_PER_WORD;
}
#endif
return objp;
}
free是对象的序号s_mem是第一个对象开始的地方,所以s_mem加上free个objsize就找到了可分配对象的地址。
slab_bufctl(slabp)宏定义帮助我们找到空闲链接数组,空闲数组的内容均为整数,是下一个空闲对象的序号,所以以free为下标的数组元素即为下一个free的对象序号。
回头看slabs为空的情况,即slabs中没有空闲对象存在,则需要回到__kmem_cache_alloc,去alloc一个新的slab,并链接到slabs上,然后回到开头try_again,这样就必有fistnotfull不等于slabs了。
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int kmem_cache_grow (kmem_cache_t * cachep, int flags)
{
...
/* Get colour for the slab, and cal the next value. */
offset = cachep->colour_next;
cachep->colour_next++;
if (cachep->colour_next >= cachep->colour)
cachep->colour_next = 0;
offset *= cachep->colour_off;
cachep->dflags |= DFLGS_GROWN;
cachep->growing++;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
/* A series of memory allocations for a new slab.
* Neither the cache-chain semaphore, or cache-lock, are
* held, but the incrementing c_growing prevents this
* cache from being reaped or shrunk.
* Note: The cache could be selected in for reaping in
* kmem_cache_reap(), but when the final test is made the
* growing value will be seen.
*/
/* Get mem for the objs. */
if (!(objp = kmem_getpages(cachep, flags)))
goto failed;
/* Get slab management. */
if (!(slabp = kmem_cache_slabmgmt(cachep, objp, offset, local_flags)))
goto opps1;
/* Nasty!!!!!! I hope this is OK. */
i = 1 << cachep->gfporder;
page = virt_to_page(objp);
do {
SET_PAGE_CACHE(page, cachep);
SET_PAGE_SLAB(page, slabp);
PageSetSlab(page);
page++;
} while (--i);
kmem_cache_init_objs(cachep, slabp, ctor_flags);
spin_lock_irqsave(&cachep->spinlock, save_flags);
cachep->growing--;
/* Make slab active. */
list_add_tail(&slabp->list,&cachep->slabs);
if (cachep->firstnotfull == &cachep->slabs)
cachep->firstnotfull = &slabp->list;
STATS_INC_GROWN(cachep);
cachep->failures = 0;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
spin_lock_irqsave(&cachep->spinlock, save_flags);
cachep->growing--;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
return 0;
}
首先计算着色区大小,colour_next(当大于colour时重新从0开始)*colour_off。然后给slab申请内存页面,kmem_getpages实际就是调用__get_free_pages向伙伴系统申请若干页面。
然后设置slab的描述结构:
/* Get the memory for a slab management obj. */
static inline slab_t * kmem_cache_slabmgmt (kmem_cache_t *cachep,
void *objp, int colour_off, int local_flags)
{
slab_t *slabp;
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
slabp = kmem_cache_alloc(cachep->slabp_cache, local_flags);
if (!slabp)
return NULL;
} else {
/* FIXME: change to
slabp = objp
* if you enable OPTIMIZE
*/
slabp = objp+colour_off;//描述结构在着色区后面
colour_off += L1_CACHE_ALIGN(cachep->num *
sizeof(kmem_bufctl_t) + sizeof(slab_t));//描述结构和链接数组的长度
}
slabp->inuse = 0;
slabp->colouroff = colour_off;//大对象的话,就是着色区,小对象则是描述结构和链接数组的长度
slabp->s_mem = objp+colour_off;//总是指向第一个对象的首地址
return slabp;
}
如果是大slab,则需要在slab_cache中申请一个对象来存储slab的描述结构,否则的话,将描述结构放在当前slab的开头着色区的后面。参数obj是存储当前slab的首地址,首先要有一个着色区,然后是描述结构,然后是空闲对象链接数组,然后才是s_mem对象区的首地址。
因为以obj为首的这2order个页面被slab缓冲区使用,所以设置这些页面的page结构中的PG_slab标志位,表明其用途,并且由于page被用于slab,所以其lru队列不再需要(原来是用来将页面链入不活跃干净页面等lru队列的),所以将lru的两个指针用于指向page所属的slab和slab队列头。
然后调用kmem_cache_init_objs初始化slab中对象:
static inline void kmem_cache_init_objs (kmem_cache_t * cachep,
slab_t * slabp, unsigned long ctor_flags)
{
int i;
for (i = 0; i < cachep->num; i++) {
void* objp = slabp->s_mem+cachep->objsize*i;
#if DEBUG
if (cachep->flags & SLAB_RED_ZONE) {
*((unsigned long*)(objp)) = RED_MAGIC1;
*((unsigned long*)(objp + cachep->objsize -
BYTES_PER_WORD)) = RED_MAGIC1;
objp += BYTES_PER_WORD;
}
#endif
/*
* Constructors are not allowed to allocate memory from
* the same cache which they are a constructor for.
* Otherwise, deadlock. They must also be threaded.
*/
if (cachep->ctor)
cachep->ctor(objp, cachep, ctor_flags);
#if DEBUG
if (cachep->flags & SLAB_RED_ZONE)
objp -= BYTES_PER_WORD;
if (cachep->flags & SLAB_POISON)
/* need to poison the objs */
kmem_poison_obj(cachep, objp);
if (cachep->flags & SLAB_RED_ZONE) {
if (*((unsigned long*)(objp)) != RED_MAGIC1)
BUG();
if (*((unsigned long*)(objp + cachep->objsize -
BYTES_PER_WORD)) != RED_MAGIC1)
BUG();
}
#endif
slab_bufctl(slabp)[i] = i+1;
}
slab_bufctl(slabp)[i-1] = BUFCTL_END;
slabp->free = 0;
}
如果说缓冲区定义了构建函数,那么调用构建函数(ctor)初始化对象的内容,没有的话就直接在空闲对象链接数组中将所有对象设置成free。
最后将准备好的slab链接入管理结构的slabs中。
static int kmem_cache_grow (kmem_cache_t * cachep, int flags)
{
...
/* Make slab active. */
list_add_tail(&slabp->list,&cachep->slabs);
if (cachep->firstnotfull == &cachep->slabs)
cachep->firstnotfull = &slabp->list;
...
}
此时再返回__kmem_cache_alloc的开头try_again就一定能够分配成功了。
给cache_cache分配了对象(缓冲队列的控制头kmem_cache_t)以后,先判断对象的大小来决定是大slab还是小slab,此外若size小于对齐方式的一半,则将对齐长度减半,并将size按align对齐,这样可以使缓冲行的使用更加紧凑。
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t offset,
unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
{
...
/* Determine if the slab management is 'on' or 'off' slab. */
if (size >= (PAGE_SIZE>>3))
/*
* Size is large, assume best to place the slab management obj
* off-slab (should allow better packing of objs).
*/
flags |= CFLGS_OFF_SLAB;
if (flags & SLAB_HWCACHE_ALIGN) {
/* Need to adjust size so that objs are cache aligned. */
/* Small obj size, can get at least two per cache line. */
/* FIXME: only power of 2 supported, was better */
while (size < align/2)
align /= 2;
size = (size+align-1)&(~(align-1));
}
...
}
然后通过一个循环为缓冲区队列找到一个合适的order,使得预留的着色区大小小于一个页面的八分之一,然后一顿设置缓冲队列的控制结构,并将它链入cache_cache这样,一个空的缓冲区队列就建立完成了。
到了要使用某个结构,需要从缓冲区分配一个对象时,则像给cache_cache分配对象一样直接调用kmem_cache_alloc,而发现缓冲区中没有对象时,则调用kmem_cache_grow,就可以无中生有,根据缓冲区的控制结构的内容,从伙伴算法分配出来若干页面,给缓冲区队列扩展出一个slab出来,并将其中的第一个free的对象返回了。
kmalloc
直接上代码,mm/slab.c
void * kmalloc (size_t size, int flags)
{
cache_sizes_t *csizep = cache_sizes;
for (; csizep->cs_size; csizep++) {
if (size > csizep->cs_size)
continue;
return __kmem_cache_alloc(flags & GFP_DMA ?
csizep->cs_dmacachep : csizep->cs_cachep, flags);
}
BUG(); // too big size
return NULL;
}
经过前面对cache_cache的研究,再看kmalloc的实现可以发现,kmalloc起始就是在一个对象大小大于size的缓冲区队列中分配一个对象。
首先cache_sizes是一个静态的全局数组
/* Size description struct for general caches. */
typedef struct cache_sizes {
size_t cs_size;
kmem_cache_t *cs_cachep;
kmem_cache_t *cs_dmacachep;
} cache_sizes_t;
static cache_sizes_t cache_sizes[] = {
#if PAGE_SIZE == 4096
{ 32, NULL, NULL},
#endif
{ 64, NULL, NULL},
{ 128, NULL, NULL},
{ 256, NULL, NULL},
{ 512, NULL, NULL},
{ 1024, NULL, NULL},
{ 2048, NULL, NULL},
{ 4096, NULL, NULL},
{ 8192, NULL, NULL},
{ 16384, NULL, NULL},
{ 32768, NULL, NULL},
{ 65536, NULL, NULL},
{131072, NULL, NULL},
{ 0, NULL, NULL}
};
数组元素是一个结构,其中cs_size代表对象大小,cache_sizes[i].cs_size被初始化为2i+5,cs_cachep和cs_dmacachep分别对应普通的和用于dma的缓冲区队列,均被初始化为NULL。
cache_sizes的缓冲区队列是在start_kernel的kmem_cache_sizes_init()中实现的
/* Initialisation - setup remaining internal and general caches.
* Called after the gfp() functions have been enabled, and before smp_init().
*/
void __init kmem_cache_sizes_init(void)
{
cache_sizes_t *sizes = cache_sizes;
char name[20];
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory.
*/
if (num_physpages > (32 << 20) >> PAGE_SHIFT)
slab_break_gfp_order = BREAK_GFP_ORDER_HI;
do {
/* For performance, all the general caches are L1 aligned.
* This should be particularly beneficial on SMP boxes, as it
* eliminates "false sharing".
* Note for systems short on memory removing the alignment will
* allow tighter packing of the smaller caches. */
sprintf(name,"size-%Zd",sizes->cs_size);
if (!(sizes->cs_cachep =
kmem_cache_create(name, sizes->cs_size,
0, SLAB_HWCACHE_ALIGN, NULL, NULL))) {
BUG();
}
/* Inc off-slab bufctl limit until the ceiling is hit. */
if (!(OFF_SLAB(sizes->cs_cachep))) {
offslab_limit = sizes->cs_size-sizeof(slab_t);
offslab_limit /= 2;
}
sprintf(name, "size-%Zd(DMA)",sizes->cs_size);
sizes->cs_dmacachep = kmem_cache_create(name, sizes->cs_size, 0,
SLAB_CACHE_DMA|SLAB_HWCACHE_ALIGN, NULL, NULL);
if (!sizes->cs_dmacachep)
BUG();
sizes++;
} while (sizes->cs_size);
}
看到这里基本可以明白,cache_sizes[]其实和cache_cache是一样的,只不过cache_cache以链表的形式管理缓冲区队列,只用使用时才申请,并扩展链表,而cache_sizes则以静态数组的方式管理一套通用的,没用特定结构的缓冲管理区,其对象大小为2i+5(32,64…,131072)。
所以kmalloc只是在cache_sizes中找到最小的满足分配需求的缓冲区队列,然后分配一个slab对象。
vmalloc
内核栈可以使用的虚存空间为0xC0000000-0xFFFFFFFF(1G),这1G空间对物理内存的映射关系可以简单的理解为线性映射,即虚拟内存地址=物理地址+page_offset(0xC0000000),那么问题来了,如果内核需要访问超过1G的物理内存空间该怎么办呢,vmalloc可以解决这个问题。
内核在1G虚拟空间中预留了128M给vmalloc使用,得以使内核可以访问所有的4G物理内存。
/*
* 128MB for vmalloc and initrd
*/
#define VMALLOC_RESERVE (unsigned long)(128 << 20)
#define MAXMEM (unsigned long)(-PAGE_OFFSET-VMALLOC_RESERVE)
#define MAXMEM_PFN PFN_DOWN(MAXMEM)
...
/*
* Determine low and high memory ranges:
*/
max_low_pfn = max_pfn;
if (max_low_pfn > MAXMEM_PFN) {
max_low_pfn = MAXMEM_PFN;
可以看到在内存初始化阶段计算最大页面数量时,限制了最大范围,-PAGE_OFFSET=-0xC0000000=1G对应系统空间虚存空间的最大值,再减预留的VMALLOC_RESERVE就是实际normal范围的最大值,超过这个区间就被成为high memory,是不能直接线性映射的。
vmalloc的定义在include/linux/vmalloc.h中:
/*
* Allocate any pages
*/
static inline void * vmalloc (unsigned long size)
{
return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
}
参数gfp_mask被定义为GFP_KERNEL | __GFP_HIGHMEM,表示是kernel并且需要从highmem获取内存。
void * __vmalloc (unsigned long size, int gfp_mask, pgprot_t prot)
{
void * addr;
struct vm_struct *area;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > num_physpages) {
BUG();
return NULL;
}
area = get_vm_area(size, VM_ALLOC);
if (!area)
return NULL;
addr = area->addr;
if (vmalloc_area_pages(VMALLOC_VMADDR(addr), size, gfp_mask, prot)) {
vfree(addr);
return NULL;
}
return addr;
}
经过平平无奇的长度对齐和参数检查以后,迎来第一个高潮get_vm_area获取虚存空间:
struct vm_struct * get_vm_area(unsigned long size, unsigned long flags)
{
unsigned long addr;
struct vm_struct **p, *tmp, *area;
area = (struct vm_struct *) kmalloc(sizeof(*area), GFP_KERNEL);
if (!area)
return NULL;
size += PAGE_SIZE;
addr = VMALLOC_START;
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) ; p = &tmp->next) {
if ((size + addr) < addr) {
write_unlock(&vmlist_lock);
kfree(area);
return NULL;
}
if (size + addr < (unsigned long) tmp->addr)
break;
addr = tmp->size + (unsigned long) tmp->addr;
if (addr > VMALLOC_END-size) {
write_unlock(&vmlist_lock);
kfree(area);
return NULL;
}
}
area->flags = flags;
area->addr = (void *)addr;
area->size = size;
area->next = *p;
*p = area;
write_unlock(&vmlist_lock);
return area;
}
首先我们需要一个虚拟区间的控制结构,这个控制结构功能上类似供进程使用的vm_area_struct,但实际要简单很多,内核为自己维护一个虚存区间队列vmlist,链接了一串vm_struct结构。
struct vm_struct {
unsigned long flags;
void * addr;
unsigned long size;
struct vm_struct * next;
};
这个结构仅供内核使用,并且由于它是一个很小块的内存需求,所以我们采用kmalloc来申请,kmalloc从通用的slab缓冲对列中申请内存。
/* Just any arbitrary offset to the start of the vmalloc VM area: the
* current 8MB value just means that there will be a 8MB "hole" after the
* physical memory until the kernel virtual memory starts. That means that
* any out-of-bounds memory accesses will hopefully be caught.
* The vmalloc() routines leaves a hole of 4kB between each vmalloced
* area for the same reason. ;)
*/
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long) high_memory + 2*VMALLOC_OFFSET-1) & \
~(VMALLOC_OFFSET-1))
#define VMALLOC_VMADDR(x) ((unsigned long)(x))
#define VMALLOC_END (FIXADDR_START)
文件include/asm-i386/pgtable.h中定义了vmalloc的起始地址,至于为什么要加上一个8M的偏移,注释作出了解释,为了捕获所有的越界,在开头加了8M的空洞,并在每个vmalloc的区间加了一个4K也就是一页的空洞,所以get_vm_area的开头才会给size加上一个page_size.
get_vm_area的for循环在vmlist中查找一个足够大能装下size的空洞,同时将addr赋值为空洞的开头,找到后将新分配的area链接入vmlist,并返回area。
搞定虚存空间了还要搞物理页面并且建立映射:
inline int vmalloc_area_pages (unsigned long address, unsigned long size,
int gfp_mask, pgprot_t prot)
{
pgd_t * dir;
unsigned long end = address + size;
int ret;
dir = pgd_offset_k(address);
flush_cache_all();
lock_kernel();
do {
pmd_t *pmd;
pmd = pmd_alloc_kernel(dir, address);
ret = -ENOMEM;
if (!pmd)
break;
ret = -ENOMEM;
if (alloc_area_pmd(pmd, address, end - address, gfp_mask, prot))
break;
address = (address + PGDIR_SIZE) & PGDIR_MASK;
dir++;
ret = 0;
} while (address && (address < end));
unlock_kernel();
flush_tlb_all();
return ret;
}
首先通过一个内核专有的pgd_offset_k来获取虚拟地址对应的页面目录,他与给进程提供的结构唯一不同之处在于指定了mm_struct的变量为init_mm,也就是kernel进程的描述结构
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(address) pgd_offset(&init_mm, address)
然后在一个do-while循环中分配并初始化pmd,pte,一直到address大于等于end,也就一个设完事了。alloc_area_pmd分配和初始化中间目录,只是对于两层结构,pmd直接指向pgd,所以循环只会执行一次,并且分配页表所需页面的pte_alloc_kernel函数也是真刀实枪的开干了。
static inline int alloc_area_pmd(pmd_t * pmd, unsigned long address, unsigned long size, int gfp_mask, pgprot_t prot)
{
unsigned long end;
address &= ~PGDIR_MASK;
end = address + size;
if (end > PGDIR_SIZE)
end = PGDIR_SIZE;
do {
pte_t * pte = pte_alloc_kernel(pmd, address);
if (!pte)
return -ENOMEM;
if (alloc_area_pte(pte, address, end - address, gfp_mask, prot))
return -ENOMEM;
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while (address < end);
return 0;
}
alloc_area_pte去伙伴系统给页表项分配地址空间,并且设置页表项,建立映射。
static inline int alloc_area_pte (pte_t * pte, unsigned long address,
unsigned long size, int gfp_mask, pgprot_t prot)
{
unsigned long end;
address &= ~PMD_MASK;
end = address + size;
if (end > PMD_SIZE)
end = PMD_SIZE;
do {
struct page * page;
if (!pte_none(*pte))
printk(KERN_ERR "alloc_area_pte: page already exists\n");
page = alloc_page(gfp_mask);
if (!page)
return -ENOMEM;
set_pte(pte, mk_pte(page, prot));
address += PAGE_SIZE;
pte++;
} while (address < end);
return 0;
}
vfree整个就是vmalloc的反过程,完全对称的。
页面的换入换出
当系统页面不足时,内核可以通过将不活跃的页面写出到交换设备上,得以腾出一部分内存空间出来,交换设备(磁盘或者文件)上的的每个页面也在内存中有对应的描述,只不过它只是一个简单的计数,来表示盘上页面是否被分配以及他的使用计数。一个交换设别的描述结构被定义在include/linux/swap.h中:
struct swap_info_struct {
unsigned int flags;
kdev_t swap_device;
spinlock_t sdev_lock;
struct dentry * swap_file;
struct vfsmount *swap_vfsmnt;
unsigned short * swap_map;
unsigned int lowest_bit;
unsigned int highest_bit;
unsigned int cluster_next;
unsigned int cluster_nr;
int prio; /* swap priority */
int pages;
unsigned long max;
int next; /* next entry on swap list */
};
其中swap_map指向一个数组,数组中的每个元素即代表盘上的一个页面,而数组的下标则决定了页面在交换设备的位置,元素的大小表示这个页面的使用计数,如果是0表示这个页面还没有被分配。数组的大小取决于pages,它表示设备的大小。
交换设备上的第一个页面swap_map[0]所代表的页面不参与页面交换,它包含设备的一些信息,以及一个表示哪些设备可以使用的位图。
lowest_bit和highest_bit表明了交换设备上用于页面交换的页面的范围,max是设备上的最大编号。
由于磁盘的特性,在分配盘上页面的时候尽可能的使用集群的方式进行,cluster_next和cluster_nr就是为此设置的。
struct swap_list_t swap_list = {-1, -1};
struct swap_info_struct swap_info[MAX_SWAPFILES];
内核可以有多个交换设备,他们的描述结构都存储在swap_info数组中,同时每新加一个交换设备,都会将他的结构链入swap_list中。
当内存中的页面被交换到盘上以后,用于映射的页表项的含义将发生变化
typedef struct {
unsigned long val;
} swp_entry_t;
实际上只是一个32位的整数,分为3部分
offset type p
+--------------------+----------+----+
| | | |
+--------------------+----------+----+
只有p=0时,页表项的内容才解释为swp_entry_t,offset表示在页面在盘上的位置,也就是swap_map的下标,type是在哪个文件中,也就是swap_info的下标。
物理页面的page数据结构中有几个关键的成员是为页面交换服务的,其中mapping指向一个结构address_space:
include/linux/fs.h
struct address_space {
struct list_head clean_pages; /* list of clean pages */
struct list_head dirty_pages; /* list of dirty pages */
struct list_head locked_pages; /* list of locked pages */
unsigned long nrpages; /* number of total pages */
struct address_space_operations *a_ops; /* methods */
struct inode *host; /* owner: inode, block_device */
struct vm_area_struct *i_mmap; /* list of private mappings */
struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
spinlock_t i_shared_lock; /* and spinlock protecting it */
};
结构中有三个队列,分别管理着干净的(已经写出到磁盘),脏的(未换出),和暂时锁定不让换出的页面,所有即将要换入换出的页面都将被加入到这三个暂存队列中。
page结构的lru将其链入某个lru队列,可以是全局的inactive_dirty_list,每个管理区都有一个的inactive_clean_list(很有可能被恢复映射)或者active_list。
页面换出之前在inactive_dirty_list,换出后又不想立即释放(有被重新访问恢复的可能)所以在inactice_clean_list,每有一个进程的管理区中有这个页面则其对应的盘上页面使用计数加一,active队列中的页面正在使用,其页面的使用计数降到0时,挪入对应的不活跃队列。
页面的定期换出
内核设置了一个kswapd线程,专门负责定期的将页面换出,kswap的代码基本都在mm/vmscan.c中,先看他的建立:
static int __init kswapd_init(void)
{
printk("Starting kswapd v1.8\n");
swap_setup();
kernel_thread(kswapd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
kernel_thread(kreclaimd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
return 0;
}
module_init(kswapd_init)
这个函数在系统初始化阶段,由do_initcalls调用,主要完成两件事,一是在swap_setup中根据内存的大小设置一个全局的page_cluster:
/*
* Perform any setup for the swap system
*/
void __init swap_setup(void)
{
/* Use a smaller cluster for memory <16MB or <32MB */
if (num_physpages < ((16 * 1024 * 1024) >> PAGE_SHIFT))
page_cluster = 2;
else if (num_physpages < ((32 * 1024 * 1024) >> PAGE_SHIFT))
page_cluster = 3;
else
page_cluster = 4;
}
首先读取磁盘需要寻道,很耗时,所以经济的做法是一次多读几个,那就意味着要多暂存几个页面,而一次读多少个则通过物理内存本身的大小来确定。
二是建立两个线程,kswapd和kreclaimd,一个用来交换页面,一个用来回收干净的页面并回收至伙伴系统的空闲队列。
kswapd
/*
* The background pageout daemon, started as a kernel thread
* from the init process.
*
* This basically trickles out pages so that we have _some_
* free memory available even if there is no other activity
* that frees anything up. This is needed for things like routing
* etc, where we otherwise might have all activity going on in
* asynchronous contexts that cannot page things out.
*
* If there are applications that are active memory-allocators
* (most normal use), this basically shouldn't matter.
*/
int kswapd(void *unused)
{
struct task_struct *tsk = current;
tsk->session = 1;
tsk->pgrp = 1;
strcpy(tsk->comm, "kswapd");
sigfillset(&tsk->blocked);
kswapd_task = tsk;
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get access to it
* regardless (see "__alloc_pages()"). "kswapd" should
* never get caught in the normal page freeing logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to be able to
* page out something else, and this flag essentially protects
* us from recursively trying to free more memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC;
/*
* Kswapd main loop.
*/
for (;;) {
static int recalc = 0;
/* If needed, try to free some memory. */
if (inactive_shortage() || free_shortage()) {
int wait = 0;
/* Do we need to do some synchronous flushing? */
if (waitqueue_active(&kswapd_done))
wait = 1;
do_try_to_free_pages(GFP_KSWAPD, wait);
}
/*
* Do some (very minimal) background scanning. This
* will scan all pages on the active list once
* every minute. This clears old referenced bits
* and moves unused pages to the inactive list.
*/
refill_inactive_scan(6, 0);
/* Once a second, recalculate some VM stats. */
if (time_after(jiffies, recalc + HZ)) {
recalc = jiffies;
recalculate_vm_stats();
}
/*
* Wake up everybody waiting for free memory
* and unplug the disk queue.
*/
wake_up_all(&kswapd_done);
run_task_queue(&tq_disk);
/*
* We go to sleep if either the free page shortage
* or the inactive page shortage is gone. We do this
* because:
* 1) we need no more free pages or
* 2) the inactive pages need to be flushed to disk,
* it wouldn't help to eat CPU time now ...
*
* We go to sleep for one second, but if it's needed
* we'll be woken up earlier...
*/
if (!free_shortage() || !inactive_shortage()) {
interruptible_sleep_on_timeout(&kswapd_wait, HZ);
/*
* If we couldn't free enough memory, we see if it was
* due to the system just not having enough memory.
* If that is the case, the only solution is to kill
* a process (the alternative is enternal deadlock).
*
* If there still is enough memory around, we just loop
* and try free some more memory...
*/
} else if (out_of_memory()) {
oom_kill();
}
}
}
kswapd是一个死循环,每次循环到最后会通过interruptible_sleep_on_timeout()进入睡眠,让内核可以调度执行其他的进程,并在1s(HZ)后醒来,这样以1s位周期定期的执行换入换出任务。
首先如果系统已经进入页面短缺的状态(inactive_shortage() || free_shortage()),执行do_try_to_free_pages设法释放和换出若干页面。
static int do_try_to_free_pages(unsigned int gfp_mask, int user)
{
int ret = 0;
/*
* If we're low on free pages, move pages from the
* inactive_dirty list to the inactive_clean list.
*
* Usually bdflush will have pre-cleaned the pages
* before we get around to moving them to the other
* list, so this is a relatively cheap operation.
*/
if (free_shortage() || nr_inactive_dirty_pages > nr_free_pages() +
nr_inactive_clean_pages())
ret += page_launder(gfp_mask, user);
/*
* If needed, we move pages from the active list
* to the inactive list. We also "eat" pages from
* the inode and dentry cache whenever we do this.
*/
if (free_shortage() || inactive_shortage()) {
shrink_dcache_memory(6, gfp_mask);
shrink_icache_memory(6, gfp_mask);
ret += refill_inactive(gfp_mask, user);
} else {
/*
* Reclaim unused slab cache memory.
*/
kmem_cache_reap(gfp_mask);
ret = 1;
}
return ret;
}
首先如果页面短缺且不活跃脏页面够多,就尝试把脏的页面洗干净,使他们变成可立即分配的页面
int page_launder(int gfp_mask, int sync)
{
...
can_get_io_locks = gfp_mask & __GFP_IO;
launder_loop = 0;
maxlaunder = 0;
cleaned_pages = 0;
dirty_page_rescan:
spin_lock(&pagemap_lru_lock);
maxscan = nr_inactive_dirty_pages;
while ((page_lru = inactive_dirty_list.prev) != &inactive_dirty_list &&
maxscan-- > 0) {
page = list_entry(page_lru, struct page, lru);
/* Wrong page on list?! (list corruption, should not happen) */
if (!PageInactiveDirty(page)) {
...
}
/* Page is or was in use? Move it to the active list. */
if (PageTestandClearReferenced(page) || page->age > 0 ||
(!page->buffers && page_count(page) > 1) ||
...
}
if (TryLockPage(page)) {
...
}
if (PageDirty(page)) {
...
}
if (page->buffers) {
...
} else if (page->mapping && !PageDirty(page)) {
...
} else {
page_active:
del_page_from_inactive_dirty_list(page);
add_page_to_active_list(page);
UnlockPage(page);
}
}
spin_unlock(&pagemap_lru_lock);
if (can_get_io_locks && !launder_loop && free_shortage()) {
launder_loop = 1;
/* If we cleaned pages, never do synchronous IO. */
if (cleaned_pages)
sync = 0;
/* We only do a few "out of order" flushes. */
maxlaunder = MAX_LAUNDER;
/* Kflushd takes care of the rest. */
wakeup_bdflush(0);
goto dirty_page_rescan;
}
/* Return the number of pages moved to the inactive_clean list. */
return cleaned_pages;
}
page_launder通过一个循环遍历不活跃脏页面队列里面的所有页面,排除掉不应该在这个队列里的页面和被锁定的页面以外,还有四种页面处理:
1、页面是脏的
2、页面不再是脏的,但被用作文件读写缓冲页面
3、页面是干净的
4、不知道是啥
下面依次看各种页面是怎么处理的
1、不活跃的脏的页面
/*
* Dirty swap-cache page? Write it out if
* last copy..
*/
if (PageDirty(page)) {
int (*writepage)(struct page *) = page->mapping->a_ops->writepage;
int result;
if (!writepage)
goto page_active;
/* First time through? Move it to the back of the list */
if (!launder_loop) {
list_del(page_lru);
list_add(page_lru, &inactive_dirty_list);
UnlockPage(page);
continue;
}
/* OK, do a physical asynchronous write to swap. */
ClearPageDirty(page);
page_cache_get(page);
spin_unlock(&pagemap_lru_lock);
result = writepage(page);
page_cache_release(page);
/* And re-start the thing.. */
spin_lock(&pagemap_lru_lock);
if (result != 1)
continue;
/* writepage refused to do anything */
set_page_dirty(page);
goto page_active;
}
如果页面的writepage没有定义,则页面无法换出,将页面当作活跃页面处理,直接跳转到page_active处将页面移至活跃页面队列。
可以换出的页面分两趟处理(launder_loop),第一趟直接将页面放在队列的结尾,等下一趟再处理;第二趟,将页面洗干净,调用writepage将页面写入磁盘,写入失败的话,页面恢复脏的状态并转入活跃页面队列。
洗干净的页面继续向下执行,属于2,3,4哪种页面。
2、页面不再是脏的,但被用作文件读写缓冲页面
if (page->buffers) {
int wait, clearedbuf;
int freed_page = 0;
/*
* Since we might be doing disk IO, we have to
* drop the spinlock and take an extra reference
* on the page so it doesn't go away from under us.
*/
del_page_from_inactive_dirty_list(page);
page_cache_get(page);
spin_unlock(&pagemap_lru_lock);
/* Will we do (asynchronous) IO? */
if (launder_loop && maxlaunder == 0 && sync)
wait = 2; /* Synchrounous IO */
else if (launder_loop && maxlaunder-- > 0)
wait = 1; /* Async IO */
else
wait = 0; /* No IO */
/* Try to free the page buffers. */
clearedbuf = try_to_free_buffers(page, wait);
/*
* Re-take the spinlock. Note that we cannot
* unlock the page yet since we're still
* accessing the page_struct here...
*/
spin_lock(&pagemap_lru_lock);
/* The buffers were not freed. */
if (!clearedbuf) {
add_page_to_inactive_dirty_list(page);
/* The page was only in the buffer cache. */
} else if (!page->mapping) {
atomic_dec(&buffermem_pages);
freed_page = 1;
cleaned_pages++;
/* The page has more users besides the cache and us. */
} else if (page_count(page) > 2) {
add_page_to_active_list(page);
/* OK, we "created" a freeable page. */
} else /* page->mapping && page_count(page) == 2 */ {
add_page_to_inactive_clean_list(page);
cleaned_pages++;
}
/*
* Unlock the page and drop the extra reference.
* We can only do it here because we ar accessing
* the page struct above.
*/
UnlockPage(page);
page_cache_release(page);
/*
* If we're freeing buffer cache pages, stop when
* we've got enough free memory.
*/
if (freed_page && !free_shortage())
break;
continue;
首先页面脱离不活跃脏队列,引用计数+1,并调用try_to_free_buffers试图释放页面,如果不能释放则根据返回值将页面退回不活跃脏队列,或转入活跃页面队列或不活跃干净队列。如果释放成功,则page_cache_release使页面计数-1达到0。如果成功释放了页面或者发现空闲页面不在短缺,则结束遍历,否则继续下一个。
3、页面是干净的
} else if (page->mapping && !PageDirty(page)) {
/*
* If a page had an extra reference in
* deactivate_page(), we will find it here.
* Now the page is really freeable, so we
* move it to the inactive_clean list.
*/
del_page_from_inactive_dirty_list(page);
add_page_to_inactive_clean_list(page);
UnlockPage(page);
cleaned_pages++;
}
直接将页面转到不活跃干净队列
4、不知道是啥的
} else {
page_active:
/*
* OK, we don't know what to do with the page.
* It's no use keeping it here, so we move it to
* the active list.
*/
del_page_from_inactive_dirty_list(page);
add_page_to_active_list(page);
UnlockPage(page);
}
当活跃页面处理,转入活跃页面队列。
回头看do_try_to_free_pages,若在page_launder后依然页面短缺
if (free_shortage() || inactive_shortage()) {
shrink_dcache_memory(6, gfp_mask);
shrink_icache_memory(6, gfp_mask);
ret += refill_inactive(gfp_mask, user);
} else {
/*
* Reclaim unused slab cache memory.
*/
kmem_cache_reap(gfp_mask);
ret = 1;
}
则通过三个函数的调用试图回收一些活跃的页面到不活跃页面列表。
shrink_dcache_memory,shrink_icache_memory是为了文件系统在打开文件时分配的内存,这里暂不讨论,kmem_cache_reap是不论页面短缺与否都要定期的收割slab缓冲队列使用的页面。
集中看一下refill_inactive:
/*
* We need to make the locks finer granularity, but right
* now we need this so that we can do page allocations
* without holding the kernel lock etc.
*
* We want to try to free "count" pages, and we want to
* cluster them so that we get good swap-out behaviour.
*
* OTOH, if we're a user process (and not kswapd), we
* really care about latency. In that case we don't try
* to free too many pages.
*/
static int refill_inactive(unsigned int gfp_mask, int user)
{
int priority, count, start_count, made_progress;
count = inactive_shortage() + free_shortage();
if (user)
count = (1 << page_cluster);
start_count = count;
/* Always trim SLAB caches when memory gets low. */
kmem_cache_reap(gfp_mask);
priority = 6;
do {
made_progress = 0;
if (current->need_resched) {
__set_current_state(TASK_RUNNING);
schedule();
}
while (refill_inactive_scan(priority, 1)) {
made_progress = 1;
if (--count <= 0)
goto done;
}
/*
* don't be too light against the d/i cache since
* refill_inactive() almost never fail when there's
* really plenty of memory free.
*/
shrink_dcache_memory(priority, gfp_mask);
shrink_icache_memory(priority, gfp_mask);
/*
* Then, try to page stuff out..
*/
while (swap_out(priority, gfp_mask)) {
made_progress = 1;
if (--count <= 0)
goto done;
}
/*
* If we either have enough free memory, or if
* page_launder() will be able to make enough
* free memory, then stop.
*/
if (!inactive_shortage() || !free_shortage())
goto done;
/*
* Only switch to a lower "priority" if we
* didn't make any useful progress in the
* last loop.
*/
if (!made_progress)
priority--;
} while (priority >= 0);
/* Always end on a refill_inactive.., may sleep... */
while (refill_inactive_scan(0, 1)) {
if (--count <= 0)
goto done;
}
done:
return (count < start_count);
}
实现了把活跃的寿命耗尽的页面断开映射,把表示页面去向的swp_entry_t写入页表项,并将该页面加入交换缓冲队列,并链入不活跃脏页面队列的功能
1、refill_inactive_scan负责将活跃的寿命耗尽且没有映射的页面添加至当前管理区的不活跃干净页面队列
2、swap_out负责查找占用内存页面最多的进程,并将其页表目录中活跃的寿命耗尽的页面解除映射,并获取交换设备上的页面,将这个去向构造成swp_entry_t写入页表项,并将page添加至当前管理区的不活跃干净页面队列















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









